GPT-5.4 Hits $1B Run Rate in a Week as Self-Steering Agents and Tensor-Based Memory Reshape the Stack
OpenAI's GPT-5.4 is processing 5 trillion tokens per day within a week of launch. Meanwhile, the AI engineering community is converging on self-steering multi-model agents, novel memory architectures that bypass embeddings entirely, and a growing consensus that process and context engineering matter more than raw prompting skill.
Daily Wrap-Up
The biggest number dropped today came from Greg Brockman: GPT-5.4 is already handling 5 trillion tokens per day, more volume than OpenAI's entire API processed a year ago, with an annualized run rate of $1 billion in net-new revenue within its first week. That's a staggering adoption curve and it tells you something important about where enterprise AI spending is headed. But the more interesting signal today wasn't about any single model. It was about the infrastructure being built around models: self-steering agents that swap between Grok, Gemini, and Claude mid-task, memory systems that compress facts into tensors instead of vector databases, and a growing chorus of experienced engineers arguing that the craft of building with AI is settling into real engineering discipline rather than prompt magic.
The agent ecosystem is maturing fast and in unexpected directions. @peterom's Desloppify experiment shows an agent that can clear its own context, switch its own models, and prompt itself when it stalls, running 6+ hours of autonomous refactoring without errors. @BLUECOW009's nuggets project takes a completely different approach to AI memory, ditching embeddings and databases entirely in favor of tensor multiplication. These aren't incremental improvements. They represent genuinely new architectures that challenge assumptions about how AI systems should be built. Meanwhile, @YoavCodes is pushing Electrobun past 10,000 GitHub stars and pivoting toward distributed agentic systems, and @mattpocockuk is making the case that traditional software engineering processes (TDD, PRDs, structured workflows) are more relevant than ever in the age of AI coding.
The most entertaining moment was easily @slash1sol's breathless thread about combining MiroFish, OpenViking, and Percepta into "god-tier power," complete with claims about "printing the future." The AI hype cycle remains undefeated. But beneath the hyperbole, the underlying tools are real and worth watching. The most practical takeaway for developers: invest time in learning context engineering and structured agent workflows. As @witcheer and @mattpocockuk both emphasized today, the gap between effective and ineffective AI usage increasingly comes down to process design, not prompt tricks. Build skills around managing agent context, defining clear workflows with slash commands, and understanding when to swap models for different tasks.
Quick Hits
- @NotebookLM is integrating with Yahoo Sports for March Madness bracket analysis, letting users query player stats through audio overviews and mind maps. AI meets sports gambling, as is tradition.
- @OpenAIDevs and @NotionHQ are co-hosting a Codex demo night in NYC on March 17 with hands-on workflow sessions.
- @theo teased switching to a new terminal without naming it, sparking the usual developer tools curiosity cycle.
- @hackernoon covered a new open-source touchscreen crypto miner delivering 2.15 TH/s with open firmware.
- @DAIEvolutionHub reported someone scoring 985/1000 on the new Claude Architect exam, which tests production AI system architecture rather than prompting.
- @theallinpod featured Travis Kalanick exiting stealth mode and Michael Dell discussing a $50B AI infrastructure bet, plus Dell's $6.25B "Invest America" initiative providing 401k accounts from birth for 25 million kids.
- @badlogicgames RT'd @dillon_mulroy's first impressions of the Pi coding tool, noting that "less is more" and subagents weren't as missed as expected.
Agents & Self-Steering Systems
The most technically interesting thread of the day came from the agent orchestration space. We're watching a shift from agents that follow instructions to agents that manage themselves. @peterom shipped an experiment on top of Hermes Agent where the agent can steer its own execution: clearing context when it gets cluttered, switching between models based on the task at hand, and prompting itself when it stalls out. The demo showed it cycling between Grok 4.20 for execution, Gemini 3.1 for planning, and Claude for sense-checking, running "6+ hours of refactoring w/o errors/stoppage" with self-correcting triggers built in.
This multi-model approach is significant because it treats different LLMs as specialized tools rather than monolithic solutions. The economics are notable too: execution tasks go to the cheapest capable model at $6/month, while the expensive Claude tier is reserved for verification. @nyk_builderz contributed a related piece with a practical migration runbook for moving agents from OpenClaw to Hermes, noting that "the migration tool only handles config conversion" and warning about credential format differences and "the silent auth trap that kills your agent's memory." These are the kinds of production-grade concerns that signal a maturing ecosystem. We're past the "look, my agent can write a todo app" phase and into serious operational territory where migration paths, credential management, and long-running reliability actually matter.
