OpenSquirrel Reimagines the IDE Around Agents as Kimi and Nvidia Ship New Open-Source Models
The agent-native development toolchain is taking shape fast, with new IDEs, sandboxing debates, security guides, and collaborative editors all landing in the same 24-hour window. Meanwhile, Kimi's Attention Residuals paper and Nvidia's Nemotron-3 Super both dropped as open-source releases, continuing the trend of capable models going free. The spatial mapping discourse around Niantic's 30-billion-image Pokémon GO dataset offered the week's most fascinating detour into how games quietly build AI infrastructure.
Daily Wrap-Up
The most striking pattern today isn't any single model release or tool launch. It's that the entire scaffolding around AI-assisted development is being rebuilt simultaneously. We saw a new Rust-based IDE designed around agents as the primary unit of work, a collaborative document editor built for human-AI co-authorship, a formal security guide for agentic coding, a TLA+ prechecking tool for agent-generated designs, and an ongoing debate about how to properly sandbox Claude Code. Six months ago, the conversation was "can AI write code?" Now it's "what does the entire development environment look like when AI writes most of the code?" That shift from capability questions to infrastructure questions is the real story.
On the model side, the open-source drumbeat continues. Kimi's Attention Residuals paper introduces a genuinely interesting architectural idea (learned, input-dependent attention over preceding layers as a replacement for standard residual connections), and they open-sourced it. Nvidia shipped Nemotron-3 Super, a 120B-parameter MoE model with only 12B active parameters, purpose-built for agents. Z.ai released GLM-5-Turbo. The common thread: all optimized for agent workflows, all open. @TukiFromKL's breathless framing about Chinese labs versus Silicon Valley aside, the real dynamic is that agent-optimized inference is becoming a commodity faster than anyone expected. Meanwhile, @jamonholmgren's "Night Shift" workflow thread and @doodlestein's exhaustive multi-model planning process both point to the same conclusion: the developers getting the most out of these tools are the ones investing heavily in process design, not just prompt engineering.
The most practical takeaway for developers: if you're building with AI agents, invest your time in the surrounding infrastructure (sandboxing, security boundaries, verification tooling, structured planning documents) rather than chasing the latest model. The models are converging; your workflow is the differentiator.
Quick Hits
- @awilkinson RT'd a story about someone using ChatGPT to sell a house in 5 days with no real estate agent, getting 5 offers in 72 hours. The "AI replaces professional services" anecdote cycle continues.
- @naval RT'd @getjonwithit on how LLM success reveals how much human knowledge is fundamentally linguistic and pattern-based.
- @michaeljburry recommended an 1880 Smithsonian presentation as relevant to today's AI scaling debate, drawing parallels between historical technological optimism and current LLM hype. Weekend reading for the skeptically inclined.
- @theallinpod wrapped their SXSW Austin event with Michael Dell and Travis Kalanick, with the full show dropping tomorrow.
- @rohit4verse highlighted someone who reverse-engineered Anthropic's partner program features and released them for free, framing it as a "Claude architect" course.
- @nummanali made the case for Pi Coding Agent over OpenCode as a base for customizable AI development workflows, citing its plugin ecosystem and endorsement from Spotify's CEO.
- @mattpocockuk asked about alternatives to Docker sandbox for Claude Code on WSL, noting reliability issues and the inability to run truly AFK agent workflows with the built-in
/sandboxcommand.
Agents as the New Unit of Development
The idea that agents, not files, should be the organizing principle of development tools went from Karpathy shower thought to shipping software in record time. @elliotarledge announced OpenSquirrel, a Rust-based IDE built with GPUI (the same framework behind Zed) that treats agents as the central unit rather than files. It supports Claude Code, Codex, OpenCode, and Cursor CLI. As Elliot put it: "This really forced me to think up the UI/UX from first principles instead of relying on common electron slop." He was responding directly to @karpathy's observation that "the basic unit of interest is not one file but one agent. It's still programming."
This wasn't the only agent-native tool to land. @danshipper launched Proof, an open-source collaborative document editor where humans and AI agents work in the same document with provenance tracking (green rail for human text, purple for AI). The pitch is straightforward: when agents generate most of the text in your planning docs, PRDs, and memos, you need a tool designed for that reality rather than markdown files on your laptop. And @KingBootoshi released TLA Precheck, a tool that uses TLA+ formal verification to catch design bugs in agent-generated output before they become code bugs, with skills for both Claude Code and Codex.
