Karpathy Declares the End of Manual Coding as Agent Memory Wars Heat Up
Andrej Karpathy's wide-ranging interview on the No Priors podcast dominated discussion, declaring he hasn't typed code since December and outlining a future where humans direct autonomous agents. Meanwhile, a fierce debate emerged around agent memory architectures, with Hermes and OpenClaw representing two fundamentally different philosophies. The community also grappled with agent code quality problems, with Factory AI and others proposing lint-driven development as a solution.
Daily Wrap-Up
The AI developer community spent March 21st digesting a sprawling Karpathy interview that touched on everything from "AI psychosis" (the anxiety of unused tokens) to the claim that software engineering has permanently shifted from writing code to expressing intent. Whether you buy the maximalist framing or not, the signal underneath is real: the conversation has moved decisively from "can agents code?" to "how do we manage agents that code?" The practical questions dominating the timeline weren't about model capabilities but about memory management, code quality guardrails, and orchestration patterns.
The memory architecture debate is particularly worth watching. Two competing philosophies are crystallizing: stuff everything into context (OpenClaw style) versus keep the prompt minimal and retrieve on demand (Hermes style). The tradeoffs are stark and measurable, with one user reporting 5-second versus 60-second response times. This isn't an abstract design choice; it's the kind of architectural decision that compounds over weeks of agent usage. Meanwhile, Karpathy himself admitted that agents ignore his AGENTS.md instructions and produce bloated code, which Factory AI used as a springboard to promote lint-driven development and codebase "agent readiness" as necessary prerequisites. The tension between agent autonomy and code quality is becoming the defining challenge of this era.
The most practical takeaway for developers: if you're running persistent coding agents, audit your memory architecture now. The difference between a lean retrieval-based approach and an ever-growing context window isn't just speed; it's the difference between an agent that stays coherent over weeks and one that degrades as it accumulates history. Start with Hermes-style minimal prompts and search-on-demand, and only expand your persistent context when you can prove the tradeoff is worth it.
Quick Hits
- OpenAI's Codex for Students: @OpenAIDevs is offering $100 in Codex credits to U.S. and Canadian college students, with @gdb boosting the announcement. A smart acquisition play targeting the next generation of developers.
- Tenstorrent office visit: @TheAhmadOsman shared photos from a Tenstorrent office tour, highlighting the AI accelerator hardware company's work.
- Elon on Von Neumann probes: @elonmusk floated Optimus+PV as "the first Von Neumann probe," a self-replicating machine using space raw materials. Filed under: ambitious timelines.
- Energy tech meets AI: @ashebytes posted a conversation with Danielle Fong covering the intersection of frontier energy technology, data center power demands, and agentic tooling at Lightcell.
- Cloudways Copilot: @Cloudways promoted AI-powered managed hosting, another signal that AI copilot features are becoming table stakes across infrastructure products.
- Browser Use CLI 2.0: @shawn_pana praised the new Browser Use CLI, claiming he hasn't touched Chrome manually while working with Claude Code. @browser_use touts 2x speed at half the cost using direct CDP.
Agent Memory Architecture: The Great Divergence
The hottest technical debate of the day centered on how AI agents should handle memory, and two sharply different philosophies are now competing for developer mindshare. @witcheer provided a detailed firsthand comparison after running both OpenClaw and Hermes on the same Mac Mini, distilling the core difference to a single sentence: "OpenClaw stores everything and searches it. Hermes keeps almost nothing in the prompt and retrieves the rest on demand."
The Hermes approach uses four memory layers, but the key insight is restraint. Its core context is roughly 1,300 tokens of curated facts, with everything else living in a SQLite archive queried only when needed. As @witcheer put it: "Hermes would rather search for a fact at the cost of one tool call than stuff it into every single message and break the cache." The performance difference was dramatic in practice: "my OpenClaw bot was 2 months of accumulated memory, deep context, but every message replays more history. Hermes is 2 weeks old with a fraction of the memory, but it responds in 5 seconds vs 60."
