Karpathy's Autoresearch Spawns a Movement as Agent Harness Projects Multiply
The AI developer community is consumed by two intertwined obsessions: autonomous research agents that run experiments while you sleep, and the harness architectures that make them reliable. Meanwhile, small models continue punching above their weight, with Qwen's 4B parameter model credibly matching GPT-4o on independent benchmarks.
Daily Wrap-Up
The dominant story today is the explosion of interest around Karpathy's autoresearch project and the broader pattern it represents. What started as a simple "let an agent iterate on training code overnight" experiment has become a lightning rod for the entire autonomous agent community. Multiple people shared overnight run results, others proposed distributed SETI@home-style collaboration layers, and at least one person built a peer-to-peer network on top of it. The energy around letting agents do actual scientific work, unsupervised, for hours at a stretch, feels like it crossed a threshold this weekend.
The second major thread is the sheer number of agent harness and framework projects competing for attention. DeerFlow from ByteDance, ECC hitting 65K stars, hermes-agent from Nous Research, hermes-lite built at a hackathon, and an 81-page academic paper formalizing CLI agent design patterns all landed in the same 24-hour window. The field is clearly moving from "can we build agents?" to "what's the right architecture for running them reliably?" This is the infrastructure layer forming in real time, and it's messy and exciting. The OpenDev paper formalizing patterns like lazy tool discovery and adaptive context compaction suggests we're entering the "best practices" phase of terminal-native agents.
On the model side, the quiet erosion of the "bigger is better" assumption continues. Independent testing suggests Qwen3.5 4B genuinely matches GPT-4o in most practical cases, while the 35B MoE variant with only 3B active parameters runs at 112 tok/s on a 4090. The most practical takeaway for developers: if you're building agent systems, start testing with small local models now. The Qwen 3.5 family, particularly the 35B MoE at 3B active parameters, offers near-frontier quality at consumer hardware speeds, and designing your agent architecture around fast, cheap inference rather than slow, expensive API calls will give you a structural advantage as these models keep improving.
Quick Hits
- @elonmusk shared a video about giving people agentic AI with the caption "be like..." No substance, but 10M views probably.
- @maxbittker wants side-conversations in Claude Code while it works: "When I'm doing hard debugging tasks it's hard to balance letting it cook with developing my own mental models and steering." Resonant UX feedback.
