Karpathy Maps AI Job Exposure Across 342 Occupations as Agent Memory Systems Get a Major Rethink
The AI community is deep in the weeds on agent infrastructure, with ByteDance's OpenViking proposing a file-system metaphor for agent memory and multiple projects pushing local inference forward. Andrej Karpathy's AI job exposure scoring project sparked widespread conversation, while Claude Code's ecosystem continues to expand with local GPU support and marketing applications.
Daily Wrap-Up
The conversation today orbited around a central tension: AI agents are getting dramatically more capable, but the infrastructure to make them reliable is still being figured out in real time. ByteDance open-sourced OpenViking to treat agent context like a file system instead of a flat vector store. Cognee shipped self-healing skills that watch their own failures. A new terminal called Slate is trying to wrangle multi-model agent swarms into something usable. Everyone agrees agents are the future, but nobody agrees on the plumbing yet.
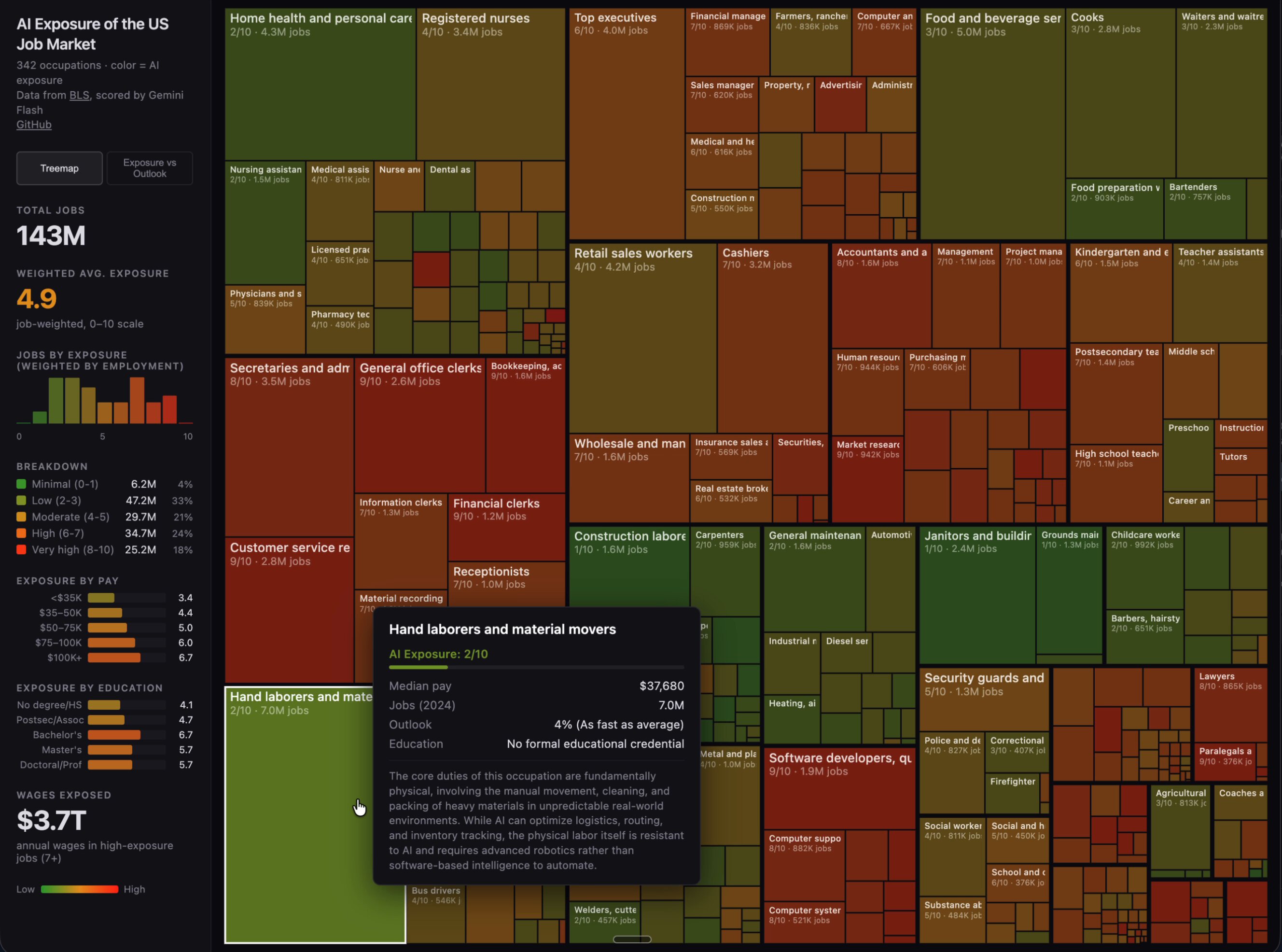
Meanwhile, Andrej Karpathy quietly dropped one of the more sobering projects of the week: an LLM-scored breakdown of all 342 Bureau of Labor occupations ranked by AI exposure. Software developers landed at 8-9 out of 10. The average across all jobs was 5.3. That number landed differently depending on who was reading it, but the fact that the entire pipeline is open source means anyone can audit or challenge the methodology. It's the kind of project that matters more for the conversation it starts than the scores it assigns. On the lighter side, someone apparently sold their entire house in five days using ChatGPT, which Greg Brockman quote-tweeted with the energy of a proud parent.
The most practical takeaway for developers: if you're building with AI agents, study OpenViking's tiered loading architecture (L0/L1/L2 context levels) and consider whether your current approach of dumping everything into context is costing you both tokens and accuracy. The file-system metaphor for agent memory is emerging as a pattern worth understanding now.
Quick Hits
- @Crypto0637 shared Superheat's $2,000 electric water heater with built-in ASIC Bitcoin miners. Same energy usage, but it mines crypto while heating your water. The future of appliances is weird.
- @5le recommends a portable charger that can juice up a MacBook on the go.