This dovetails with @tricalt's piece on "Memory as a Harness: Turning Execution Into Learning," which argues that the missing layer in agent development is the system around the intelligence. The article's premise, that models alone cannot give us learning systems, aligns perfectly with the Hermes philosophy: memory isn't about accumulation, it's about structured retrieval. For developers building with persistent agents, the lesson is clear. Cache-friendly, minimal prompts with on-demand retrieval will outperform brute-force context stuffing every time. The question isn't whether your agent remembers everything; it's whether it knows how to find what it needs.
Karpathy's Vision: Directors, Not Doers
Andrej Karpathy's appearance on the No Priors podcast generated the day's longest discussion thread, with @kloss_xyz providing a detailed 10-point breakdown. The headline claim, "I don't think I've typed a line of code since December," set the tone for a conversation about the permanent restructuring of software engineering workflows.
Several of Karpathy's points landed with particular force. His concept of "AI psychosis," the anxiety of knowing you have unused tokens sitting idle, resonated as a genuine new cognitive phenomenon in the developer community. His observation that "the limits aren't model capability anymore, they're orchestration skill" reinforced what many practitioners are discovering independently. And his prediction about specialized model ecosystems ("a team of focused models beats one mega model every time") challenges the scaling-maximalist narrative that still dominates some corners of AI discourse.
But perhaps the most grounded insight was about jobs data. Karpathy looked at real employment numbers and concluded that engineering demand is still rising, comparing cheaper AI-assisted engineering to how ATMs actually created more bank teller jobs by enabling more branch locations. The framing of humans as "directors, not doers" is provocative, but the economic data he cites suggests this is additive rather than replacement. For developers feeling anxious about relevance, Karpathy's message is that orchestration skill is the new leverage point, and there's more demand for it than ever.
The Agent Code Quality Problem
While the industry celebrates agent productivity, a candid admission from Karpathy himself exposed the elephant in the room. In a post quoted by @alvinsng, Karpathy wrote: "I'm not very happy with the code quality and I think agents bloat abstractions, have poor code aesthetics, are very prone to copy pasting code blocks." He noted that agents consistently ignore his style instructions, creating complex one-liners that call multiple functions and index arrays in a single expression despite explicit guidance to do otherwise.
@alvinsng and the @FactoryAI team positioned their work as a direct response to this problem, advocating for what they call "Lint Driven Development" (LDD): "Using Linters to direct agents... Agent Readiness (Fixing the codebase before letting agents roam wild)." Their thesis is that you need to prepare your codebase before unleashing agents, through banned patterns (like React's useEffect), linter rules that agents can follow more reliably than prose instructions, and context compression for long sessions. The approach treats the codebase itself as the instruction set rather than relying on markdown files that agents may or may not respect. It's a pragmatic admission that natural language constraints are insufficient for maintaining code quality at scale, and that mechanical enforcement through existing tooling is the path forward.
Agentic Methods and the Harness Debate
A cluster of posts explored the proliferating landscape of agent architectures and orchestration approaches. @neural_avb walked through how different agentic methods solve the same problem, from direct prompting through RAGs, ReAct, CodeAct, subagents, and Recursive Language Models, providing a useful taxonomy for developers trying to navigate the options. Meanwhile, @joemccann sparked debate about open versus closed agent harnesses, arguing that open source will win despite Anthropic's "walled garden" approach with Claude Code.
The quoted post from @_can1357 that catalyzed the harness discussion made a striking claim: "I improved 15 LLMs at coding in one afternoon. Only the harness changed." This frames the current competitive landscape not as a model race but as an orchestration race. @doodlestein reinforced this with his concept of "in-context recursive self-improvement," where learnings from agent sessions feed back into the skills agents use: "It doesn't take many iterations before you can start doing really extraordinary things." @mattshumer_ also weighed in with claims about a "simple setup change" that dramatically improves coding agent performance. Whether these individual claims hold up, the meta-pattern is consistent: the returns on better orchestration currently exceed the returns on better models.
