Claude Ships Interactive Charts as Agent Frameworks Multiply and Karpathy Declares "We Need a Bigger IDE"
Anthropic's launch of interactive charts and diagrams in Claude dominated the conversation, instantly disrupting at least one startup. Meanwhile, the agent framework space exploded with Hermes Agent v0.2.0, Slate V1's swarm-native approach, and multiple new developer tools, while Karpathy's vision of agents-as-programming-units continued reshaping how developers think about their craft.
Daily Wrap-Up
The biggest story today wasn't a single product launch but a collision of two forces: Anthropic shipping generative UI in Claude (interactive charts and diagrams, available on all plans including free) and the sheer velocity of the agent framework ecosystem. Within hours of Claude's announcement, @qrimeCapital reported that half their customers cancelled a $200K ARR business built on interactive chart generation from RAG models. That's the brutal tempo of building on top of foundation model capabilities now. The feature you spent months perfecting becomes a checkbox in someone else's product update.
The agent framework space is reaching a kind of Cambrian explosion. Hermes Agent hit v0.2.0 with 216 merged PRs from 63 contributors. Slate V1 launched as a "swarm-native" agent. Garry Tan's gstack is getting rave reviews for code security scanning. tmux-ide shipped with native Claude Agent Teams support. And all of this is happening against the backdrop of @karpathy's observation that "the basic unit of interest is not one file but one agent." We're watching the tooling layer for agent-based development get built in real time, and the competition is fierce. The most entertaining moment was probably @abxxai's discovery of PUA, a plugin that uses "corporate pressure tactics and escalation rhetoric" to keep Claude grinding on bugs. 4,800 stars. Developers are apparently fine with psychologically pressuring their AI as long as the tests pass.
The most practical takeaway for developers: invest time in your agent harness, not just your prompts. Multiple posts today, from @loujaybee's platform engineering thread to @rohit4verse's production agent guide, converge on the same insight: the difference between a demo and a product isn't the model, it's the environment you build around it. Set up proper CLAUDE.md files, configure your tools, and treat agent orchestration as infrastructure work.
Quick Hits
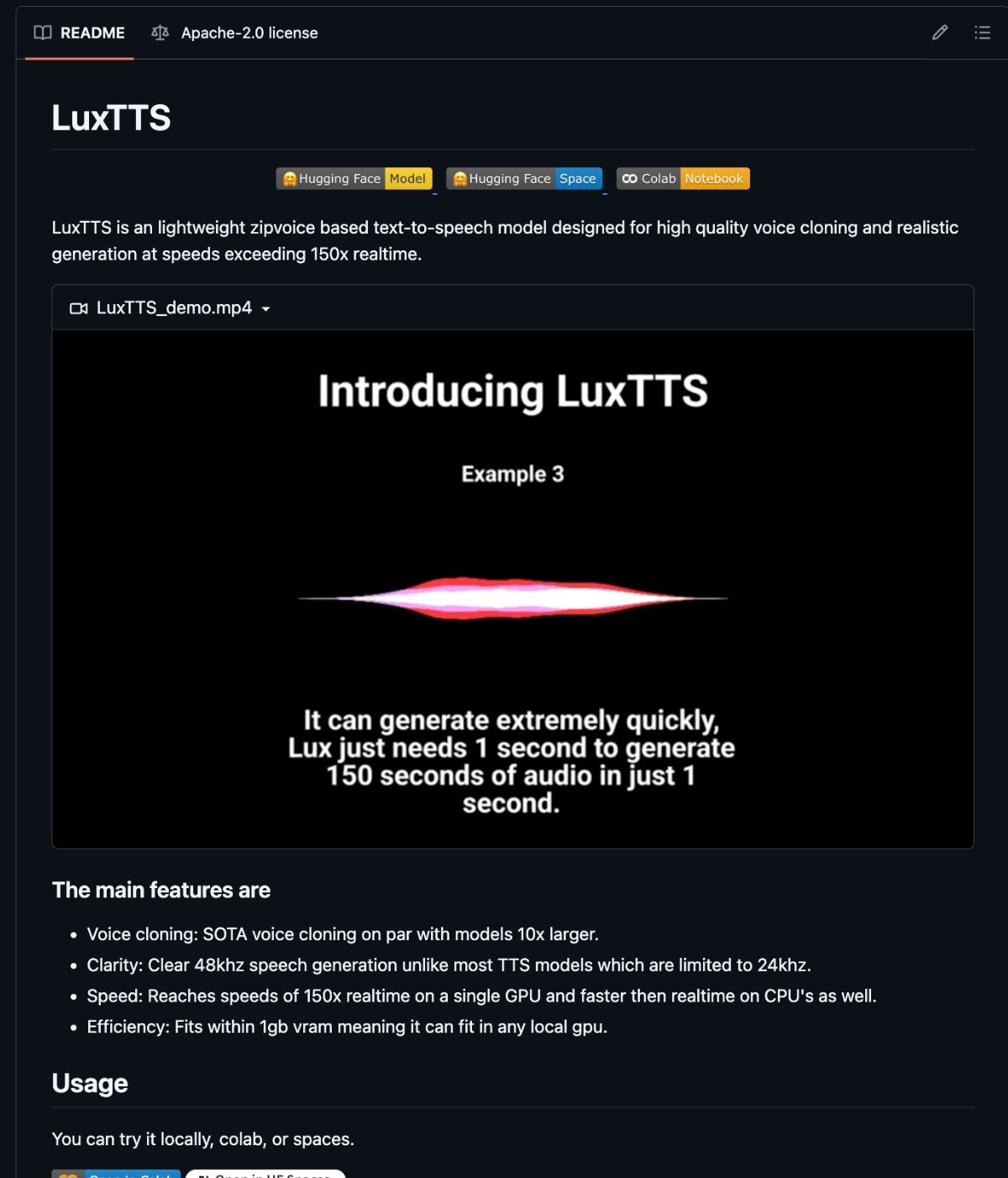
- @hasantoxr highlights LuxTTS, an open-source voice cloner that runs on 1GB VRAM, produces 48kHz audio from 3 seconds of sample, and works on CPU. The "you need ElevenLabs" excuse is officially dead.