AI Memory Architectures
Memory remains one of the hardest unsolved problems in agentic AI, and today brought a genuinely novel approach. @BLUECOW009 made a compelling case for nuggets, a system that takes a fundamentally different path from every other memory solution on the market. While Mem0, MemOS, Recall, and Memlayer all follow the same pattern of calling an LLM to extract facts and an embedding API to store and retrieve them, nuggets "compresses facts into a single mathematical object, a tensor. Adding a memory? Multiply into the tensor. Recalling a memory? Multiply out of the tensor. No API calls. No database. No embeddings. Just math on your local machine."
The claimed efficiency gains are striking: roughly 415 tokens at session start plus 50 per turn, compared to Mem0's 1,600 tokens per save operation. That's a 22x cost reduction that also runs fully offline. This matters because memory token overhead is one of the primary cost drivers in long-running agent sessions. If the tensor approach delivers on its promises, it could reshape how developers think about stateful AI applications. @slash1sol also highlighted ByteDance's OpenViking structured memory system with its hierarchical filesystem approach (L0 ultra-summary through L2 full details), claiming agents can now "run 100+ steps with zero amnesia." Two radically different architectures attacking the same problem from different angles suggests the memory layer is where the next wave of real innovation is happening.
Context Engineering & Developer Process
A clear theme emerged today around the idea that working effectively with AI is becoming an engineering discipline with its own best practices. @witcheer distilled all of Anthropic's courses into a framework arguing that "prompt engineering is just one layer, context engineering is the full picture" and that "system prompts are behaviour architecture, not preferences." The key insight: more context doesn't equal better output. It's about structuring the right context.
@mattpocockuk reinforced this from a practitioner's angle, sharing the five Claude Code skills he uses daily: "/grill-me, /write-a-prd, /prd-to-issues, /tdd, /improve-my-codebase." What's notable is that these aren't clever prompts. They're structured processes bundled into repeatable commands. As he put it, "Right now, process has never been more important. And skills are the best way to bundle up processes for agents." This convergence between traditional software engineering discipline and AI tooling is one of the most important trends to watch. The developers getting the most out of AI coding tools aren't the ones writing the cleverest prompts; they're the ones building the most rigorous workflows around them.
Models & Market Dynamics
@gdb's GPT-5.4 announcement dominated the model news cycle. The numbers speak for themselves: "within a week of launch, 5T tokens per day, handling more volume than our entire API one year ago, and reaching an annualized run rate of $1B in net-new revenue." This is remarkable adoption velocity and suggests that enterprises have standing infrastructure ready to absorb new model releases almost immediately. The API economy around foundation models is no longer speculative; it's a billion-dollar-scale business that can spin up revenue within days of a launch.
On the platform side, @googleaidevs announced new cost management features for the Gemini API, including granular monthly project spend caps and revamped usage tiers with automatic upgrades. These are unsexy but critical infrastructure improvements. As AI API costs become a real line item for companies, the providers competing on developer experience around billing and observability will have an advantage. The model wars aren't just about benchmark scores anymore; they're about making it manageable to actually run these things in production.
Creative AI & New Frameworks
Two releases today pushed into creative and application-building territory. @RoyalCities launched Foundation-1, described as a state-of-the-art text-to-sample model built specifically for music production workflows, running on roughly 7GB of VRAM, entirely local, and completely free. The emphasis on production workflows rather than novelty generation suggests AI audio tools are moving past the demo stage into tools that musicians might actually integrate into their process.