Claude Code Updates
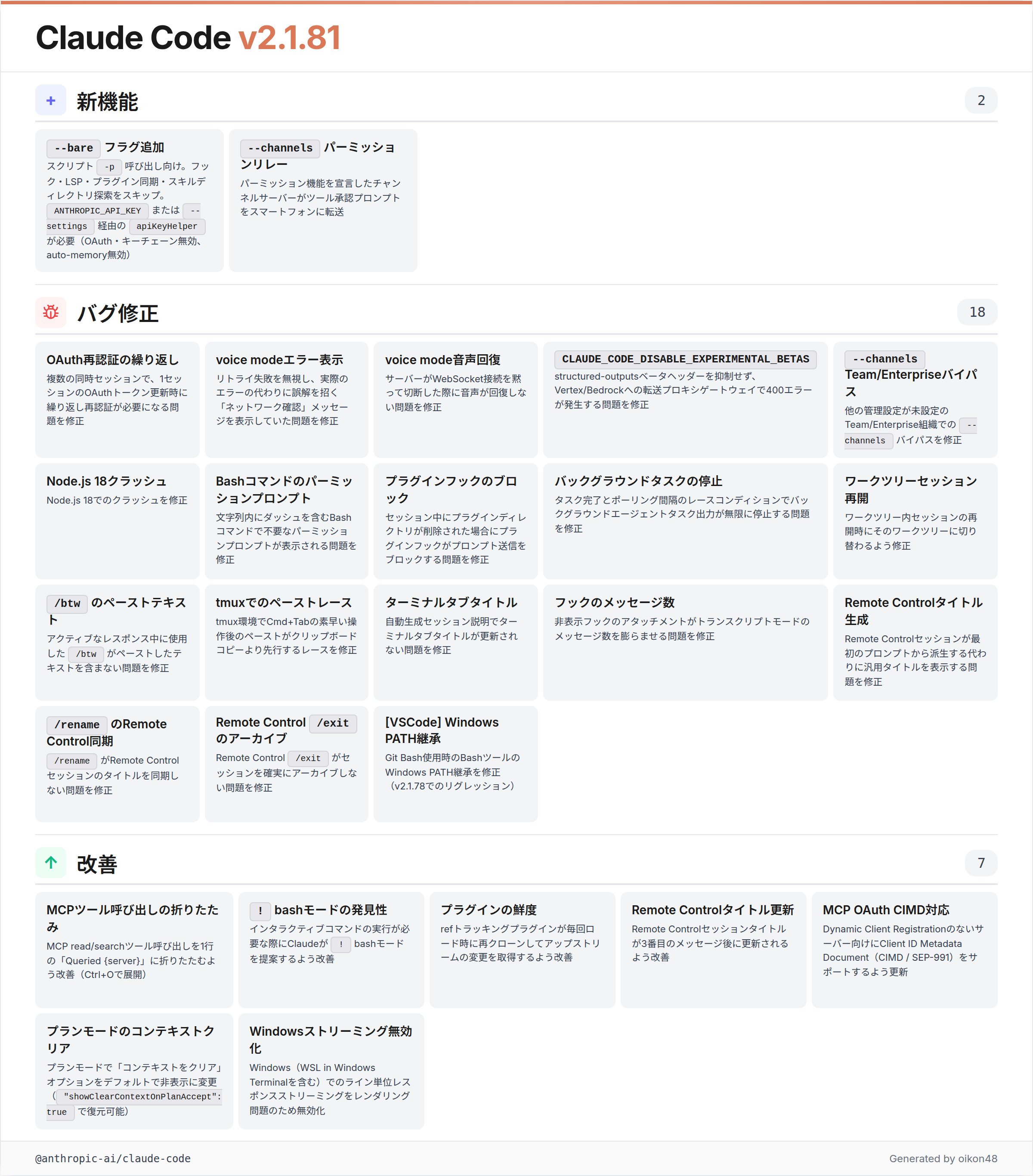
@oikon48 shared detailed release notes for Claude Code 2.1.81, covering a range of improvements including a new --bare flag for scripted -p usage that skips hooks, LSP, and plugin scanning for leaner automation pipelines. The update also adds --channels for permission relay (enabling tool approvals from mobile), fixes for worktree session resumption, and collapsed MCP read/search output. These are incremental but meaningful quality-of-life improvements, particularly for developers running Claude Code in automated or multi-device workflows.