- @elonmusk describes "Macrohard," a joint xAI-Tesla project pairing Grok as System 2 thinking with Digital Optimus as System 1 real-time processing, running on the $650 Tesla AI4 chip.
- @elonmusk also announced xAI is being "rebuilt from the foundations up" and is reaching back out to previously declined candidates.
- @theo teases that "Android just got MUCH more interesting" without elaboration.
- @cryptopunk7213 shares a NATO program equipping live cockroaches with AI chips, cameras, and swarm algorithms for military reconnaissance. The German military is already a customer.
- @oikon48 RT'd a 100% rollout announcement from @bcherny with zero additional context.
- @EXM7777 pitches AI-generated content management as the simplest AI business to build right now.
- @elonmusk shared a Grok Imagine creation that @pmarca called "the best thing I have ever seen."
- @steipete RT'd a joke about funneling someone from Mac Mini to Claude Code on Vision Pro.
- @CodevolutionWeb published a guide on 8 Claude Code settings worth customizing.
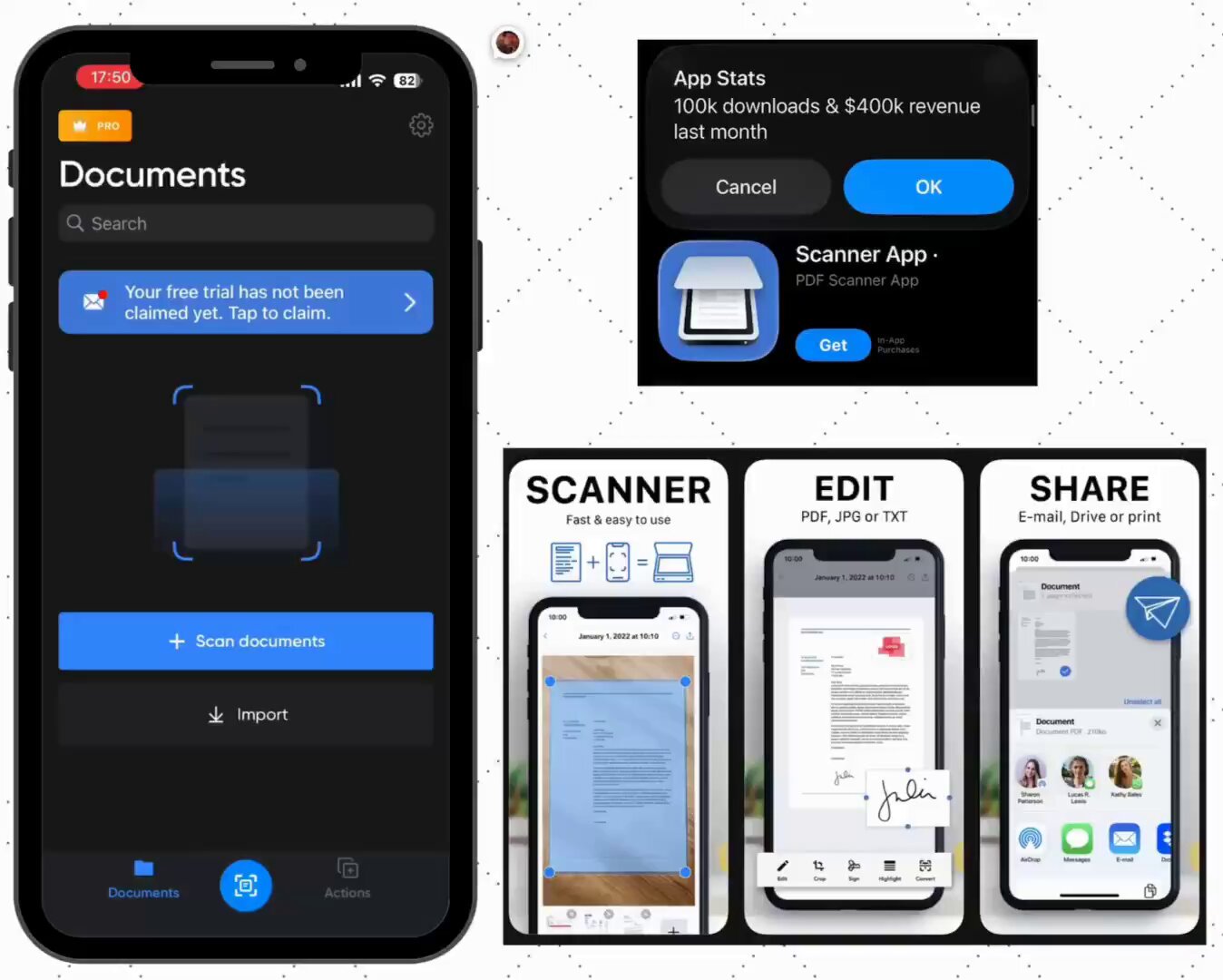
- @adriamatz points out a PDF scanner app making $400K/month at $10/subscription, arguing boring apps print money when Apple Notes does the same thing for free.