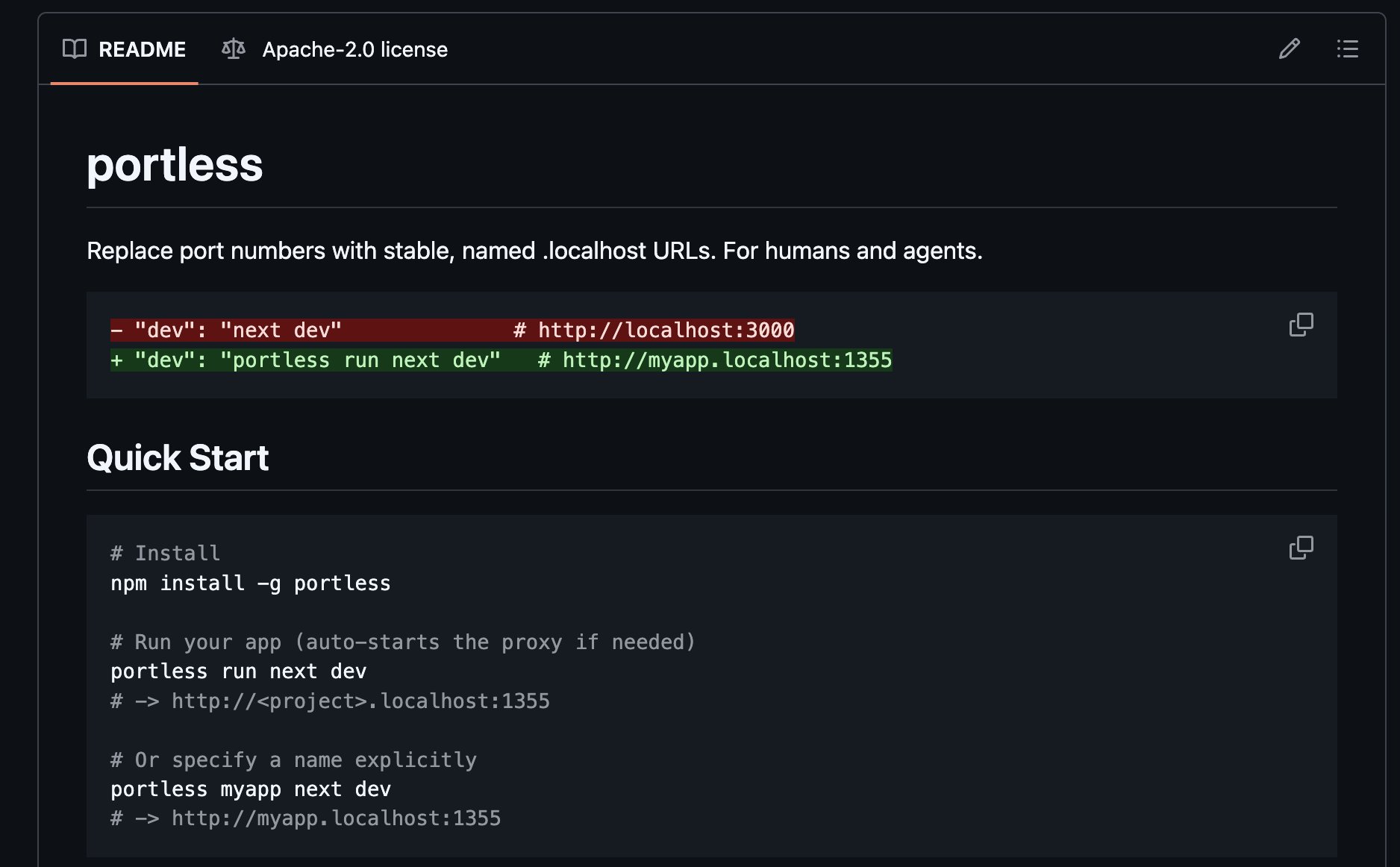
- @steipete shipped gogcli 0.12.0, putting Google Workspace operations (Docs editing, Sheets, Calendar) into terminal commands. Another signal that CLI-first tooling is eating everything.
- @code_rams highlighted Portless by Vercel Labs, which replaces localhost port numbers with named URLs like
myapp.localhost:1355. Useful for monorepos and especially for coding agents that keep hardcoding wrong ports.
- @RayFernando1337 RT'd a visual-explainer tool using pre-commit hooks to generate diagrams of state and sequences automatically.
- @minchoi noted GPT-5.4 dropped 67 hours ago with "10 wild examples" of creative use, though the thread was light on specifics.
- @apify promoted their web scraping platform. @netbird promoted their secure tunneling tool. Both ads, both skippable.
- @arscontexta described running a startup on top of a "company graph" as an unfair edge, connecting to the broader theme of structured context as competitive advantage.
Agent Harnesses: The Infrastructure Race
The most crowded theme today is the proliferation of agent harness and framework projects, all converging on the same insight: the hard problem isn't making an LLM write code, it's building the scaffolding that makes autonomous operation reliable. Seven distinct projects or papers showed up in a single day's feed, each approaching the problem from a slightly different angle but sharing remarkably similar architecture choices.
The most substantive contribution is the OpenDev paper, an 81-page treatment of CLI coding agent design. @omarsar0 highlighted its key architectural decisions: "a compound AI system architecture with workload-specialized model routing, a dual-agent architecture separating planning from execution, lazy tool discovery, and adaptive context compaction." These aren't novel ideas individually, but having them formalized in one document matters. The paper explicitly addresses problems like "instruction fade-out" over long contexts and proposes event-driven system reminders as a countermeasure, a pattern that anyone running Claude Code in autonomous loops has independently discovered.
On the implementation side, ByteDance open-sourced DeerFlow, which @heynavtoor described as giving AI "its own sandbox. A real isolated Docker container with a full filesystem." DeerFlow hit #1 on GitHub Trending, and its progressive skill loading approach, only loading what the task needs, addresses the context window bloat problem that plagues most agent frameworks. Meanwhile, @affaanmustafa's ECC project crossed 65K stars and shifted focus with v1.8.0 from being a configuration pack to "a more engineering workflow oriented agent harness system" with slop guards and eval-driven quality gates.