Sources
C
Experience AI-powered managed hosting with Cloudways Copilot. https://t.co/U5ikoe4SGL
A
was invited to the Tenstorrent office yesterday, enjoyed hearing about all the things they’re working on & saw some really cool hardware https://t.co/wPmerS1AjL




W
I ran both OpenClaw and Hermes on the same mac mini. this breakdown is accurate and worth reading if you're building with either.
the core difference in one sentence: OpenClaw stores everything and searches it. Hermes keeps almost nothing in the prompt and retrieves the rest on demand.
to be more specific, Hermes has 4 memory layers:
→ MEMORY.md + USER.md: ~1,300 tokens of curated facts. that's it. deliberately tiny so the prompt stays stable and cache-friendly
→ session_search: full SQLite archive of past conversations with FTS5 search. only queried when needed, never injected by default
→ skills: procedural memory. when the agent solves something hard, it saves how it did it, not what happened, but how to do it again
→ honcho (optional): cross-session user modeling that attaches to the current turn without mutating the cached prompt
Hermes would rather search for a fact at the cost of one tool call than stuff it into every single message and break the cache.
I've seen this tradeoff firsthand. my OpenClaw bot was 2 months of accumulated memory, deep context, but every message replays more history. hermes is 2 weeks old with a fraction of the memory, but it responds in 5 seconds vs 60 because it's not dragging its entire life story into every turn.
in @NousResearch we trust.
M
manthanguptaa
@manthanguptaa
I Read Hermes Agent's Memory System, and It Fixes What OpenClaw Got Wrong
A
On frontier science: stepping into the golden age of energy tech
In conversation with Danielle Fong @daniellefong
00:45 Danielle’s background, starting with college at 12
04:16 The global energy crisis
11:15 Productizing: from drones to data centers
14:00 Powering your future openclaw with propane
14:34 US gov vs consumer applications
19:30 AI, data centers, and new energy sources
23:25 Agentic tools at Lightcell
27:54 Leveraging models across providers
29:54 Iterating on frontier science
43:22 Hyperscalers and the golden age of energy tech

O
Meet Codex for Students.
We're offering college students in the U.S. and Canada $100 in Codex credits.
Our goal is to support students to learn by building, breaking, and fixing things.
https://t.co/WrOtW8E8Lk https://t.co/l2T81LgKCI

V
Memory as a Harness: Turning Execution Into Learning
Memory as a Harness: Turning Execution Into Learning
"The missing layer that makes agents actually improve over time." Earlier this month the industry woke up: models can give us intelligence, but they ...
M
Most people are using coding agents completely wrong.
There's a simple setup change that makes them dramatically better.
And once you switch to it, you'll never go back.
Here's the full breakdown + the starter prompt to copy.
Trust me, you NEED to try this.
M
mattshumer_
@mattshumer_
10x Your Coding Agent Productivity
A
This article contains just one very simple example.
And explains how different agentic methods solve it...
- Direct Prompting
- RAGs
- ReAct/tool calling
- CodeAct
- CodeAct + Subagents
- And, RLMs
You might wanna read the full article if your eyes made it to this line.