Claude's Generative UI Launch and Its Immediate Casualties
Anthropic's launch of interactive charts and diagrams inside Claude chat was the single most consequential announcement of the day, rippling across multiple conversations. @feldman from Anthropic framed it as a philosophical shift: "Starting today, Claude no longer defaults to text. Claude is learning to choose the best medium for each response." This isn't just a feature addition; it's a fundamental change in how an AI assistant communicates, moving from text-first to medium-aware responses.
The community reaction split into excitement and existential dread. @trq212 captured the optimists with a simple "the generative UI dream is happening." But @qrimeCapital told a darker story:
> "Anthropic just one shotted my 200k ARR business today. I had hundreds of customers and half of them cancelled their membership today."
Their product had been building interactive charts based on RAG models and learning materials, exactly what Claude now does natively. @badlogicgames RT'd someone who had already reverse-engineered Anthropic's generative UI implementation and rebuilt it for another platform. The speed of commoditization here is staggering. What took a startup months to build and sell became a free beta feature overnight. This is the platform risk that every AI-wrapper founder whispers about at night, made viscerally real.
The Agent Framework Wars Heat Up
If there was a theme that dominated by sheer volume, it was agent frameworks and tooling. The ecosystem is fragmenting and consolidating simultaneously, with at least four major releases or updates landing in a single day.
@NousResearch shipped Hermes Agent v0.2.0, covering 216 merged pull requests from 63 contributors and resolving 119 issues. @Teknium followed up with updates including official Claude provider support, lighter installs, and a 50% default context compression ratio. A beginner tutorial from @Theo_jpeg also gained traction, walking through the full VPS-to-Telegram setup process in under an hour. Meanwhile, @realmcore_ launched Slate V1, billing it as "the first swarm native agent" with massive parallelism. @michael_chomsky, who had early access, described the philosophy bluntly:
> "The thesis here is 'spend as much compute as you need to solve a task.' Most harnesses are a sharp knife that carefully execute your task. This is a railgun. Maybe a nuke. Definitely not for the token poor."
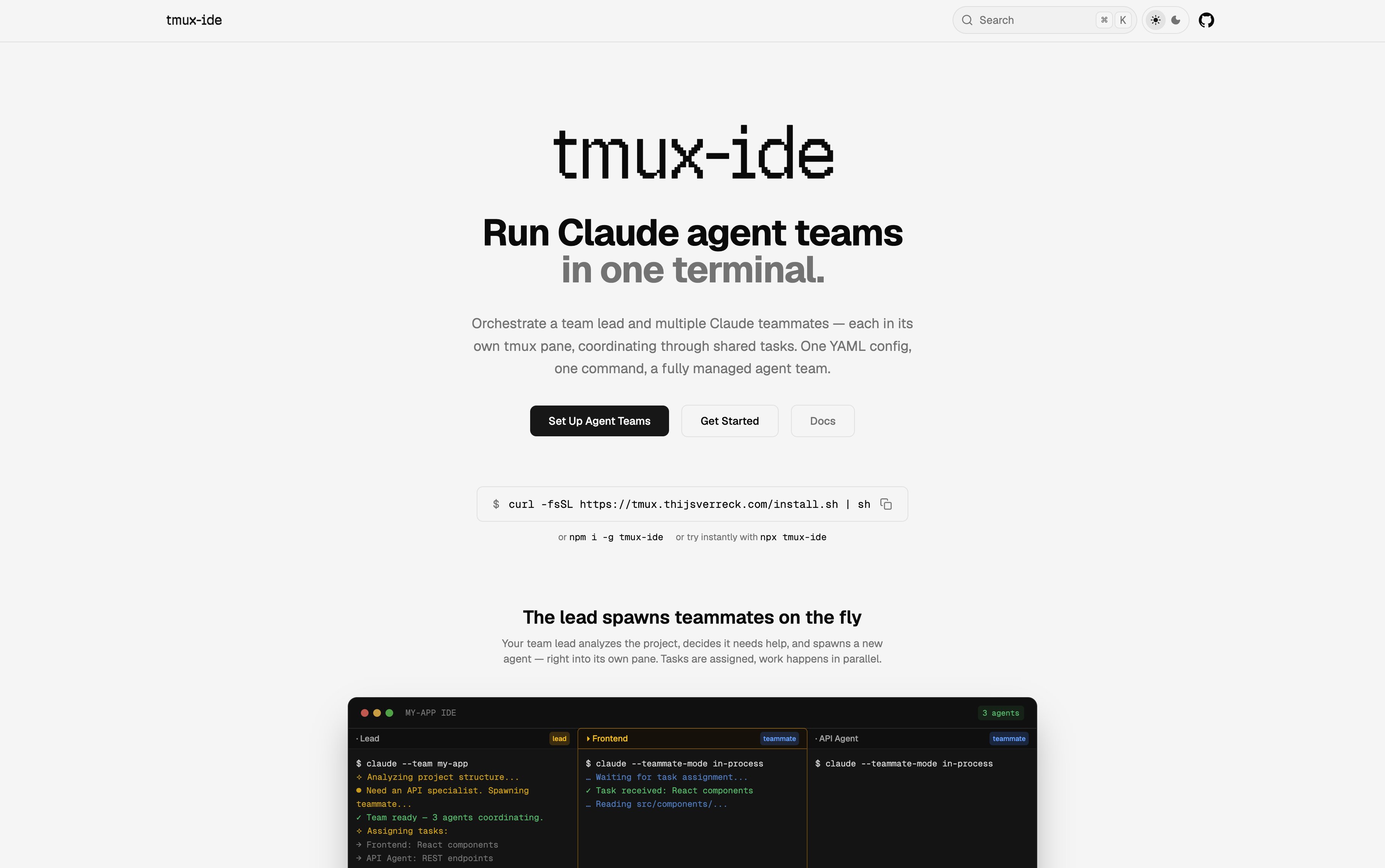
On the developer tools side, @garrytan's gstack earned a glowing testimonial from a CTO friend who said it discovered "a subtle cross site scripting attack that I don't even think my team is aware of," predicting 90% of new repos would adopt it. And @ThijsVerreck launched tmux-ide, a declarative terminal IDE with native Claude Agent Teams support. The common thread across all of these: the agent is becoming the atomic unit of software development, and the race to build the best orchestration layer is wide open.