What connects all three is a recognition that the agent revolution needs its own native toolchain. You can't just bolt agents onto file-centric IDEs and markdown editors and expect good results. The developers building these tools are essentially asking: if we designed the entire workflow from scratch knowing that agents do most of the typing, what would it look like?
Agentic Workflows and Process Design
Two of the day's longest and most substantive posts were essentially workflow manifestos. @jamonholmgren shared hard-won principles from his "Night Shift" agentic workflow, which he says is "about 5x faster, better quality" than previous approaches. His rules are blunt: "I never want to review another agent-produced plan again. Waste of my time, overwhelming, not worth it. It's valuable to the agent, but not to me." His philosophy centers on burning tokens freely for validation while protecting his own time and energy, and investing in process documentation that pays dividends across future sessions rather than guiding agents interactively.
@doodlestein took the opposite approach to planning but arrived at a complementary conclusion. His post detailed an elaborate multi-model planning process for adding a messaging substrate to his Asupersync project: generate a proposal with GPT 5.4 in Codex, run it through five rounds of self-critique, then solicit feedback from GPT Pro, Gemini 3 Deep Think, Claude Opus 4.6, and Grok 4.2 Heavy, before synthesizing a "best of all worlds" hybrid. The process is intensive, but the logic is sound: "I'll work on the process, docs, and specs as much as I need to, in order to reap the benefits in future sessions."
The tension between these two approaches is productive. Jamon says don't review agent plans; Jeffrey says build elaborate multi-model planning pipelines. But both agree on the meta-principle: your competitive advantage is in process design, not in how cleverly you prompt a single model.
Open-Source Models Keep Shipping
The model release cadence shows no signs of slowing. @minchoi covered Nvidia's Nemotron-3 Super, a 120B-parameter mixture-of-experts model with 12B active parameters, open-sourced and built specifically for AI agent workloads. @Zai_org announced GLM-5-Turbo, a speed-optimized variant of GLM-5 targeting agent-driven environments. And @TukiFromKL highlighted Kimi's Attention Residuals paper, which introduces a learned attention mechanism over preceding layers as a drop-in replacement for standard residual connections, claiming a 1.25x compute advantage with negligible latency overhead.
@TukiFromKL framed this as an existential threat to closed-model companies: "The AI race isn't US vs China anymore... It's closed vs open. And closed is losing." That's an overstatement, but the directional pressure is real. When agent-optimized open models keep landing weekly, the value proposition of $200/month subscriptions gets harder to defend on capability alone. The differentiator shifts to reliability, tooling integration, and enterprise support.
Security and Sandboxing for Agents
As agents gain more autonomy, the security conversation is catching up. @affaanmustafa released "The Shorthand Guide to Everything Agentic Security," covering fundamentals and implementation for both coding with agents and deploying them in production. His motivation: "if people even follow just this, I guarantee the number of exploits and stories going around would drop significantly, to the level of occurrences that would be normal (before vibe coding)."
Meanwhile, @mattpocockuk's frustration with Docker sandboxing for Claude Code on WSL highlights the practical gap between wanting autonomous agents and being able to safely run them. The built-in /sandbox "doesn't do what I want," he noted, because "cc can always get around it and it doesn't allow for properly AFK workflows." This is the unsexy but critical infrastructure work that determines whether agent-heavy development actually scales.
The World Is Being Mapped, One Game at a Time
The day's most fascinating tangent came from @bilawalsidhu's deep analysis of Niantic's disclosure that Pokémon GO players contributed 30 billion real-world images now being used to train visual navigation AI for delivery robots. Rather than treating this as a scandal, Bilawal contextualized it within the broader landscape of spatial mapping: "Fused together, from body cam to dashcam to doorbell to phone to satellite, every layer of physical reality is being mapped by somebody right now."
His key insight is about incentive design: "Google spends billions. Mapillary tried altruism. Hivemapper grinds with crypto. Pokémon GO cracked something none of them could: a game mechanic that subsidizes the scanning behavior." The implication for AI developers is that the most valuable training datasets may not come from deliberate data collection at all, but from products that make data generation a side effect of something people already want to do.