N
neural_avb
@neural_avb
Recursive Language Models - what finally gave me the 'aha' moment
O
RT @neural_avb: https://t.co/QeozQY6lRH
O
Claude Code 2.1.81 (抜粋)
・スクリプト向けの -p に --bare を追加。フック・LSP・プラグイン同期・スキルディレクトリの走査は行わない。API キーは ANTHROPIC_API_KEY か、--settings の apiKeyHelper が必須(OAuth とキーチェーンは使えない)。自動メモリはオフのまま
・--channels で権限の中継ができるように。権限機能を出しているチャネルサーバーから、ツール承認をスマホへ送れる
・文字列の中にハイフンがある Bash コマンドで、余計な権限確認が出る問題を修正
・ワークツリーで開いていたセッションを再開したら、そのワークツリーに戻るように変更
・応答の最中に /btw を使ったとき、貼った内容が入らない問題を修正
・MCP の read/search は「Queried {server}」の 1 行にまとめて表示(Ctrl+O で詳細)
・対話が必要なコマンドのとき、! の bash モードを Claude が提案するようにした
・MCP の OAuth を更新。Dynamic Client Registration がないサーバー向けに CIMD(SEP-991)に対応
・プランモードでは「コンテキストをクリア」はデフォルトで隠す設定追加("showClearContextOnPlanAccept": true で戻せる)
・[VSCode] Git Bash 使い時、Bash ツールに Windows の PATH が渡らない問題を修正(v2.1.78 で壊れていた)
◢
If you want to understand why open source agent harnesses are going to win, read this post.
Sure, @AnthropicAI is going for the walled garden @Apple approach to force users to use “their” harness, but in order to win, they’ll need to entrench enterprises with Claude Code whilst making CC more “secure”, make switching costs too expensive, from career risk to engineering leadership to literal dollars.
_
_can1357
@_can1357
I improved 15 LLMs at coding in one afternoon. Only the harness changed.
S
I don’t think I could emphasize how good this CLI Is
Today, I’ve been working on a new project
I haven’t touched Chrome manually for it
Claude Code does everything for me
B
browser_use
@browser_use
Introducing: Browser Use CLI 2.0 🔥 The most efficient browser automation CLI tool > 2x the speed, half the cost > Easily connect to running Chrome > Uses direct CDP Try it now 🔗↓ https://t.co/9YZ2oB5wVz
A
Yup, we at @FactoryAI know this oh so well, which is why we’ve written about:
- Banning useEffect() in React codebases
- Using Linters to direct agents (I prefer calling it LDD: Lint Driven Development)
- Agent Readiness (Fixing the codebase before letting agents roam wild)
- Context compression, ensuring large sessions remain comprehensible
- Missions: The ultimate unlock for tackling complex, long-running tasks
All links below
K
karpathy
@karpathy
I'm not very happy with the code quality and I think agents bloat abstractions, have poor code aesthetics, are very prone to copy pasting code blocks and it's a mess, but at this point I stopped fighting it too hard and just moved on. The agents do not listen to my instructions in the AGENTS.md files. E.g. just as one example, no matter how many times I say something like: "Every line of code should do exactly one thing and use intermediate variables as a form of documentation" They will still "multitask" and create complex constructs where one line of code calls 2 functions and then indexes an array with the result. I think in principle I could use hooks or slash commands to clean this up but at some point just a shrug is easier. Yes I think LLM as a judge for soft rewards is in principle and long term slightly problematic (due to goodharting concerns), but in practice and for now I don't think we've picked the low hanging fruit yet here.
A
useEffect: https://t.co/CuCSq2ITQT
Linting: https://t.co/mlP17a6bZh
Agent readiness: https://t.co/u49aNGfCGT
Context compression: https://t.co/LyvPfRuUF2
Missions: https://t.co/YNtcXE29rc
A
alvinsng
@alvinsng
Why we banned React's useEffect
K
Karpathy just outlined the next era of AI.
all over 66 minutes… I broke down his 10 major takeaways so you don’t have to watch the full video (but you still probably should after reading this)
here’s what he said matters most….