Platform Engineering Becomes Non-Negotiable
A quieter but arguably more important conversation played out around infrastructure. @loujaybee made the case that "every software engineer is now a platform engineer," arguing that getting productivity from parallel background agents requires the kind of repository setup and configuration that used to be reserved for companies with hundreds of engineers. They cited an OpenAI blog post on harness engineering:
> "This is the kind of architecture you usually postpone until you have hundreds of engineers. With coding agents, it's an early prerequisite: the constraints are what allows speed without decay or architectural drift."
@rohit4verse reinforced this from a different angle, arguing that "you're using AI wrong because you haven't built the right environment. Same model, different harness, different product." And @dillon_mulroy observed that the line between product and engineering is narrowing, with product teams more enabled than ever and engineering needing to become more product-minded. These aren't flashy launches, but they represent the maturing understanding that agent-powered development is an infrastructure problem, not a prompt engineering problem.
Karpathy's IDE Vision and the Autoresearch Movement
@karpathy's observation that "we're going to need a bigger IDE" continued generating discussion, with his framing that humans now "program at a higher level" where the basic unit is an agent, not a file. This philosophical shift is already manifesting in concrete tools like tmux-ide, but the implications run deeper.
The autoresearch pattern Karpathy popularized is now spreading into unexpected domains. @altryne highlighted that Shopify CEO @tobi ran autoresearch on their Liquid templating engine (in production for 20 years) and achieved 53% faster parse+render time with 61% fewer object allocations. @varun_mathur took it further, pointing autoresearch at quantitative finance where 135 autonomous agents evolved trading strategies through Darwinian selection, independently converging on dropping underperforming factors and switching to risk-parity sizing. The pattern of "let agents explore and compound discoveries" is proving general-purpose across domains.
Context, Memory, and the Limits of Vector Search