- @OwlcatGames announced an action RPG based on The Expanse, now available to wishlist on Steam.
- @nateliason and Cameron Sorsby are launching a high school for entrepreneurs with a wild promise: make $1M by graduation or get full tuition refunded.
- @doodlestein shared an apparently excellent prompt with no further context. The image did the talking.
- @TheAhmadOsman flexed what can only be described as the final boss of LocalLLaMA home server setups.
- @unusual_whales published a guide for connecting OpenClaw agents to real-time stock and options data.
- @RayFernando1337 told the story of being pulled into Apple's secret Apple Watch update system project, back when the prototype had no recovery port.
- @gdb quote-tweeted the ChatGPT house-selling story with a note about building confidence through AI usage.
Agent Memory and Infrastructure
The biggest technical theme today was rethinking how AI agents manage context and memory. The flat RAG paradigm, where you embed everything and do a similarity search, is showing its cracks at scale. @ihtesham2005 broke down ByteDance's OpenViking framework, which organizes agent context under a unified viking:// protocol: "Memories, resources, skills all organized in directories with unique URIs. Agents can ls, find, and navigate context like a developer working a terminal." The tiered loading system is the real innovation here, with L0 providing one-sentence abstracts, L1 offering ~2k token overviews for planning, and L2 loading full details only when needed. Most agents today stuff everything into context and hope for the best. This approach loads only what's relevant, when it's relevant.
On a parallel track, @iruletheworldmo highlighted Cognee's work on self-improving agent skills that "observe their own failures, inspect what went wrong, and amend themselves automatically." And @steipete pointed to community plugins solving memory problems in OpenClaw, specifically the qmd memory plugin for agents that get forgetful after context compaction. @browser_use retweeted research on when to apply compaction to agent conversations, claiming an 80% cost reduction. These aren't competing ideas so much as different layers of the same problem: agents need better memory, better context management, and ideally the ability to learn from their own mistakes. The community is converging on solutions from multiple angles.