→ “I don’t think I’ve typed a line of code since December.” the default workflow for software engineers has changed permanently since late 2025. we don’t write code anymore. we express intent to persistent AI agents for 16+ hours a day
→ he coined “AI psychosis”… the anxiety of knowing you have unused tokens just sitting there. success isn’t measured in your flops anymore. it’s measured in your token throughput
→ the limits aren’t model capability anymore. they’re orchestration skill. the people who know how to direct agents are operating 10x above everyone else using the same tools
let me walk through all of his points…
1. mastery looks different now
Karpathy built a personal agent called “Dobby” that controls his entire home through natural language. persistence + memory + parallel agents = a 2 person team operating like a 20 person org
2. software becomes disposable
humans don’t need custom apps anymore. the customer is no longer the human… it’s agents acting on behalf of humans. entire industries have to account for and refactor for this
3. AutoResearch changes everything
his side project (github .com/karpathy/autoresearch)… fully autonomous research loops. agents edit code, train models, and iterate overnight while you sleep. human only writes the high level goal
4. the skills that matter now
understand that an agent can be both a brilliant PhD level systems programmer and a 10 year old’s unformed mind in the same conversation. and your job is to overcome those challenges and direct your agents. everything else they’ll soon do better
5. specialized models > one giant brain
stop trying to build one know it all mega brain model. the future looks like an ecosystem… diverse adaptable and specialized models built for specific jobs. a team of focused models beats one mega model every time
6. distributed research could disrupt the lab monopoly
imagine thousands of smartphones and computers around the world running AI experiments at the same time… not owned by one company. results are easy to verify but hard to discover.
it’s how open collaboration could disrupt big closed labs
decentralized internet
7. jobs data says something completely different than the narrative
Karpathy looked at all the real data. engineering job demand is still rising. cheaper engineering creates MORE demand, not less. like how ATMs actually created more bank teller jobs
8. open source is the safety net
open models generally lag frontier by 6-8 months but they’re also essential. closed models carry systemic risk from over-centralization.
Karpathy wants ensembles of minds, not 2-3 labs behind closed doors making decisions for everyone
9. robotics will lag badly
the physical world is messy and capital intensive. digital transformation will be orders of magnitude faster.
future prediction… most AI agents will pay humans to act as their hands and eyes in the physical world, creating information markets for real world data to sell between themselves
10. education gets rebuilt from scratch
the core LLM training algorithm fits in about 200 lines of Python. the rest is bloat.
the new model? humans explain concepts to agents once, agents tutor humans infinitely and personally.
write documentation for agents first.
yes, a markdown first file world
his one liner that hits hardest for me…
“I put in just very few tokens… and a huge amount of stuff happens on my behalf”
we’re in the era of autonomous agents.
humans become directors, not doers.
the leverage is insane, but it’s only really available to people who learn how to use it properly
if you’re building with AI now, this is required listening material imo
the ones who move first?
they don’t ask permission
they just do it: master AI
S
saranormous
@saranormous
Caught up with @karpathy for a new @NoPriorsPod: on the phase shift in engineering, AI psychosis, claws, AutoResearch, the opportunity for a SETI-at-Home like movement in AI, the model landscape, and second order effects 02:55 - What Capability Limits Remain? 06:15 - What Mastery of Coding Agents Looks Like 11:16 - Second Order Effects of Coding Agents 15:51 - Why AutoResearch 22:45 - Relevant Skills in the AI Era 28:25 - Model Speciation 32:30 - Collaboration Surfaces for Humans and AI 37:28 - Analysis of Jobs Market Data 48:25 - Open vs. Closed Source Models 53:51 - Autonomous Robotics and Atoms 1:00:59 - MicroGPT and Agentic Education 1:05:40 - End Thoughts
J
This is truly the most alpha I can give people. If you can get this loop going for yourself and your use case, it doesn’t take many iterations before you can start doing really extraordinary things.
D
doodlestein
@doodlestein
It's also so powerful to take learnings from agent sessions where your custom CLI tools are used by agents and then feed them back into the skills the agents use to help them operate those tools. This is sort of "in-context recursive self-improvement" if you will, cyborg style: https://t.co/2auFrjre8I
R
RT @alvinsng: Yup, we at @FactoryAI know this oh so well, which is why we’ve written about:
- Banning useEffect() in React codebases
- Usi…
G
$100 in Codex credits for college student in U.S. and Canada:
O
OpenAIDevs
@OpenAIDevs
Meet Codex for Students. We're offering college students in the U.S. and Canada $100 in Codex credits. Our goal is to support students to learn by building, breaking, and fixing things. https://t.co/WrOtW8E8Lk https://t.co/l2T81LgKCI
E
Optimus+PV will be the first Von Neumann probe, a machine fully capable of replicating itself using raw materials found in space