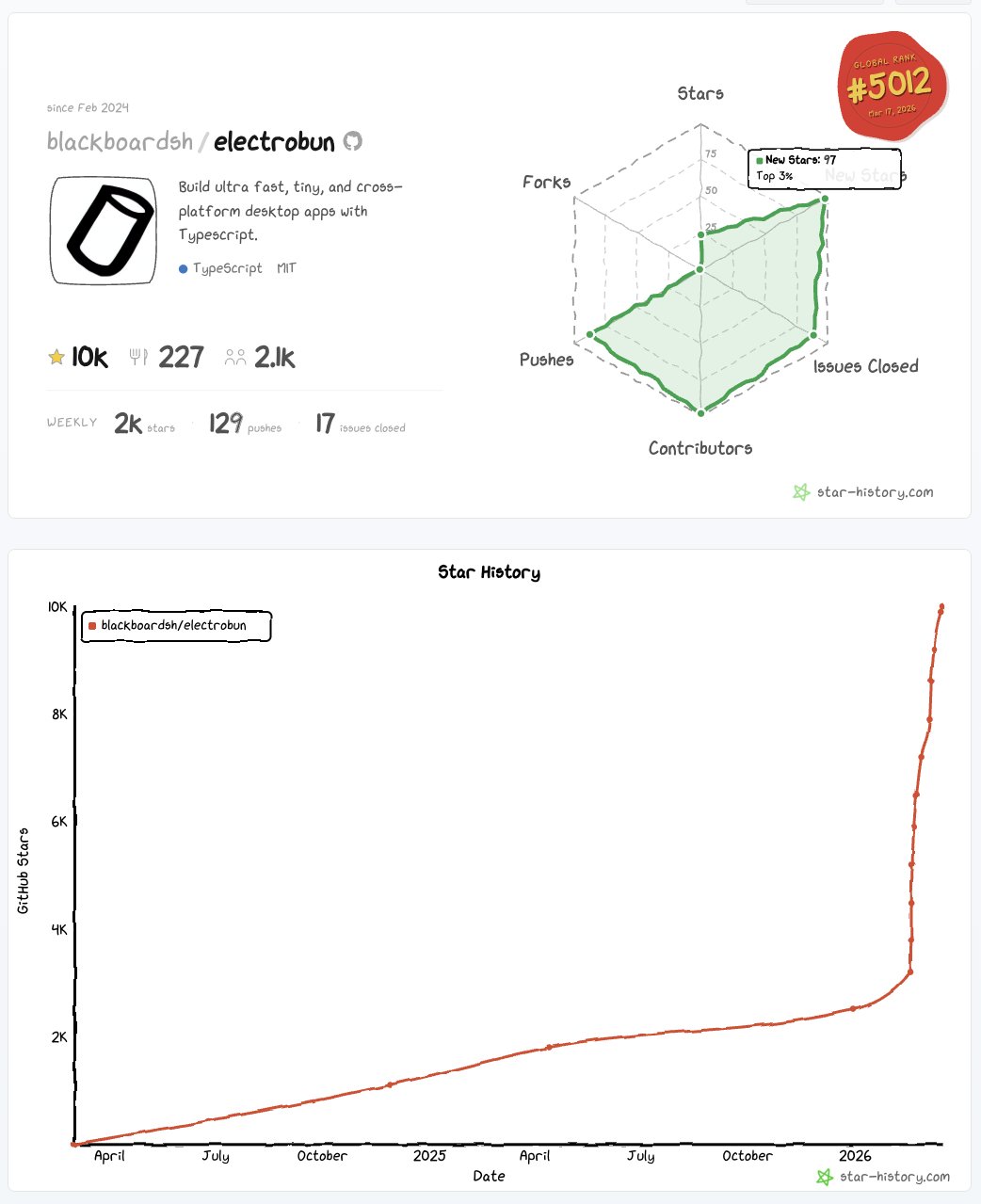
@pbakaus shipped Impeccable 1.5 with new AI-powered design skills including /typeset for typography fixes, /arrange for layout corrections, and a beta /overdrive mode that "goes harder than all other skills and pushes for technically & visually extraordinary" results. Meanwhile, @YoavCodes hit 10,000 GitHub stars on Electrobun and teased the next evolution: "a distributed, sandboxed, cross-platform agentic system for operating in this new era." The pattern across all three is the same: AI capabilities being packaged into domain-specific tools with opinionated workflows rather than general-purpose interfaces.
Sources
O
Codex 🤝 @NotionHQ
Meet us in NYC on March 17 for a night packed with:
Codex demos.
Practical workflows.
Builders to meet and learn from.
https://t.co/MjvBqrnM1e https://t.co/yfXQ1mYmvN

K
Someone just scored 985/1000 on the new Claude Architect exam.
Someone just scored 985/1000 on the new Claude Architect exam.
And their notes accidentally revealed something interesting. The exam tests exactly how production AI systems with Claude are built. Not prompts. Not ...
H
Open-source hardware is pushing new boundaries in personal computing.
