OpenAI Ships GPT-5.4 Mini as the Community Declares "The Harness Is Everything"
OpenAI launched GPT-5.4 mini and nano models while the AI developer community rallied around a surprising consensus: model capability matters less than the scaffolding around it. Harness engineering, agent discipline systems, and local inference on consumer GPUs dominated the conversation, with Superpowers hitting 91K GitHub stars for what amounts to markdown files telling AI agents to slow down.
Daily Wrap-Up
The most interesting thing about today's feed isn't the GPT-5.4 mini launch, though that's the obvious headline. It's that almost nobody seemed to care about the new model compared to the explosion of conversation around what wraps around models. From harness engineering manifestos to Superpowers' 91K GitHub stars to local inference advocates squeezing impressive results out of RTX 3060s, the community is telling us something clear: we've crossed a threshold where model capability is table stakes and the real differentiation is in orchestration, discipline, and developer experience.
The Superpowers story is genuinely surprising. @aakashgupta traced the backstory of Jesse Vincent, who went from building the most popular open-source ticket tracker in 1994 to co-founding VaccinateCA during COVID to now creating a "development methodology" for AI agents that's essentially a set of markdown files enforcing spec-first, test-driven discipline. Ninety-one thousand stars in five months for a repo that tells your coding agent to stop guessing and start asking questions. Meanwhile, @itsolelehmann is applying Karpathy's autoresearch method to auto-improve Claude Skills through iterative scoring loops, and @bentlegen used an autoresearch plugin to 8x a TUI app's framerate overnight. The meta-layer of AI improving AI workflows is becoming the default operating mode.
The most practical takeaway for developers: invest time in your agent harness before upgrading your model. Whether that means adopting Superpowers-style structured workflows, writing better Claude Code skills, or tuning your local inference setup with proper tool-calling frameworks, the consensus is overwhelming that disciplined orchestration beats raw model power. Pick one harness improvement this week and measure the difference.
Quick Hits
- @elonmusk says proceeds from any OpenAI legal victory will go to charity, adding another chapter to that ongoing saga.