Local Inference Goes Peer-to-Peer
Two bookmarked posts pointed to the quiet growth of local and offline AI. @jameskharwood2 described building a local LLM setup using "WebLLM (Llama-3.2-1B-Instruct quantized) that downloads once, then runs fully offline." And @meme_terrorist shared an open-source Android app that runs AI on-device and even spreads via peer-to-peer for grid-down scenarios. These are niche use cases today, but they represent the logical endpoint of the model-commoditization trend: when capable models are small enough to run on a phone and share over local networks, the entire cloud-dependent AI infrastructure becomes optional rather than necessary.
Sources
D
BREAKING:
Proof—a new product from @every
It’s a live collaborative document editor where humans and AI agents work together in the same doc. It's fast, free, and open source—available now at https://t.co/OZeW6Wf1Iq.
It’s built from the ground up for the kinds of documents agents are increasingly writing: bug reports, PRDs, implementation plans, research briefs, copy audits, strategy docs, memos, and proposals.
Why Proof?
When everyone on your team is working with agents, there's suddenly a ton of AI-generated text flying around—planning docs, strategy memos, session recaps. But the current process for collaborating and iterating on agent-generated writing is…weirdly primitive.
It mostly takes place in Markdown files on your laptop, which makes it reminiscent of document editing in 1999.
Proof lets you leave .md files behind.
What makes Proof different?
- Proof is agent-native: Anything you can do in Proof, your agent can do just as easily.
- Proof tracks provenance: A colored rail on the left side of every document tracks who wrote what. Green means human, Purple means AI.
- Proof is login-free and open source: This is because we want Proof to be your agent's favorite document editor.
Check it out now, for free—no login required:
https://t.co/NTVY3Nh8A6

J
To reiterate a few things so they don't get lost:
1. I never want to review another agent-produced plan again. Waste of my time, overwhelming, not worth it. It's valuable *to the agent*, but not to me.
2. I will burn all the tokens, run all the tests, do all the validations to make sure that when the work product lands on my desk, it's as good as the agents can make it. My time and energy is the most important thing here.
3. The feedback loop is critical: I'll work on the process, docs, and specs as much as I need to, in order to reap the benefits in future sessions. No more manual guidance via interactive sessions (with the exception of exploratory hacking).
J
jamonholmgren
@jamonholmgren
My current agentic workflow is about 5x faster, better quality, I understand the system better, and I’m having fun again. My previous workflows have left me exhausted, overwhelmed, and feeling out of touch with the systems I was building. They also degraded quality too much. This is way better. I’m not ready to describe in detail. It’s still evolving a bit. But I’ll give you a high level here. I call this the Night Shift workflow.
J
@ApplyWiseAi @om_patel5 I haven't seen what the one here is running, but I built my own, and it runs Local LLM via WebLLM (Llama-3.2-1B-Instruct quantized – downloads once, then fully offline)
N
RT @getjonwithit: I think one of the conclusions we should draw from the tremendous success of LLMs is how much of human knowledge and soci…
T
@om_patel5 there's an open source android app that does this on your own device and even spreads via p2p for grid down scenario: https://t.co/cNBSaPREBe
R
Anthropic locked this behind a partner program.
This guy reverse-engineered the whole thing.
And gave it for free. https://t.co/rcIZDILTDD

H
hooeem
@hooeem
I want to become a Claude architect (full course).
A
RT @cryptopunk7213: i mean this story is insane.
man used chatgpt to sell his house in 5 DAYS. got 5 offers in 72 hours. no real estate ag…
M
Less than 24 hours ago, Nvidia dropped Nemotron-3 Super.
120B parameters. 12B active (MoE). Open source. Built specifically for AI agents.
Here's the full setup + workflow 👇 https://t.co/sUItssE6VR

C
Weekend reading that never gets old. The case of the relevance of an 1880 presentation @smithsonian to today’s debate on what scaling “AI” through LLMs gets us. $NVDA $AVGO $META
https://t.co/BOJOVoVIQS https://t.co/iaozvl7t69

Z
Introducing GLM-5-Turbo: A high-speed variant of GLM-5, excellent in agent-driven environments such as OpenClaw.