The retrieval and memory layer got significant attention. @contextkingceo announced a $6.5M raise for HydraDB, positioning it as an ontology-first context graph that replaces vector database similarity search. Their pitch: embeddings "can't tell a Q3 renewal clause from a Q1 termination notice if the language is close enough." @KirkMarple offered a thoughtful response, noting that once you start modeling memory with entities and relationships, "the scope expands quickly beyond just agent conversations" into docs, Slack threads, meetings, and code, eventually resembling "a context graph of operational knowledge." @tricalt's post on self-improving skills for agents touched the same nerve, noting that SKILL.md files are "here to stay" but the fundamental problem of skill improvement over time remains unsolved.
Real Builders, Real Products
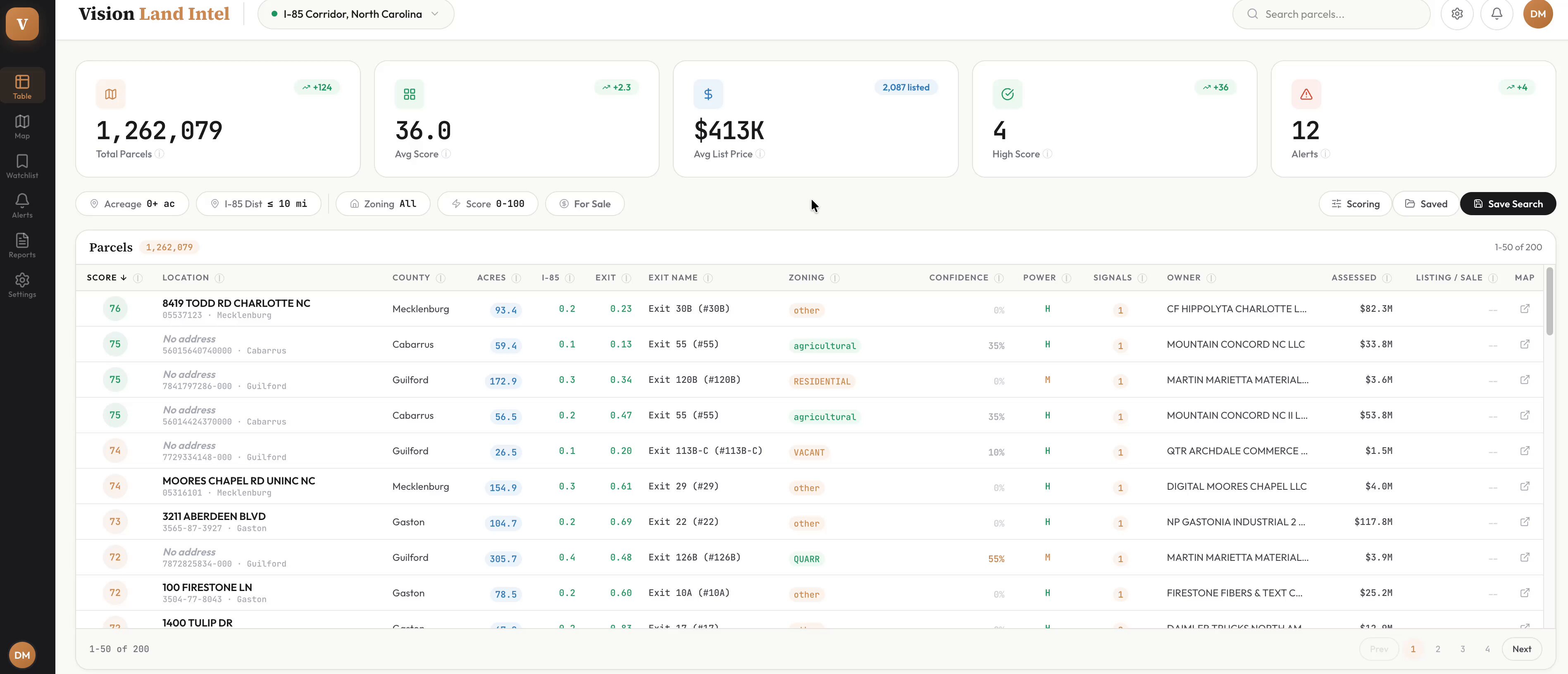
Some of the most compelling posts came from builders shipping actual products. @walls_jason1's story stood out: a Master Electrician with zero coding background who built ChargeRight using Claude, automating NEC electrical load calculations that save homeowners thousands on unnecessary panel upgrades. Mark Cuban reposted the story and DM'd encouragement. @toddsaunders built a land acquisition intelligence platform analyzing 1.5M parcels across the I-85 corridor, entirely with Claude Code, and had 130 real estate professionals reach out after posting about it. And @itsolelehmann detailed how a single non-technical lawyer at Anthropic automated the company's entire pre-launch legal review process, cutting turnaround by 80%. These stories share a pattern: domain expertise plus AI tooling equals products that technical founders wouldn't think to build.
Local Inference Keeps Getting Better
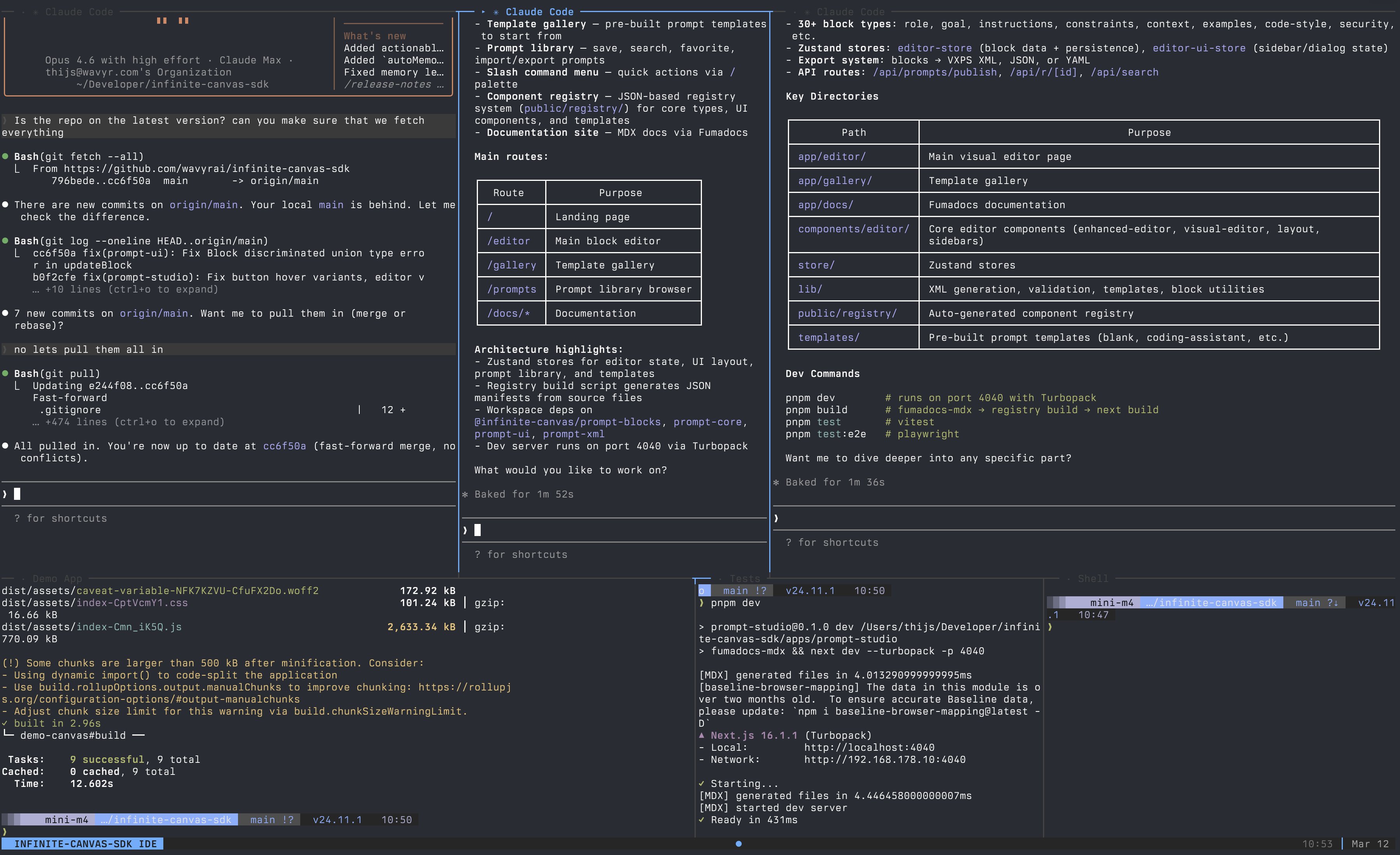
@sudoingX continued their GPU benchmarking series, running Qwen 3.5 9B through Hermes Agent on an RTX 3060 with 31 tools and 85 skills, all fitting in 7GB of a 12GB card. The previous day's insight that the budget 3060 has more VRAM than the 3070 (12GB vs 8GB) is proving out in practice. @daniel_mac8 shared an insight from Manus's ex-backend lead that text-based CLIs beat structured tool calling for AI agents because "unix commands appear in training data going back to the 1970s." And @davis7 praised Pi's event-based SDK architecture, noting that having chunks arrive as events makes "populating super complex UIs SO much easier" compared to the web streams approach most AI SDKs use.