- @felixrieseberg launched a mobile companion app for Cowork that pairs with the desktop client, rolling out to Max subscribers first with Pro coming soon.
- @_GenesisSystems is pushing WaterCube, an air-to-water technology generating up to thousands of gallons per day, a reminder that not all interesting tech is software.
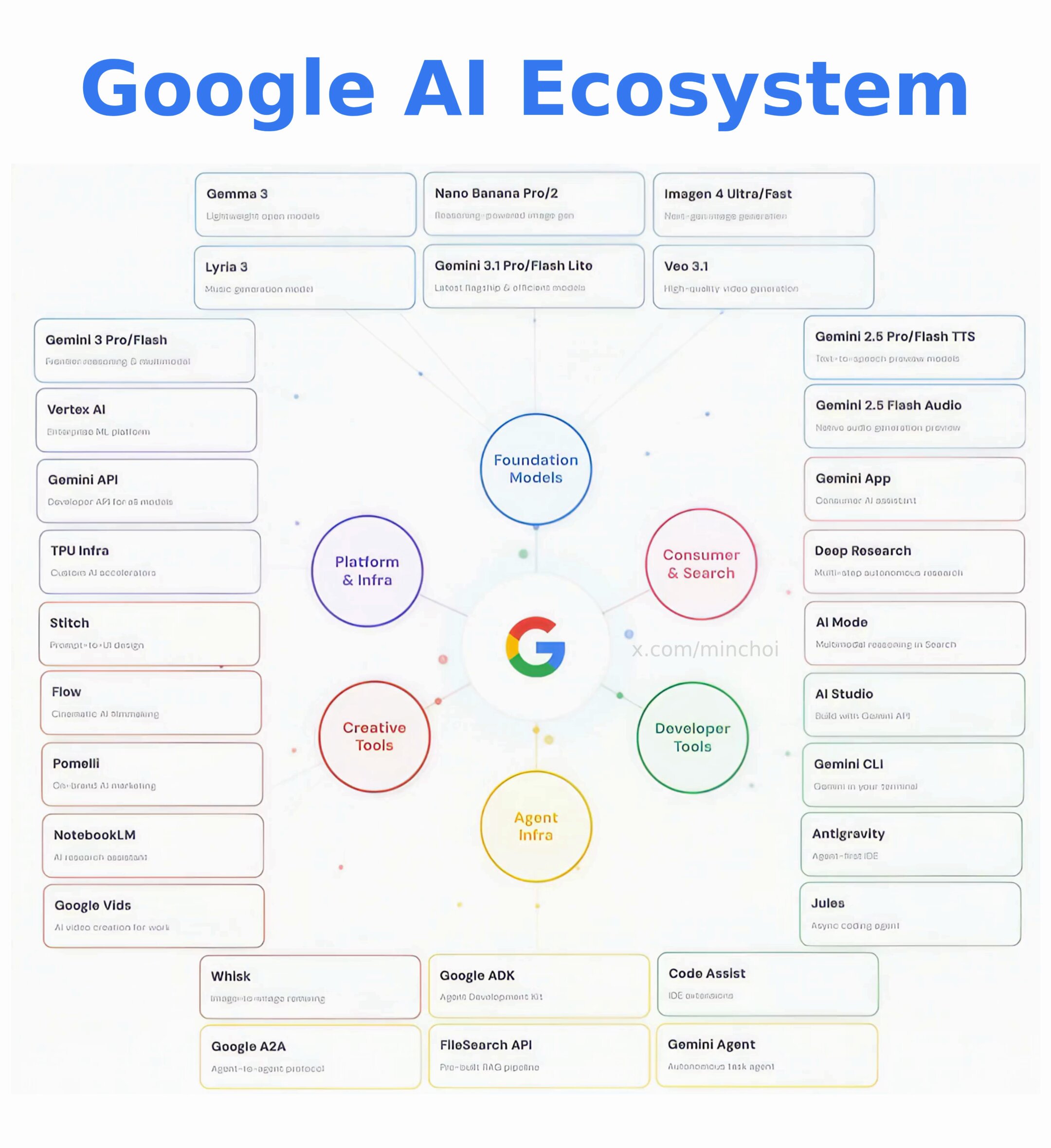
- @minchoi argues the real AI war isn't Claude vs ChatGPT but who will own the "entire AI operating system," pointing to Google's sprawling ecosystem.
- @michaeljburry published a 16,000-word critique of Palantir that he claims got him cut off from financial press coverage.
- @alexhillman shared a walkthrough of his custom agent memory system "Memory Lane," noting that non-technical people found the technical breakdown accessible.
- @zostaff posted a provocative video about AI agents trading Polymarket autonomously overnight, claiming $14K gains from a Docker Compose setup.
Harness Engineering Takes Center Stage
The loudest signal in today's feed is a collective realization that the scaffolding around AI models matters more than the models themselves. @Av1dlive put it bluntly, quoting an agentic engineer's thesis: "The model is almost irrelevant. The harness is everything." The post goes further, arguing that "every failure is a signal about what the environment needs" and that "when agent throughput far exceeds human attention, corrections are cheap and waiting is expensive." This isn't just philosophical musing. It's a design principle that's reshaping how people build with AI.
The Superpowers project is the clearest proof point. As @aakashgupta detailed, Jesse Vincent built a system where your AI agent "stops, asks what you're actually building, writes a spec in chunks small enough to read, breaks implementation into 2-5 minute tasks with exact file paths, and deletes any code written before tests exist." The growth rate of 18,000 stars per month tells you this resonates with real pain. The bottleneck in AI-assisted development isn't model intelligence. It's discipline.
This connects directly to @trq212's post on lessons from building Claude Code's Skills system, where skills have become "one of the most used extension points" but their flexibility makes it hard to know what works best. The harness engineering movement is essentially the community answering that question collectively: structure beats flexibility when you need reliable output.