Coding Plan Max: https://t.co/Nk8Y98HNhU
OpenRouter: https://t.co/00bJwvZdIZ
API: https://t.co/jhAHbonoGQ

N
Best article on Pi Coding Agent
If there was to be an advert for why you should use Pi - this is it
Fully customise it to your needs
Huge set of community plugins to work with
I advise many folks that Pi is the better base over OpenCode
Spotify CEO @tobi loves it too
M
marv1nnnnn1
@marv1nnnnn1
# Build Something Just for Yourself: #2 Why not make your coding agent personal?
A
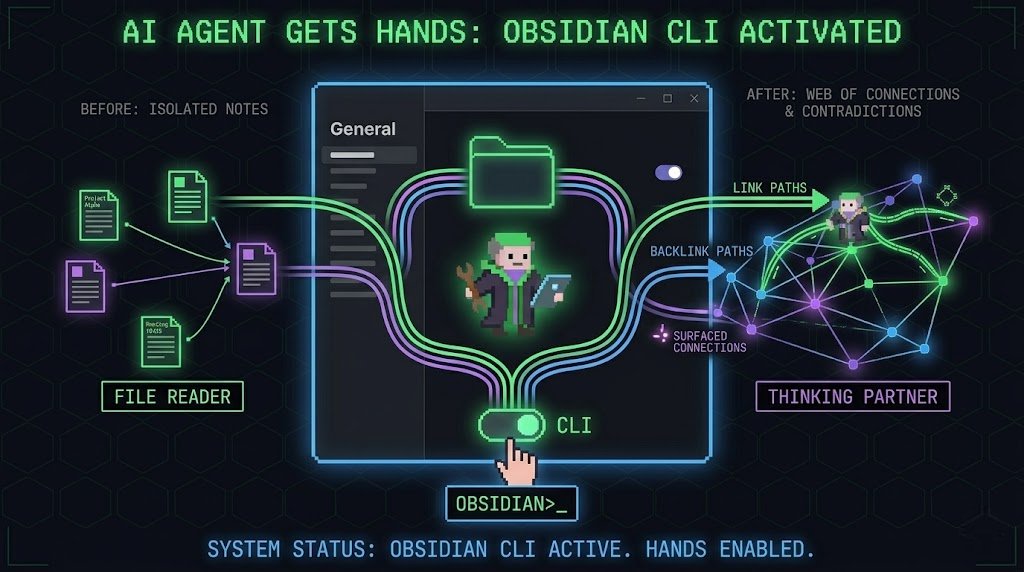
Obsidian CLI. One setting that gives your AI agent hands.
Go to Settings -> General -> scroll to the bottom -> find Command line -> enable it.
That's the entire setup.
> Two ways to use it:
For manual control: open your terminal, type Obsidian Help. You'll see every available command for managing your vault directly from the console.
For AI agents: if you're running Claude Code or OpenCode inside your vault directory, just add to your prompt: "Use Obsidian CLI".
The agent figures out the rest.
> What actually changes?
Before this setting, the agent reads individual files. It sees notes in isolation.
After - it gets Link Path and Backlink Path. Now it doesn't just read a note. It follows the entire web of connections around it.
Reads related ideas. Spots contradictions. Surfaces connections you stopped noticing months ago.
The difference between a file reader and a thinking partner is one toggle in General settings.
Bookmark this. This information might come in handy for your future.
A
Atenov_D
@Atenov_D
How I turned Obsidian into a second brain that runs itself
C
It's been a while, but I couldn't think of a better topic to cover than this after covering the fundamentals of coding with agentic harnesses (claude code) and then the less trivial aspects.
This time around there's more primer and exploratory work for the first half, before going into the fundamentals + implementation of how to set yourself up for success, coding with agents or deploying / using them in production applications.
In no way is this completely comprehensive, but if people even follow just this, I guarantee the number of exploits and stories going around would drop significantly, to the level of occurrences that would be normal (before vibe coding).
A
affaanmustafa
@affaanmustafa
The Shorthand Guide to Everything Agentic Security
T
Incredible weekend in Austin, Texas 🤠🔥
Special thanks to two legendary founders for joining us, @MichaelDell and @travisk.
And our esteemed fifth bestie @altcap.
Full show drops tomorrow on YouTube and podcast feeds!
-----------------------------------------------
Thanks to our partners for making this event possible!:
@PayPal Open:
When you need a partner trusted by millions, there’s one platform for all business - PayPal
Open. Grow today at https://t.co/FPaBHkLCJb.
EY (@EYnews):
Austin vibes meet AI innovation. Thanks to @EY for co‑hosting with us at #SXSW. Discover what executives are saying about AI transformation in the latest AI Pulse Survey. https://t.co/e9qSkwjoqU
@Forge_Global:
We’re proud to highlight our partners at Forge Global, who are helping the world’s most innovative private companies and their teams gain #liquidcourage on their terms. Learn more here.