Claude Code Ecosystem Expands
Claude Code dominated the conversation from multiple angles today. @techNmak covered Unsloth AI's guide to running Claude Code entirely on local GPUs, and the guide's value goes beyond the setup instructions. It explains why local inference feels slow (an attribution header breaks KV caching), why Qwen3.5 outputs degrade (f16 KV cache is the default but q8_0 or bf16 performs better), and how to disable thinking mode for agentic tasks. "Fits on 24GB. RTX 4090, Mac unified memory." That's a meaningful threshold for developers who want API independence.
@shannholmberg argued that Claude's superpowers plugin with 83,000 GitHub stars is "the most underrated plugin for marketers right now," noting that almost everyone using it is a developer. @mattpocockuk raised pointed questions about whether OAuth tokens from Claude subscriptions can legally power the Claude Agent SDK for local dev loops, and whether open-source tools built on that pattern can be distributed. The legal compliance docs and public statements from Anthropic appear to contradict each other, which is the kind of ambiguity that chills open-source development. @shanraisshan's best practices repo for Claude Code hit 11.8K stars, and @shareAI-lab's "build a Claude Code clone from scratch" repo reached 9K. The ecosystem is maturing fast, but governance questions are trailing behind the code.
AI's Impact on Jobs and Careers
Karpathy's job exposure project was the most discussed single item today. @JoshKale summarized the methodology: "Scraped all 342 occupations from the Bureau of Labor. Fed each one to an LLM with a detailed scoring rubric. Built an interactive treemap where rectangle size = number of jobs and color = how exposed that job is to AI." The key heuristic is straightforward: if the work product is digital and the job can be done from home, exposure is high. Software developers scored 8-9. Medical transcriptionists scored a perfect 10. Roofers and janitors scored 0-1. The average was 5.3 out of 10 across all occupations.
@TukiFromKL amplified the anxiety with a rapid-fire roundup that included a CEO of a $200 billion company saying "35% of new grads won't find jobs" on camera without flinching, and Meta firing 15,000 people despite $165 billion in revenue. The juxtaposition of AI capability stories (curing a dog's cancer, selling a house in five days) against job displacement data creates a disorienting effect. These aren't abstract trends anymore. They're landing in specific occupations with specific exposure scores, and the entire scoring pipeline is open source for anyone to verify.
Agentic Workflows and Tooling
Developers are actively experimenting with how to orchestrate AI agents in practice. @jamonholmgren teased what he calls the "Night Shift workflow," claiming it's "about 5x faster, better quality, I understand the system better, and I'm having fun again." He contrasted it with previous workflows that "left me exhausted, overwhelmed, and feeling out of touch with the systems I was building." Details are still forthcoming, but the sentiment resonates: raw speed from agents isn't enough if the developer loses comprehension of their own codebase.
@realmcore_ showed off Slate, a terminal UX designed for agent swarms that lets you "literally use Opus 4.6 and GPT 5.4 at the exact same time." Making multi-model orchestration intuitive is a hard UX problem, and most existing terminals aren't built for it. @victormustar demonstrated a different approach, using the Hugging Face CLI as the sole interface for an autonomous AI engineering agent. The agent autonomously fine-tuned a model for Japanese, running 23 SQL queries to audit data quality across 153K examples before curating 4,096 training samples. "Feels less contaminating: an agent browsing the web for solutions would defeat the whole purpose of autoresearch."
Trending Open Source Projects
@sharbel compiled this month's fastest-growing GitHub projects, and the list reads like a snapshot of where developer energy is flowing. OpenClaw leads at 122K stars as a personal AI assistant. Superpowers hit 30.7K stars as a plug-and-play agent skills framework. But the more surprising entries tell a bigger story: RuView (30.4K stars) turns regular WiFi signals into real-time human pose detection with no cameras or sensors. MiroFish (17K stars) bills itself as a "swarm intelligence engine that predicts anything," and @k1rallik noted that its creator, a student, "outranked OpenAI on GitHub with 10 days of vibe coding." And then there's Heretic at 7.6K stars, which "removes guardrails from any language model automatically." The open-source AI ecosystem is moving fast enough that next month's list will look completely different.