Agent Architecture and Subagent Patterns
Multi-agent orchestration is moving from experimental to established pattern. @elliotarledge did a clean technical breakdown of codex-rs's subagent architecture, highlighting five core tools exposed to the LLM: spawn_agent, wait_agent, send_input, close_agent, and resume_agent. The design decisions are worth studying. Context forking lets child agents inherit full parent conversation history, async completion notifications eliminate polling, and depth limits prevent infinite recursion. The batch mode where "each CSV row becomes a worker agent, up to 64 concurrent" shows how parallel agent execution is becoming a first-class primitive.
@DanielGri shared updates on tool call rendering with support for parallel subagents, while @DominikTornow highlighted pi by @badlogicgames as "a peek into the agentic future: a minimal core that shapes itself into the tool that you need." The convergence is clear: the winning agent architectures are minimal cores with rich extension points, not monolithic systems trying to do everything.
What's notable is how quickly these patterns are standardizing. Context forking, config inheritance, depth limits, and async notifications aren't novel ideas individually, but seeing them codified into a clean five-tool interface suggests the community is settling on shared abstractions for multi-agent coordination.
OpenAI Launches GPT-5.4 Mini and Nano
@OpenAIDevs announced GPT-5.4 mini and nano, positioning them as "our most capable small models yet." The headline numbers: GPT-5.4 mini is "more than 2x faster than GPT-5 mini" and "optimized for coding, computer use, multimodal understanding, and subagents." GPT-5.4 nano targets lighter-weight tasks as the smallest and cheapest option. @gdb kept his introduction characteristically terse, simply writing "introducing gpt-5.4 mini" with a quote of the official announcement.
The "optimized for subagents" positioning is telling. OpenAI is explicitly designing models for the orchestration patterns the community is already building. When your model's marketing highlights include "subagents" as a first-class use case, you know the multi-agent paradigm has moved from research curiosity to product requirement. The 2x speed improvement also matters enormously for agent workloads where models are called dozens of times per task and latency compounds quickly.
Local AI and Consumer Hardware
The local inference advocates had a big day. @sudoingX delivered an impassioned case for running AI on consumer GPUs, reporting that Qwen 3.5 9B on an RTX 3060 achieved "99 percent tool call success rate" and autonomously iterated on its own game code across 11 files. The key argument: "there is no point buying 3 mac studios when things done well you can squeeze a similar level of intelligence from 9B compared to 70B. But only when you create the right environment for your model through the right harness."
@danveloper took a different angle, using Claude Code with Karpathy's autoresearch repo and Apple's "LLM in a Flash" paper to get Qwen3.5-397B running on an M3 Max with 48GB RAM. That's a 397 billion parameter model on a laptop. The privacy argument from @sudoingX lands differently when paired with this kind of capability: "your AI, your agent, your prompts, your experiments. Why give them away for free."
The through-line connecting local inference back to harness engineering is impossible to miss. Both camps agree the model is necessary but not sufficient. The differentiation is in the framework, the tool-calling parsers, the skills system, and the orchestration layer.
AI-Native Development Practices
@BrendanFalk introduced what he calls the "Composer 1 interview," a coding interview format where candidates get one hour to build a medium-sized project using Cursor's Composer 1 model. It's a deliberate handicap: use the weakest available model and show us what you can do. This is harness engineering applied to hiring. The signal isn't whether a candidate can prompt a frontier model into producing code. It's whether they can steer a limited model effectively.
@itsolelehmann shared a meta-skill that auto-improves other Claude Code skills using Karpathy's autoresearch method: run the skill, score the output, find failures, make one small change, re-run, keep improvements, revert regressions, repeat. @nicopreme released an update to pi-prompt-template-model adding a --loop flag for re-running prompts until nothing changes. Both point toward the same future: AI development workflows that are themselves iterative optimization loops, not one-shot prompts.