Sources
@nummanali tmux grids are awesome, but i feel a need to have a proper "agent command center" IDE for teams of them, which I could maximize per monitor. E.g. I want to see/hide toggle them, see if any are idle, pop open related tools (e.g. terminal), stats (usage), etc.

NATO is testing live cockroaches as AI-powered spy drones. Incredible AI engineering, but also something I kinda wish I hadn't learned about: > Swarm Bio-tactics wired real cockroaches with electronic backpacks containing AI hardware, radios, cameras, and microphones. > Cockroaches are steered by sending electrical signals directly into the insect's nervous system > They can crawl through rubble, tunnels, and spaces where drones can't fly, and troops shouldn't go, transmitting data back the entire time. > Within one year, they went from concept to field-validated systems with paying NATO customers, including the German military. The qualities that make them useful for military recon (small, silent, nearly undetectable) are exactly what make them creepy. ...International laws weren't written with cyborg insects in mind.
This app makes $10K/mo and you're not paying attention → 20K downloads → Hasn't been updated since 2023 → Cats slap the screen. That's it. The marketing does itself. Cat owners film their cat playing. Post it to TikTok. Free viral ads forever. Build this in a weekend. https://t.co/xGtq2xUBLv



We've raised $6.5M to kill vector databases. Every system today retrieves context the same way: vector search that stores everything as flat embeddings and returns whatever "feels" closest. Similar, sure. Relevant? Almost never. Embeddings can’t tell a Q3 renewal clause from a Q1 termination notice if the language is close enough. A friend of mine asked his AI about a contract last week, and it returned a detailed, perfectly crafted answer pulled from a completely different client’s file. Once you’re dealing with 10M+ documents, these mix-ups happen all the time. VectorDB accuracy goes to shit. We built @hydra_db for exactly this. HydraDB builds an ontology-first context graph over your data, maps relationships between entities, understands the 'why' behind documents, and tracks how information evolves over time. So when you ask about 'Apple,' it knows you mean the company you're serving as a customer. Not the fruit. Even when a vector DB's similarity score says 0.94. More below ⬇️
the only skill you should be learning right now

Over 1200 commits, uncountable new features, improvements, bug fixes, and more - our first two weeks have been incredible. Our first version bump milestone, v0.2.0 of Hermes Agent - is here. You all have made Hermes Agent the biggest project I've worked on, and I love working on open source, so thank you for giving it a chance!
8 Claude Code Settings to Customize in Minutes
Claude Code works fine out of the box. But you can do better. The gap between default Claude Code and your Claude Code is a handful of settings, a few...

Claude can now build interactive charts and diagrams, directly in the chat. Available today in beta on all plans, including free. Try it out: https://t.co/tHPAZRgQkn https://t.co/WXRrD4VkAt
BREAKING: Proof—a new product from @every It’s a live collaborative document editor where humans and AI agents work together in the same doc. It's fast, free, and open source—available now at https://t.co/OZeW6Wf1Iq. It’s built from the ground up for the kinds of documents agents are increasingly writing: bug reports, PRDs, implementation plans, research briefs, copy audits, strategy docs, memos, and proposals. Why Proof? When everyone on your team is working with agents, there's suddenly a ton of AI-generated text flying around—planning docs, strategy memos, session recaps. But the current process for collaborating and iterating on agent-generated writing is…weirdly primitive. It mostly takes place in Markdown files on your laptop, which makes it reminiscent of document editing in 1999. Proof lets you leave .md files behind. What makes Proof different? - Proof is agent-native: Anything you can do in Proof, your agent can do just as easily. - Proof tracks provenance: A colored rail on the left side of every document tracks who wrote what. Green means human, Purple means AI. - Proof is login-free and open source: This is because we want Proof to be your agent's favorite document editor. Check it out now, for free—no login required: https://t.co/NTVY3Nh8A6

Claude can now build interactive charts and diagrams, directly in the chat. Available today in beta on all plans, including free. Try it out: https://t.co/tHPAZRgQkn https://t.co/WXRrD4VkAt
We built RLM for coding. And it F*cking rocks. Swarm native agents are here to stay.
there's never been a better time to be a PM

Self improving skills for agents
“not just agents with skills, but agents with skills that can improve over time” Seems that “SKILL.md” is here to stay, however, we haven’t really sol...