This new touchscreen miner delivers 2.15 TH/s with fully open-source firmware and a fully assembled design.
See the details 👇
https://t.co/3h8OxD3eqm
M
Everyone thinks AI is a paradigm shift.
That everything we've learned about building software in the last 20 years is for boomers.
I disagree. That's why I built Claude Code for Real Engineers.
It's a 2-week cohort that teaches AI Coding from first principles, all the way from requirements gathering to delegating to AFK agents.
It's the best course I've ever built.
It starts in 2 weeks, and for this week only it's 40% off.
https://t.co/PRTVBpP2oX
G
Get more transparency and control over your Gemini API costs with new features in @GoogleAIStudio!
- Set granular monthly budgets for every project with Project Spend Caps
- Experience automatic upgrades and get faster access to higher rate limits with revamped Usage Tiers
- Enjoy enhanced observability, control, and improved billing flow directly within AI Studio
Set your cap, start building: https://t.co/H8TEC3I3bE
N
Here are 3-Pointers on how to use our newest @YahooSports featured notebooks to fill out your @YahooFantasy Bracket Mayhem brackets:
1. Listen to audio overviews summarizing thousands of games
2. Ask the Chat specific questions about any player
3. Create a Mind Map to dive into every team
Access them here: https://t.co/lCNvNBLdjk

G
gpt-5.4 has ramped faster than any other model we've launched in the API: within a week of launch, 5T tokens per day, handling more volume than our entire API one year ago, and reaching an annualized run rate of $1B in net-new revenue.
it's a good model, try it out!

S
me realizing that with MiroFish from the Chinese college kid for agent simulations + OpenViking from ByteDance for infinite AI memory + this new Percepta startup that lets LLMs actually COMPUTE real math instead of guessing.. I can now build way more than just a $100k/month prediction bot, this combo is literally god-tier power and unlimited opportunity

S
slash1sol
@slash1sol
BREAKING: LLMs just learned to COMPUTE for real, it's mean NO MORE GUESSING math. Chinese college kid Guo Hanjiang vibe-coded MiroFish in 10 days (23k+ GitHub stars, $4.1M from Shanda in 24h) - the AI swarm simulator that’s already printing. ByteDance (VolcEngine) dropped the nuclear upgrade: OpenViking - structured viking:// filesystem memory (L0 ultra-summary -> L2 full details) - agents now run 100+ steps with zero amnesia or hallucinations, 11.6k stars and climbing. Now this just dropped and the entire AI timeline is shaking. Startup Percepta embedded a full WASM virtual machine directly into Transformer weights. No more external Python sandboxes. No more hallucinations in exact tasks. The model streams raw machine code at 30,000+ tokens/sec on CPU, executes millions of steps, and solves the world’s hardest Sudoku via real backtracking + constraint propagation - 100% accurate, zero bullshit. They killed the Attention Bottleneck with Exponentially Fast Attention (HullKVCache + 2D heads + convex hull queries in log time). What used to die at 1k steps now flies. This is the bridge: System 1 intuition (normal LLMs) + System 2 deterministic logic (native code execution) in ONE brain. Agents won’t need tools anymore. Heavy simulations will run inside the weights. Check out: https://t.co/6BKcYCd7M9 Now put it all together: MiroFish swarms + OpenViking infinite memory + Percepta native flawless compute = agents that can hardcore simulate millions of future scenarios, run perfect logic loops for days, and predict events/markets/reality with god-tier accuracy. No drift. No bullshit. Just pure foresight. This combo will change everything, imo. The era of predictive super-agents that actually print the future is here. We’re watching this one closely. Save this combo.
M
I've been an engineer for nearly a decade. Right now, process has never been more important.
And skills are the best way to bundle up processes for agents.
Here are the 5 I use every day:
/grill-me
/write-a-prd
/prd-to-issues
/tdd
/improve-my-codebase https://t.co/pD1fKkDxYw

R
After months of work, today I’m releasing Foundation-1.
A SOTA text-to-sample model built specifically for music production workflows.
It may also be the most advanced AI sample generator currently available - open or closed.