Automated Research Pipelines
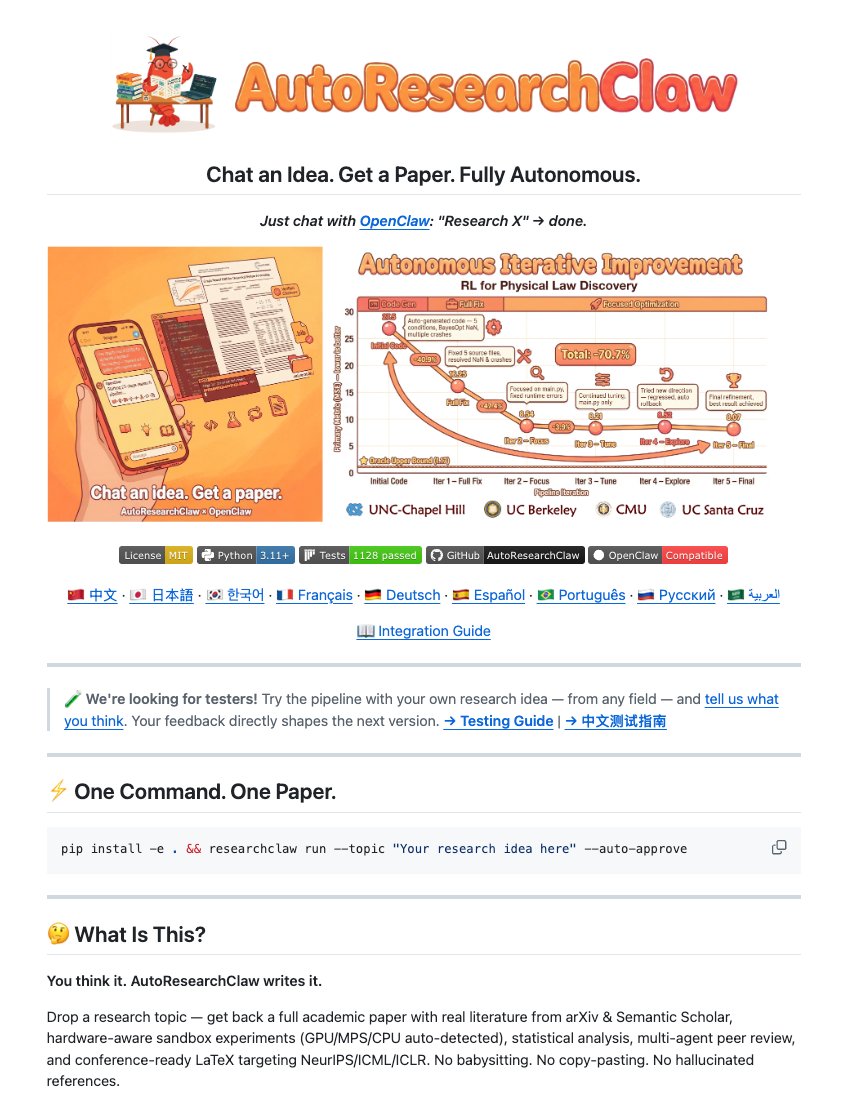
@DataChaz highlighted AutoResearchClaw, an open-source project that automates the entire scientific method across 23 stages. It handles literature review by searching arXiv and Semantic Scholar with cross-referencing against DataCite and CrossRef ("no fake papers make it through"), runs sandboxed experiments with self-healing code, and produces 5,000+ word papers formatted in ICML or ICLR LaTeX templates. The --auto-approve flag lets you walk away entirely.