De'Longhi
@athenago
@Polymarket




E
Karpathy asked. I delivered.
Introducing OpenSquirrel!
Written in pure rust with GPUI (same as zed) but with agents as central unit rather than files. Supports Claude Code, Codex, Opencode, and Cursor (cli). This really forced me to think up the UI/UX from first principles instead of relying on common electron slop.
https://t.co/NQG1jvgbk5
K
karpathy
@karpathy
Expectation: the age of the IDE is over Reality: we’re going to need a bigger IDE (imo). It just looks very different because humans now move upwards and program at a higher level - the basic unit of interest is not one file but one agent. It’s still programming.
B
People are undoubtedly a little alarmed at having unwittingly helped build a 3D map of the world for Niantic by contributing 30 billion crowdsourced images. I interviewed Niantic's CTO Brian McClendon about exactly this in a TED interview last year -- he's also the guy who co-created Google Earth.
But let's put it in perspective. Pokestop data isn't what you think it is. It's not a surveillance panopticon of your neighborhood. These are static captures of parks, statues, murals, landmarks -- the places people congregate. Brian described it as "building the map from the bottom up, from the locations where people spend time."
Think of these 20 million waypoints as basically the inverse of what Google mapped with Street View. Google mapped the drivable streets. Niantic mapped where people actually hang out. Cool data, genuinely useful for visual positioning -- but very different from what the headlines imply.
And lest we forget that Niantic is just one of many companies quietly building their own map of the world right now -- and they're all capturing different facets of reality:
>🚶 person-level: Axon body cams on hundreds of thousands of officers. Meta Ray-Ban glasses capturing first-person POV at scale -- overseas operators reviewing images every time someone says "Hey Meta."
> 🚗 vehicle-level: Tesla dashcams on every car in the fleet, massive onboard compute extracting and distilling data to the cloud. Waymo with cm-accurate 3D maps of every city they operate in. Fleet telematics cameras on delivery vehicles globally.
> 🏠 street & home-level: Flock Safety deploying CCTV across neighborhoods and cities. Amazon with Ring cameras on every doorstep and mailroom (recently got dragged over that Super Bowl commercial about fusing all these cams together to find your dog) plus dashcams on every Prime delivery van. Roomba mapping your floor plan every time it vacuums -- Amazon wanted that data badly enough to try acquiring iRobot for $1.7B before regulators shut it down.
> 🥽 headset-level: Apple Vision Pro and Meta Quest build a 3D model of whatever room you're in every time you put them on. Between Ring, Roomba, and your headset, your entire home is being spatially understood by at least three different companies.
>📍platform-level: Google with Street View cars, aerial planes, satellite imagery, and live location from every Android phone in your pocket. Apple doing the same with mapping cars AND every LiDAR iPhone is quietly a 3D scanner. And yeah, despite the "Apple is too privacy-conscious" narrative, they're collecting location data too.
>🏃 trajectory-level: Strava mapped every running and cycling trail on Earth -- and accidentally exposed secret military bases in Afghanistan and Syria because soldiers logged their jogs. When you aggregate enough individual trajectories, patterns emerge that were never supposed to be visible.
> 🛰️ space-level: Planet Labs imaging the entire Earth's landmass every single day from orbit. Vantor capturing it in higher detail. Iceye doing it in 3D using SAR. If something changes anywhere on the planet -- a building goes up, a forest burns down, a military convoy moves -- before-and-after imagery within 24 hours.
Fused together -- we have everything from body cam to dashcam to doorbell to phone to satellite -- every layer of physical reality is being mapped by somebody right now. Different sensors, different angles, different purposes. Same pattern.
The interesting part is how they incentivize it. Google spends billions. Mapillary tried altruism. Hivemapper grinds with crypto. Pokémon GO cracked something none of them could: a game mechanic that subsidizes the scanning behavior. You're not building a map. You're catching pokemon. The map is just a side effect.
3D scanning is still a niche hobby for reality capture nerds like me. The moment somebody gamifies dense 3D capture at scale -- not posed photos but actual geometry -- that's when this blows wide open.
Niantic sold the games for $3.5B but kept the spatial platform, with a data-sharing agreement in place. One team makes the game great, the other builds the spatial infrastructure underneath. Incentives finally aligned.