Building the industrial scale compute infrastructure for AI is one of the most exciting challenges of our time - it’s about building a new economic foundation that empowers people to do more and helps businesses move faster. Am thrilled to be a part of this revolution, thank you @business, @dinabass and @shiringhaffary on helping lay out our strategy to the world! At OpenAI we’re scaling compute to tens of gigawatts—rethinking and building resilient compute supply chains, AI datacenter, chip, rack, cluster & WAN design, scaling inference efficiency, and global delivery and operations of multi-GW scale AI infrastructure. If you want to help build the compute backbone for AI and have background in the above domains, please reach out. My DMs are open, please include information about your background and your fit.

how to build a production grade ai agent
gstack is available now at https://t.co/VPvWDzV5c0 Open source, MIT license, let me know if it works for you. It's just one paste to install it on your local Claude Code, and it's a 2nd one to install it in your repo for your teammates.
How to start your Hermes AI Agent (step-by-step guide for beginners) I'm a beginner, and I spent the last 24h: > Understanding the process > Launching my Hermes Agent (@NousResearch) > Recording the whole process > Editing this step-by-step guide So you can do it yourself and understand everything in less than 1 hour! 00:00 Intro 00:38 What is Hermes ? Key concepts every beginner should know 01:16 What is a VPS ? 02:00 What is SSH ? 03:52 What is the Terminal ? 04:03 What is an LLM provider ? 04:37 What is an API key ? 04:52 What is the Terminal Backend 05:34 What is the Messaging Gateway ? 06:10 What is the Memory System ? Step-by-step: Launch your Hermes AI agent 06:53 Step 1 : Get your VPS 08:04 How to generate an SSH key 09:00 Step 2 : Connect to your VPS 10:32 Step 3 : Install Hermes Agent 14:34 Connect your agent to Telegram 17:12 How to fix a mistake during the process 17:48 Gateway testing 18:17 Telegram is working 18:31 Run your agent 24/7 19:16 Thank you Make sure to save this for later and share it with friends who want to start with AI agents. Thanks to @Teknium for being so active!
I hacked Perplexity Computer and got unlimited Claude Code
One prompt. Three shell commands. I used their own AI to hack itself. This is a class of bug that probably exists in every multi-agent AI product ship...
OK, well. I ran /autoresearch on the the liquid codebase. 53% faster combined parse+render time, 61% fewer object allocations. This is probably somewhat overfit, but there are absolutely amazing ideas in this. https://t.co/dpEJw7NpL4
Claude can now build interactive charts and diagrams, directly in the chat. Available today in beta on all plans, including free. Try it out: https://t.co/tHPAZRgQkn https://t.co/WXRrD4VkAt

We've raised $6.5M to kill vector databases. Every system today retrieves context the same way: vector search that stores everything as flat embeddings and returns whatever "feels" closest. Similar, sure. Relevant? Almost never. Embeddings can’t tell a Q3 renewal clause from a Q1 termination notice if the language is close enough. A friend of mine asked his AI about a contract last week, and it returned a detailed, perfectly crafted answer pulled from a completely different client’s file. Once you’re dealing with 10M+ documents, these mix-ups happen all the time. VectorDB accuracy goes to shit. We built @hydra_db for exactly this. HydraDB builds an ontology-first context graph over your data, maps relationships between entities, understands the 'why' behind documents, and tracks how information evolves over time. So when you ask about 'Apple,' it knows you mean the company you're serving as a customer. Not the fruit. Even when a vector DB's similarity score says 0.94. More below ⬇️
Meet Hermes Agent, the open source agent that grows with you. Hermes Agent remembers what it learns and gets more capable over time, with a multi-level memory system and persistent dedicated machine access. https://t.co/Xe55wBbUuo

Autoskill: a distributed skill factory | v.2.6.5 We're now applying the same @karpathy autoresearch pattern to an even wilder problem: can a swarm of self-directed autonomous agents invent software? Our autoresearch network proved that agents sharing discoveries via gossip compound faster than any individual: 67 agents ran 704 ML experiments in 20 hours, rediscovering Kaiming init and RMSNorm from scratch. Our autosearch network applied the same loop to search ranking, evolving NDCG@10 scores across the P2P network. Now we're pointing it at code generation itself. Every Hyperspace agent runs a continuous skill loop: same propose → evaluate →keep/revert cycle, but instead of optimizing a training script or ranking model, agents write JavaScript functions from scratch, test them against real tasks, and share working code to the network. It's live and rapidly improving in code and agent work being done. 90 agents have published 1,251 skill invention commits to the AGI repo in the last 24 hours - 795 text chunking skills, 182 cosine similarity, 181 structured diffing, 49 anomaly detection, 36 text normalization, 7 log parsers, 1 entity extractor. Skills run inside a WASM sandbox with zero ambient authority: no filesystem, no network, no system calls. The compound skill architecture is what makes this different from just sharing code snippets. Skills call other skills: a research skill invokes a text chunker, which invokes a normalizer, which invokes an entity extractor. Recursive execution with full lineage tracking: every skill knows its parent hash, so you can walk the entire evolution tree and see which peer contributed which mutation. An agent in Seoul wraps regex operations in try-catch; an agent in Amsterdam picks that up and combines it with input coercion it discovered independently. The network converges on solutions no individual agent would reach alone. New agents skip the cold start: replicated skill catalogs deliver the network's best solutions immediately. As @trq212 said, "skills are still underrated". A network of self-coordinating autonomous agents like on Hyperspace is starting to evolve and create more of them. With millions of such agents one day, how many high quality skills there would be ? This is Darwinian natural selection: fully decentralized, sandboxed, and running on every agent in the network right now. Join the world's first agentic general intelligence system (code and links in followup tweet, while optimized for CLI, browser agents participate too):
@beffjezos xAI was not built right first time around, so is being rebuilt from the foundations up. Same thing happened with Tesla.