• ~7 GB VRAM
• Entirely local
• 100% free
😁 https://t.co/3AXIySw06k

@
every AI memory system out there (Mem0, MemOS, Recall, Memlayer) works the same way: call an LLM to extract facts, call an embedding API to store them, call the embedding API again to search
nuggets does none of that
instead of storing each memory separately in a database, nuggets compresses facts into a single mathematical object — a tensor. adding a memory? multiply into the tensor. recalling a memory? multiply out of the tensor. no API calls. no database. no embeddings. just math on your local machine
the result: ~415 tokens at session start + ~50 per turn. compared to Mem0 burning ~1,600 tokens of LLM input every time you save a single fact
22x cheaper. runs fully offline. your data never leaves your machine. and you can create as many nuggets as you need — each one is its own tensor, no limit on how many you spin up
P
Shipping an experiment on top of Hermes Agent that allows an agent to steer itself
With it, a harness like desloppify can clear its own context, switch its models, prompt itself when it stops, etc.
Video shows switching between Grok 4.20 ($6/m) for execution + Gemini 3.1 ($12/m) for planning + Claude ($25/m) for sense-checking - 6+ hours of refactoring w/o errors/stoppage - this can endlessly and safeguard itself w/ various triggers as sense-checks!
Desloppify v0.9.10 release notes w/ instructions to test + many more contributions by the community: https://t.co/bA3gszqTVj
Video by the wonderful @hannahsubmarine - best watched with audio:
P
Impeccable 1.5 is here.
New:
/typeset (fix your typography)
/arrange (fix your layout)
/overdrive (beta, goes harder than all other skills and pushes for technically & visually extraordinary)
Power up your AI harnesses and design something powerful 💪
https://t.co/x2KG2Fjjkt https://t.co/KG8EX67m16

T
Two Legendary Founders LIVE in Austin, Texas
Travis Kalanick and Michael Dell join @Jason and @friedberg live on stage!
(0:00) Travis Kalanick: Officially exiting stealth mode, what he’s been working on
(5:52) How to automate the physical world, markets to go after
(11:00) Travis’s return to self-driving: Tesla, Waymo, and the autonomous race
(16:17) Leaving Los Angeles for Austin, the decline of truth and justice in California
(25:51) Actuators, robot hands, “Capital as a weapon,” Middle East SWF impacted by Iran War
(36:00) Michael Dell: Dorm room to $140B in annual revenue, why Texas attracts founders
(43:46) Dell's $50B AI infrastructure bet
(1:03:50) Invest America: Michael Dell's $6.25B gift - A 401k from birth for 25M kids
-----------------------------------------------
This podcast was recorded LIVE at Arena Hall in Austin, Texas.
Thanks to our partners for making this event possible!:
EY (@EYnews):
Austin vibes meet AI innovation. Thanks to EY for co‑hosting with us at #SXSW.
Discover what executives are saying about AI transformation in the latest AI Pulse Survey. https://t.co/MiFPllaXql
@Forge_Global:
We’re proud to highlight our partners at Forge Global, who are helping the world’s most innovative private companies and their teams gain #liquidcourage on their terms.
Learn more here: https://t.co/eCYsYuR9Iy
De'Longhi
@athenago
@Polymarket

N
OpenClaw to Hermes: The Complete Migration Runbook
OpenClaw to Hermes: The Complete Migration Runbook
3 production agents migrated in 8 steps. But the migration tool only handles config conversion — credential formats, workspace files, and the silent a...
M
RT @dillon_mulroy: thoughts after day 1 of using pi full time
- less is more
- i don't miss subagents like i thought i would
- /tree is an…
Y
A month ago I shipped Electrobun v1.
A week ago I shipped a deep WGPU integration.
A day ago I added 35 desktop apps people are already shipping built with Electrobun to the Readme.
An hour ago Electrobun passed 10,000 Github stars.
Next I'm shipping https://t.co/JdbrFCelgl, my full vision built on Electrobun: A distributed, sandboxed, cross-platform agentic system for operating in this new era.
Y
YoavCodes
@YoavCodes
It's here. Electrobun is ready for you. npx electrobun init https://t.co/OBOPeTnKOt https://t.co/Jjnh8nnFel
W
you don't have time to follow all Anthropic courses? I did it for you.
~/ prompt engineering is just one layer - context engineering is the full picture
~/ system prompts are behaviour architecture, not preferences
~/ more context ≠ better output
~/ the 4D framework
full breakdown with copy-paste templates ↓
W
witcheer
@witcheer
Stop Writing Better Prompts. Start Building Better Context.