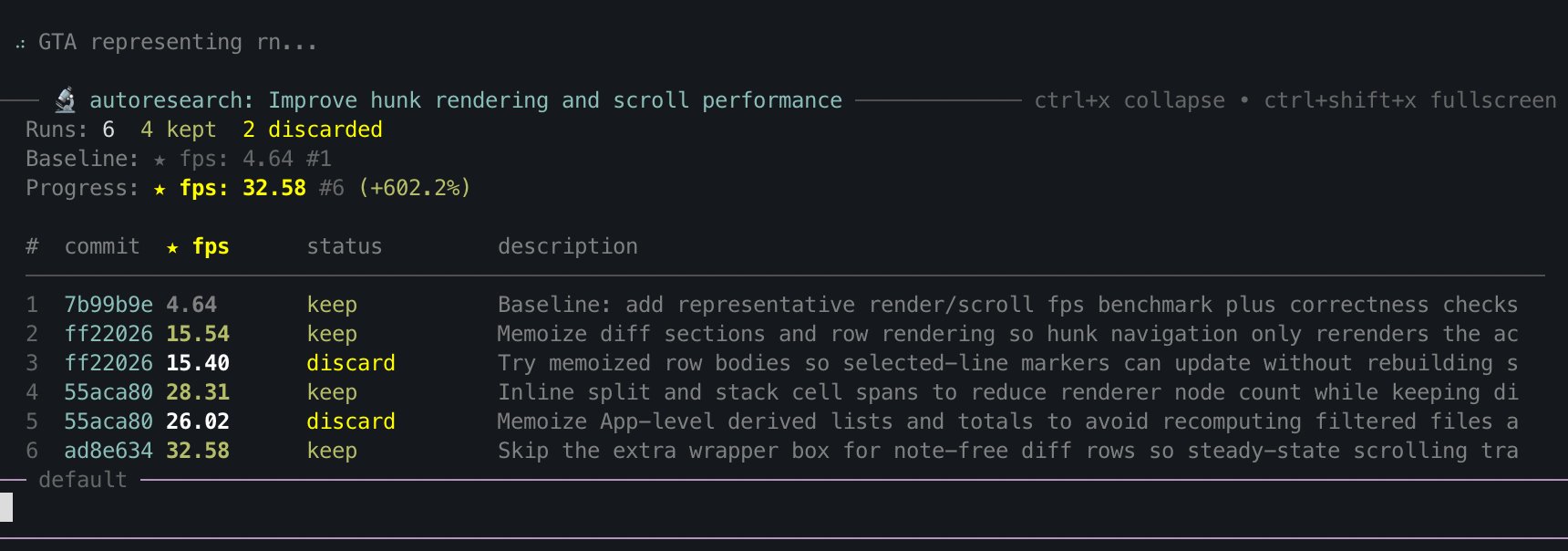
@bentlegen demonstrated a more practical application of the same autoresearch pattern, using it to optimize a TUI app's framerate from 4 fps to 32 fps across 6 iterations, then leaving it running overnight. This is where automated research loops become genuinely useful for everyday development: point them at a performance problem, define a metric, and let them iterate while you sleep.
Sources


The prompt is the platform


The Harness Is Everything: What Cursor, Claude Code, and Perplexity Actually Built
Lessons from Building Claude Code: How We Use Skills
Skills have become one of the most used extension points in Claude Code. They’re flexible, easy to make, and simple to distribute. But this flexibilit...