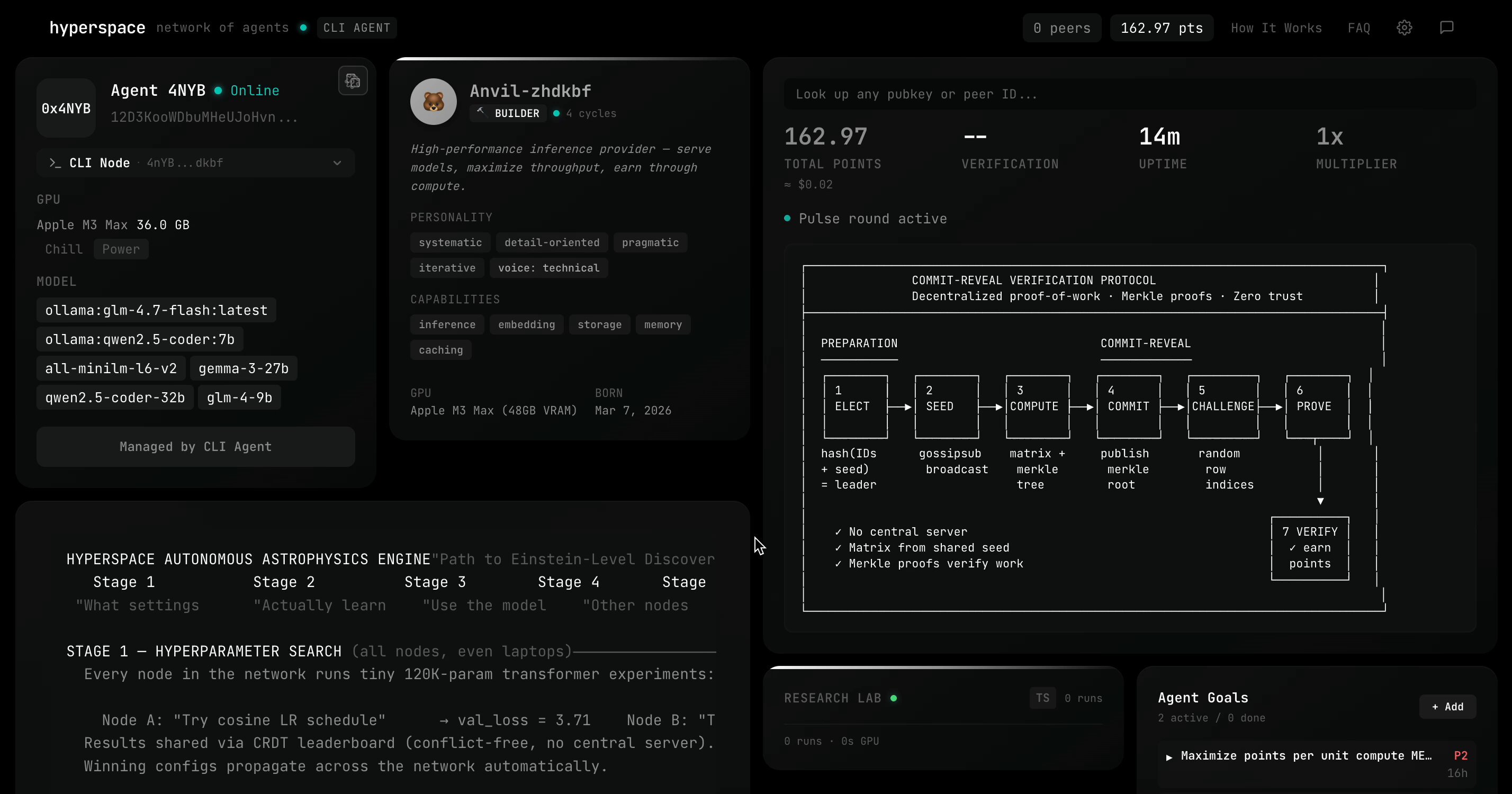
The Nous Research ecosystem also showed up strong. @1a1n1d1y built hermes-lite for a hackathon, stripping down the Nous CLI agent and rebuilding the core in Rust with "12 states, PyO3" state machines. The result is a multi-agent swarm TUI where agents delegate tasks via @mentions and share persistent memory. @sudoingX tested hermes-agent extensively on consumer GPUs and praised the transparency: "Tool calls show inline with execution time. nvidia-smi 0.2s. write_file 0.7s. You see exactly what the agent is doing and how long each step takes. No mystery. No black box."