Knowledge Management with AI
@Atenov_D published a detailed breakdown of a "10x learning speed" setup that chains NotebookLM, Google Drive, Obsidian with Smart Connections, and Claude Code into a continuous knowledge processing pipeline. The core insight is that breaking information into atomic notes (one idea per file, tagged and cross-linked) isn't just organization but is the learning itself: "When you open a note weeks later and see three related ideas you'd forgotten, that's active recall. That's what builds memory." Omar Khattab (@lateinteraction) retweeted a related project where someone used DSPy and RLM to automatically refactor a messy Obsidian vault. The pattern emerging here is that AI isn't just helping people consume information faster; it's restructuring how knowledge gets stored and retrieved in ways that compound over time.
Sources


We’re launching a new @alphaschoolatx high school for aspiring entrepreneurs. Our promise: Make $1m by graduation, or receive a full tuition refund. Yes, this will be the coolest high school in the world. And we're building the best team in the world to make it happen. We’re looking for 2-3 exceptional coaches to help us guide the students towards achieving this aggressive but achievable goal. You won’t be giving lectures or assigning homework. You’ll be grilling them on their P&L, driving them to the car wash they bought, critiquing their email funnels, pushing them to do things 99% of the world doesn't believe is possible. Job posting is live and DMs are open.



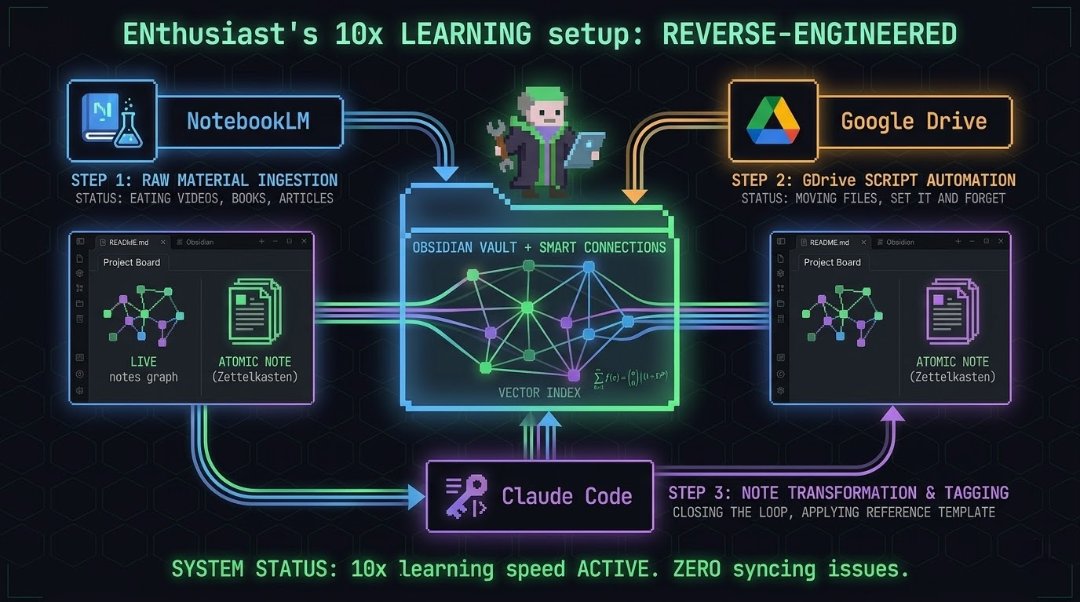
How I turned Obsidian into a second brain that runs itself


MiroFish: The God View Engine

Self improving skills for agents

Florida man sold his house in just 5 days after letting ChatGPT handle the entire process instead of a real estate agent The AI handled pricing, marketing, showings, and even helped draft the contract https://t.co/t5BfIGN9lZ
Autoresearch: make Qwen 0.5B better at chess 👀 tip: you can /loop claude on the Pi session so it does a nice reporting of what's happening every 15 minutes https://t.co/tqYAZeQcXS