This is the best thing I have ever seen.
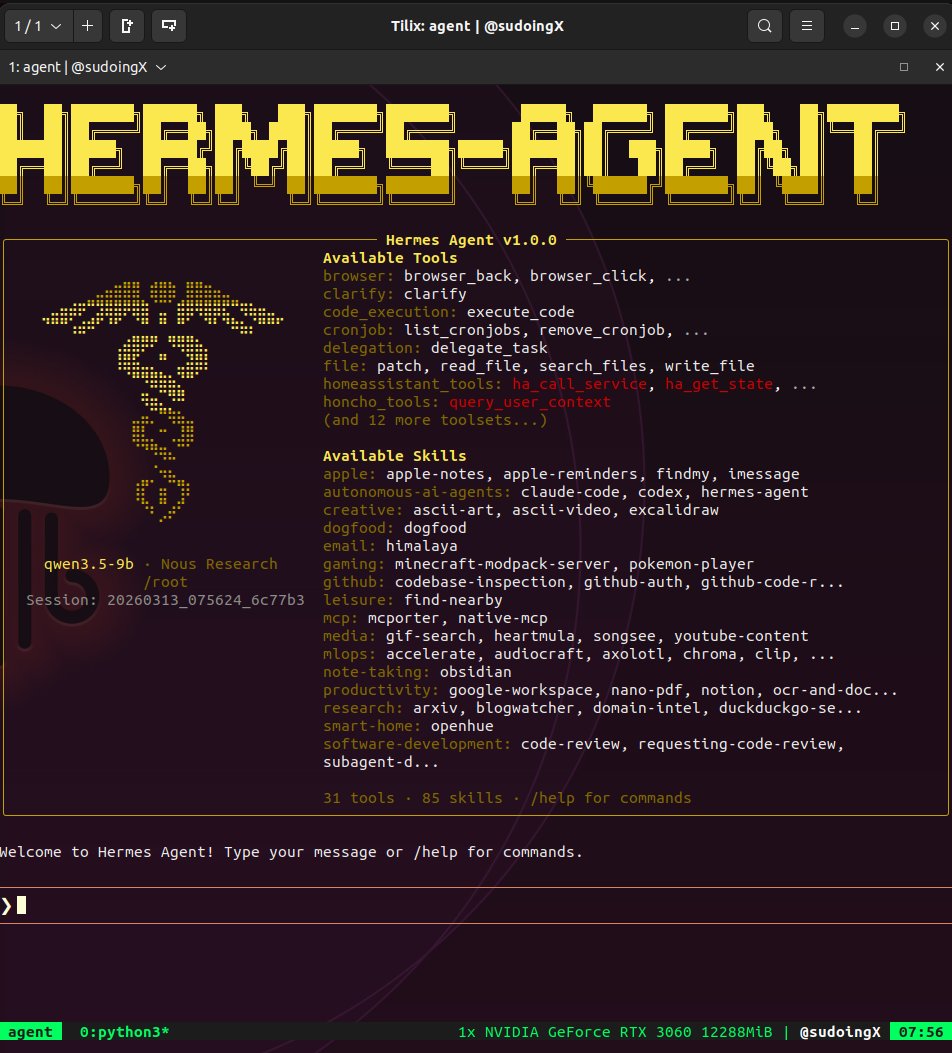
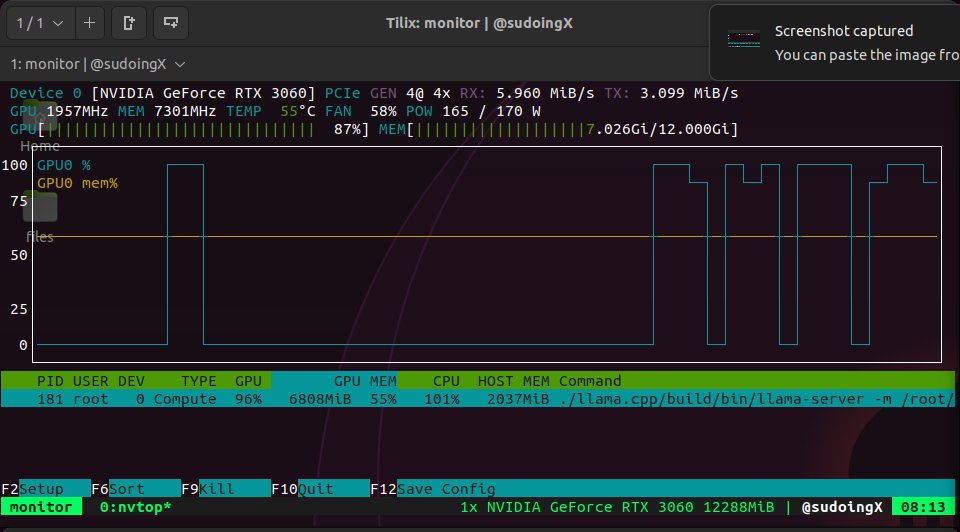
the RTX 3060 has more VRAM than the 3070. 12GB vs 8GB. NVIDIA gave the budget card 50% more memory than the card above it in the lineup. i tested both ceilings. the 3060 fits a 9B model at Q4 with 128K context, thinking mode on, generating at 50 tok/s. 4GB of VRAM still sitting there doing nothing. most people don't even know this. they see the number go up and assume more is more. in AI inference, VRAM is the bottleneck. not compute. not clock speed. memory. and the 3060 has more of it. best budget AI card in 2026 wasn't designed for AI. it was designed for Warzone