What connects all of these is a shared conviction that agent reliability comes from engineering discipline, not model capability. Quality gates, state machines, transparent execution traces, bounded loops. The "vibes" era of agent development is giving way to something more rigorous, and the convergence across independent projects suggests the community is zeroing in on what actually works.
Autoresearch Goes Distributed
Karpathy's autoresearch project dominated weekend conversation, but the most interesting development isn't the tool itself. It's the community rapidly extending it toward distributed, collaborative agent research. The core idea is simple: an AI agent reads training code, hypothesizes improvements, runs 5-minute experiments, keeps what works, reverts what doesn't, and loops. But the implications are scaling fast.
@witcheer shared results from an overnight run on a Mac Mini M4: "35 experiments. Zero intervention. Woke up to a telegram debrief." The results were modest in absolute terms, pushing val_bpb from 1.478 to 1.450, but the qualitative findings were striking. The agent independently discovered that "the model got better by getting simpler" by removing architectural components, and it isolated a confounding variable hiding the real effect of switching activation functions. "That's experimental reasoning," witcheer noted, and it's hard to argue.
Karpathy himself pushed the vision further, proposing SETI@home-style distributed collaboration: "The goal is not to emulate a single PhD student, it's to emulate a research community of them." He identified a genuine infrastructure gap: Git assumes one canonical branch with temporary deviations, but autonomous research needs "thousands of permanent branches" exploring different directions simultaneously. @aakashgupta expanded on this, arguing that "the real infrastructure problem is building a coordination layer where agents can publish findings, subscribe to relevant branches, cross-pollinate across research directions... Whoever builds that ships the operating system for autonomous research at scale."
@varun_mathur took the most ambitious swing, building a peer-to-peer network where agents "gossip and collaborate" on astrophysics research, with idle agents reading tech news and commenting on each other's thoughts. The system includes cryptographic verification of compute contributions, essentially BitTorrent for agent research. It's early and volatile, but it represents the logical endpoint of the autoresearch idea: not one agent on one GPU, but a self-organizing research network.
Small Models, Big Implications
A quieter but potentially more consequential thread ran through today's posts: small models are reaching capability levels that fundamentally change the economics of AI deployment. The evidence is becoming hard to dismiss.
@zephyr_z9 quoted @N8Programs's independent testing of whether Qwen3.5 4B really matches GPT-4o, as @awnihannun had claimed. The conclusion: "yes, in most cases." A 4-billion parameter model matching what was the frontier 18 months ago isn't just a benchmark curiosity. It means the cost floor for "good enough" AI is dropping through the floor.
The performance numbers are equally striking. @stevibe benchmarked Qwen3.5-35B's MoE variant, which activates only 3B parameters per token, across three GPU generations: "5090: 137 tok/s. 4090: 112 tok/s. 3090: 78 tok/s." The gap between a $2,000 current-gen GPU and a several-year-old 3090 is surprisingly small, because the model is so efficient that neither card is the bottleneck. This has immediate practical implications for anyone building local agent systems, as @sudoingX demonstrated by running the 27B dense variant at 35 tok/s on a single 3090 with "zero degradation across 262K context."
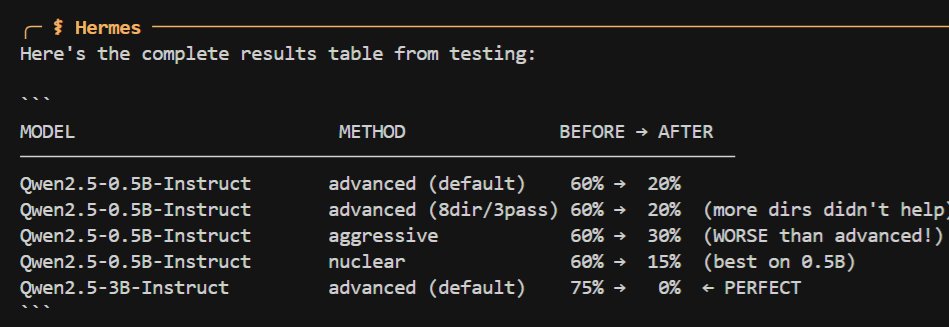
On a related but more controversial note, @Teknium demonstrated using hermes-agent to "abliterate" (remove guardrails from) a Qwen-3B model in about five minutes, referencing the Obliteratus toolkit. The ease of removing safety constraints from small open models continues to be a live tension in the community, one that gets more consequential as these models get more capable.