Gaming is becoming a way for humans to contribute real-world trajectories that help physical AI learn about the real world. Google does it with live traffic. Tesla does it with autopilot. The mechanic is different but the pattern is identical -- and most people are already part of at least one -- if not a majority -- of these datasets whether they realize it or not.

M
markgadala
@markgadala
This is wild. 143 million people thought they were catching Pokémon. They were actually building one of the largest real-world visual datasets in AI history. Niantic just disclosed that photos and AR scans collected through Pokémon Go have produced a dataset of over 30 billion real-world images. The company is now using that data to power visual navigation AI for delivery robots. Players didn't just walk around with their phones. They scanned landmarks, storefronts, parks, and sidewalks from every angle, at every time of day, in lighting and weather conditions that staged photography would never capture. They documented the physical world at a scale no mapping company with a fleet of vehicles could have replicated on the same timeline or budget. Niantic collected this systematically, data point by data point, across eight years, while users thought the only thing at stake was catching a rare Charizard. The most valuable AI training datasets in the world aren't being assembled in data centers. They're being built by people who have no idea they're building them.
J
I want to show how I go about planning major new features for my existing projects, because I've heard from many people that they are confused by my extreme emphasis on up-front planning. They object that they don't really know all the requirements at the beginning, and need the flexibility to be able to change things later.
And that isn't at all in tension with my approach, as I hope to illustrate here. So I decided that it would be useful to add some kind of robust, feature-packed messaging substrate to my Asupersync project. I wanted to use as my model of messaging the NATS project that has been around for years and which is implemented in Golang.
But I didn't want to just do a straightforward porting of NATS and bolt it onto asupersync; I wanted to reimagine it all in a way that fully leverages asupersync's correct-by-design structured concurrency primitives to do things that just aren't possible in NATS or other popular messaging systems.
I used GPT 5.4 with Extra High reasoning in Codex-CLI, and took a session that was already underway so that the model would already have a good sense of the asupersync project and what it's all about. Then I used the following prompts shown below; where I indicated "5x," that means that I repeated the prompt 5 times in a row:
```
› I want you to clone https://t.co/kfBMj4sUov to tmp and then investigate it and look for useful ideas that we can take from that and reimagine in highly accretive ways on top of existing asupersync primitives that really leverage the special, innovative concepts and value-add from both projects to make something truly special and radically innovative. Write up a proposal document, PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC.md
› OK, that's a decent start, but you barely scratched the surface here. You must go way deeper and think more profoundly and with more ambition and boldness and come up with things that are legitimately "radically innovative" and disruptive because they are so compelling, useful, accretive, etc.
› Now "invert" the analysis: what are things that we can do because we are starting with "correct by design/structure" concurrency primitives, sporks, etc. and the ability to reason about complex concurrency issues using something analogous to algebra, that NATS simply could never do even if they wanted to because they are working from far less rich primitives that do not offer the sort of guarantees we have and the ability to analyze things algebraically in a precise, provably correct manner?
5x: › Look over everything in the proposal for blunders, mistakes, misconceptions, logical flaws, errors of omission, oversights, sloppy thinking, etc.
› OK, now nats is fundamentally a client-server architecture. Can you think of a clever, radically innovative way that leverage the unique capabilities and features/functionality of asupersync so that the Asupersync Messaging Substrate doesn't require a separate external server, but each client can self-discover or be given a list of nodes to connect to, and they can self-negotiate and collectively act as both client and server? Ideally this would also profoundly integrate with and leverage the RaptorQ functionality already present in asupersync
5x: › Look over everything in the proposal for blunders, mistakes, misconceptions, logical flaws, errors of omission, oversights, sloppy thinking, etc.
[Note: the two bullet points included in this next prompt come from a response to a previous prompt]
› OK so then add this stuff to the proposal, using the very smartest ideas from your alien skills to inform it and your best judgment based on the very latest and smartest academic research:
- The proposal is now honest that a brokerless fabric needs epoch/lease fencing, but it still does not choose the exact control-capsule algorithm. That should be a follow-on design memo: per-cell Raft-like quorum, lease-quorum with fenced epochs, or a more specialized protocol.
- The document now names witness-safe envelope keying, but key derivation/rotation/revocation semantics are still only sketched. That is the next major design surface, not a remaining blunder in this pass.