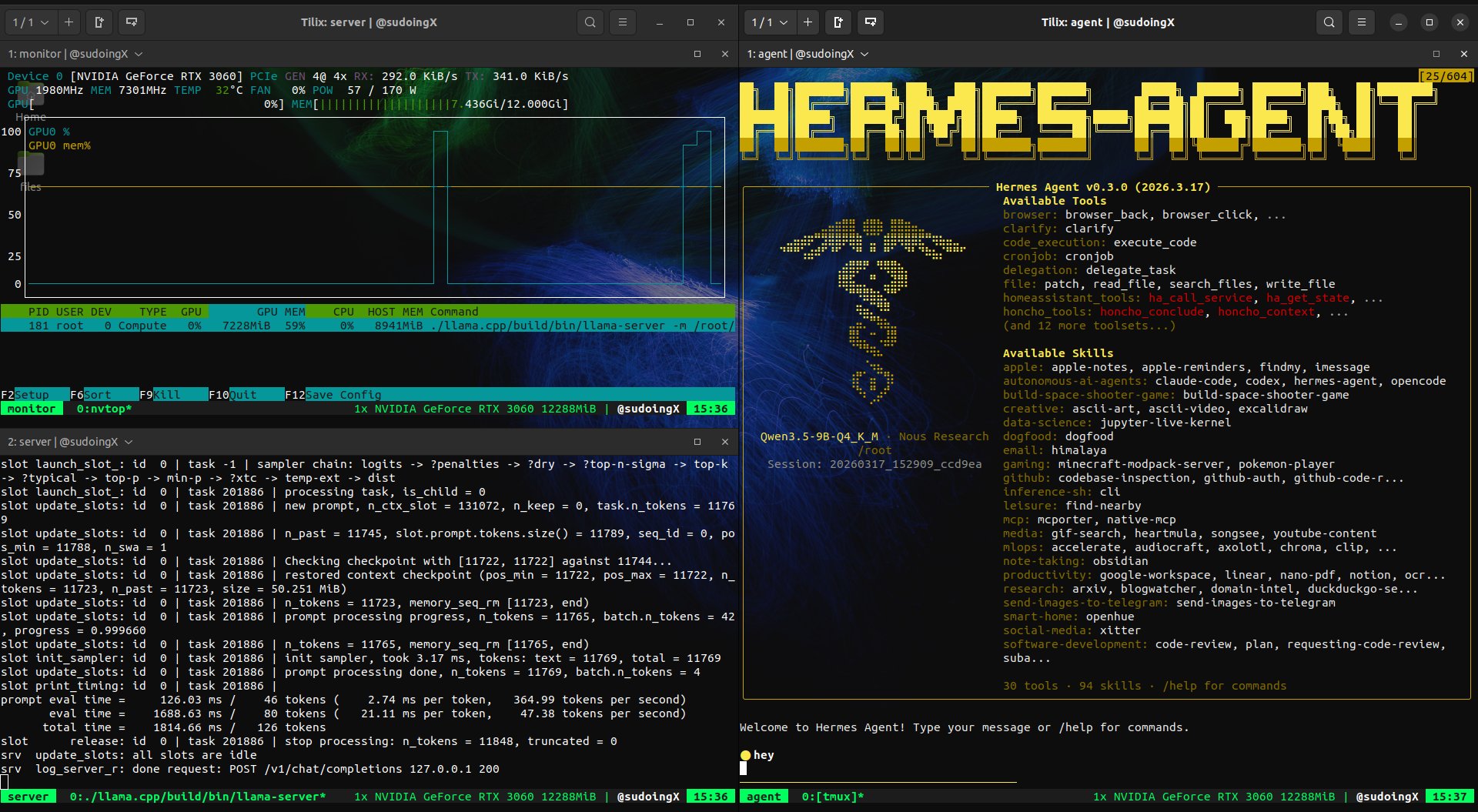
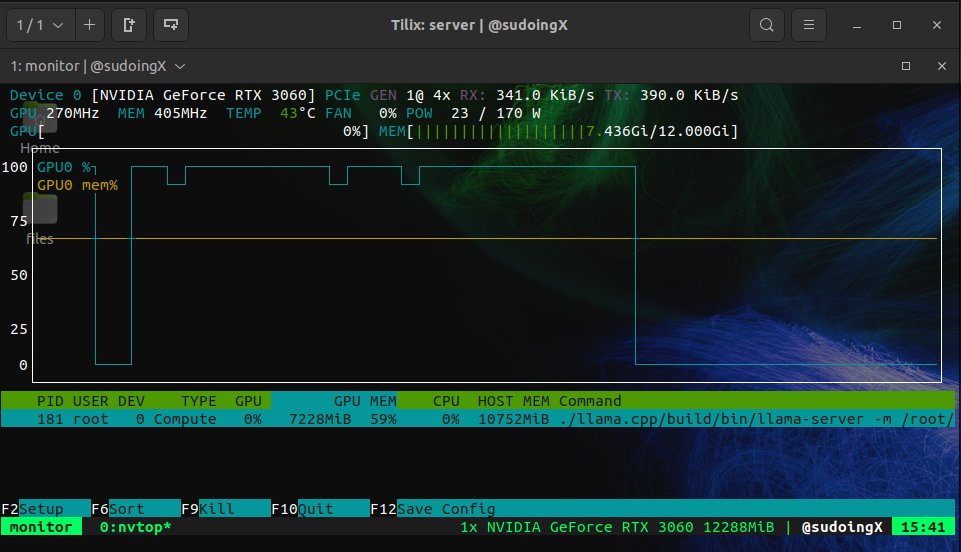
this is what 12 gigs of VRAM built in 2026. a 9 billion parameter model running on a 5 year old RTX 3060 wrote a full space shooter from a single prompt. blank screen on first try. i came back with a bug list and the same model on the same card fixed every issue across 11 files without touching a single line myself. enemies still looked wrong so i pushed another iteration and now the game has pixel art octopi, particle effects, screen shake, projectile physics and a combo system. all running locally on a card that was designed to play fortnite. three iterations. zero cloud. zero API calls. every token generated on hardware sitting under my desk. the model reads its own code, finds what's broken, patches it, validates syntax and restarts the server. i just describe what's wrong and it handles the rest. people are paying monthly subscriptions to type into a browser tab and wait for a server farm to respond. meanwhile a GPU you can find used on ebay is running a full autonomous hermes agent framework with 31 tools, 128K context window and thinking mode generating at 29 tokens per second nonstop. the game still needs work. level upgrades don't trigger and boss fights need tuning. but the fact that i'm iterating on gameplay balance instead of debugging whether the code runs at all tells you where this is headed. every iteration the game gets better on the same hardware. same 12 gigs. same 9 billion parameters. same RTX 3060 from 5 years ago your GPU is not a gaming card anymore. it's a local AI lab that never sends your data anywhere.

Claude + OpenClaw + Codex How to Quit Your Job in One Day
How to 10x your Claude Skills (using Karpathy's autoresearch method)

Just added a convenient way to chain prompt templates (slash commands) in Pi coding agent. Each step runs a different prompt template with its own model, skill, and thinking level. pi install npm:pi-prompt-template-model https://t.co/a9DKnCLY2D https://t.co/55TfmpNmMX