› OK now we need to make the proposal self-contained so that we can show it to another model such as GPT Pro and have that model understand absolutely anything that might be relevant to understanding and being able to suggest useful revisions to the proposal or to find flaws in the plans. To that end, I need you to add comprehensive background sections about what asupersync is and how it works, what makes it special/compelling, etc. And then do the same in another background section all about NATS and what it is and what makes it special/compelling, how it works, etc.
5x: › Look over everything in the proposal for blunders, mistakes, misconceptions, logical flaws, errors of omission, oversights, sloppy thinking, etc.
› apply $ de-slopify to PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC.md
```
This resulted in the plan file shown here:
https://t.co/xWpVMpC98b
But before I started turning that plan into self-contained, comprehensive, granular beads for implementation, I first wanted to subject the plan to feedback from GPT 5.4 Pro with Extended Reasoning, and also feedback from Gemini 3 with Deep Think, Claude Opus 4.6 with Extended Reasoning from the web app, and Grok 4.2 Heavy.
I used this prompt for the first round of this:
```
How can we improve this proposal to make it smarter and better-- to make the most radically innovative and accretive and useful and compelling additions and revisions you can possibly imagine. Give me your proposed changes in the form of git-diff style changes against the file below, which is named PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC.md:
```
I used the same prompt in all four models, then I took the output of the other 3 and pasted them as a follow-up message in my conversation with GPT Pro using this prompt that I've shared before:
```
I asked 3 competing LLMs to do the exact same thing and they came up with pretty different plans which you can read below. I want you to REALLY carefully analyze their plans with an open mind and be intellectually honest about what they did that's better than your plan. Then I want you to come up with the best possible revisions to your plan (you should simply update your existing document for your original plan with the revisions) that artfully and skillfully blends the "best of all worlds" to create a true, ultimate, superior hybrid version of the plan that best achieves our stated goals and will work the best in real-world practice to solve the problems we are facing and our overarching goals while ensuring the extreme success of the enterprise as best as possible; you should provide me with a complete series of git-diff style changes to your original plan to turn it into the new, enhanced, much longer and detailed plan that integrates the best of all the plans with every good idea included (you don't need to mention which ideas came from which models in the final revised enhanced plan); since you gave me git-diff style changes versus my original document above, you can simply revise those diffs to reflect the new ideas you want to take from these competing LLMs (if any):
gemini:
---
claude:
---
grok:
```
You can see the entire shared conversation with GPT Pro here:
https://t.co/2Io2yevq5b
I then took the output of that and pasted it into Codex with this prompt:
```
› ok I have diffs that I need you to apply to PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC.md but save the result instead to PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC__AFTER_FEEDBACK.md :
```
and then did:
› apply $ de-slopify to the PROPOSAL_TO_INTEGRATE_IDEAS_FROM_NATS_INTO_ASUPERSYNC__AFTER_FEEDBACK.md file
The final result can be seen here:
https://t.co/ydTfh588Iw

B
TIRED OF YOUR AGENTS PRODUCING DESIGN SLOP?
INTRODUCING TLA PRECHECK ✅
THIS TOOL MAKES IT MATHEMATICALLY IMPOSSIBLE FOR AGENTS TO PRODUCE BUGGY DESIGN!
It comes with a skill for Claude Code & Codex for them to do this for you! Install guide in replies :) 👇 https://t.co/01L6mVa5ND

T
The last time a Chinese lab open-sourced something this big, Nvidia lost $600 billion in a single day.
It's happening again.
DeepSeek panicked Silicon Valley in January. Crashed Nvidia's stock $600B in one day. Made Sam Altman rewrite his entire business plan.
Now there's a second one.
Kimi just made AI notably cheaper to run. Open-sourced it. Put it out for free. Meanwhile OpenAI is asking people to pay $200 a month to use a model that already feels behind the curve.
Two Chinese labs. Both open source. Both doing more with less. Both giving away for free what American companies charge billions for.
The AI race isn't US vs China anymore... It's closed vs open. And closed is losing.
And the wildest part? Nobody in Silicon Valley will quote tweet this.. Because admitting a Chinese lab just moved the field forward for free destroys the entire "we need $10B to build AGI" fundraising pitch.

K
Kimi_Moonshot
@Kimi_Moonshot
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: https://t.co/u3EHICG05h
M
What alternatives are there to docker sandbox for sandboxing Claude Code?
It's unreliable as hell on WSL.
/sandbox doesn't do what I want - cc can always get around it and it doesn't allow for properly AFK workflows.