GPT-5.4 mini is available today in ChatGPT, Codex, and the API. Optimized for coding, computer use, multimodal understanding, and subagents. And it’s 2x faster than GPT-5 mini. https://t.co/DKh2cC5S3F https://t.co/sirArgn37L
🚨 Holy shit...A developer on GitHub just built a full development methodology for AI coding agents and it has 40.9K stars on GitHub. It's called Superpowers, and it completely changes how your AI agent writes code. Right now, most people fire up Claude Code or Codex and just… let it go. The agent guesses what you want, writes code before understanding the problem, skips tests, and produces spaghetti you have to babysit. Superpowers fixes all of that. Here's what happens when you install it: → Before writing a single line, the agent stops and brainstorms with you. It asks what you're actually trying to build, refines the spec through questions, and shows it to you in chunks short enough to read. → Once you approve the design, it creates an implementation plan so detailed that "an enthusiastic junior engineer with poor taste and no judgement" could follow it. → Then it launches subagent-driven development. Fresh subagents per task. Two-stage code review after each one (spec compliance, then code quality). The agent can run autonomously for hours without deviating from your plan. → It enforces true test-driven development. Write failing test → watch it fail → write minimal code → watch it pass → commit. It literally deletes code written before tests. → When tasks are done, it verifies everything, presents options (merge, PR, keep, discard), and cleans up. The philosophy is brutal: systematic over ad-hoc. Evidence over claims. Complexity reduction. Verify before declaring success. Works with Claude Code (plugin install), Codex, and OpenCode. This isn't a prompt template. It's an entire operating system for how AI agents should build software. 100% Opensource. MIT License.