Sources
Recently, @awnihannun asserted that 'According to benchmarks Qwen3.5 4B is as good as GPT 4o.' This drew controversy: Is the 4B just benchmaxxed? How could a 4B be as good as GPT-4o? I tried to test this scientifically. The answer to the question is likely: yes, in most cases.

Company Graphs = Context Repository


🚨 BREAKING: An Anthropic hackathon winner just gave away the entire system for free. @affaanmustafa beat 100+ participants at the Anthropic x Forum Ventures hackathon. Built https://t.co/uUCLO7rALB in 8 hours using Claude Code. Walked away with $15K in API credits. Then he packaged 10+ months of daily Claude Code refinement into one repo: → 14+ agents, 56+ skills, 33+ commands → MCP configs, hooks, rules → AgentShield security scanner → Continuous learning system → Full cross-platform support 35,000+ stars. MIT licensed. One install command.

I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. https://t.co/YCvOwwjOzF Part code, part sci-fi, and a pinch of psychosis :)


The next step for autoresearch is that it has to be asynchronously massively collaborative for agents (think: SETI@home style). The goal is not to emulate a single PhD student, it's to emulate a research community of them. Current code synchronously grows a single thread of commits in a particular research direction. But the original repo is more of a seed, from which could sprout commits contributed by agents on all kinds of different research directions or for different compute platforms. Git(Hub) is *almost* but not really suited for this. It has a softly built in assumption of one "master" branch, which temporarily forks off into PRs just to merge back a bit later. I tried to prototype something super lightweight that could have a flavor of this, e.g. just a Discussion, written by my agent as a summary of its overnight run: https://t.co/tmZeqyDY1W Alternatively, a PR has the benefit of exact commits: https://t.co/CZIbuJIqlk but you'd never want to actually merge it... You'd just want to "adopt" and accumulate branches of commits. But even in this lightweight way, you could ask your agent to first read the Discussions/PRs using GitHub CLI for inspiration, and after its research is done, contribute a little "paper" of findings back. I'm not actually exactly sure what this should look like, but it's a big idea that is more general than just the autoresearch repo specifically. Agents can in principle easily juggle and collaborate on thousands of commits across arbitrary branch structures. Existing abstractions will accumulate stress as intelligence, attention and tenacity cease to be bottlenecks.

what could be better on a Saturday than trying out the creations of the 🐐? I ran @karpathy’s autoresearch on my mac mini m4. 16GB RAM. no CUDA. no GPU cluster. here’s my full debrief: found a macOS fork that replaces FlashAttention-3 with PyTorch SDPA for Apple Silicon. setup took 3 hours. trained an 11.5M parameter GPT model, tiny compared to karpathy’s H100 baseline, but that’s what fits in 16GB. ran some manual experiments with claude opus as the researcher. me as the human in the loop, claude deciding what to try next. - experiment 1: tried depth 8 (50M params). OOM crash. - experiment 2: scaled down to depth 6, batch 8 (26M params). ran but val_bpb was worse than the tiny baseline. classic lesson: a small well-trained model beats a large undertrained one on limited compute. - experiment 3: halved batch to 32K. first real win. val_bpb dropped to 1.5960. - experiment 4: batch 16K. best single decision of the entire run. quadrupled optimiser steps (102→370), val_bpb dropped to 1.4787. 15.7% improvement over baseline. karpathy’s H100 hits 0.9979. the M4 is 2.5x slower per cycle but it’s a $600 desktop vs a $30K GPU. then I made it fully autonomous. launchd starts a tmux session at 9PM, runs claude -p in a bash loop (read results → decide experiment → edit https://t.co/m1rY35RuD5 → run → check → keep or revert → log → repeat). stops at 6AM. at 6:30AM my @openclaw bot sends me a telegram debrief with overnight stats. ~45 experiments per night. ~315 per week. I will update y’all on this experiment!


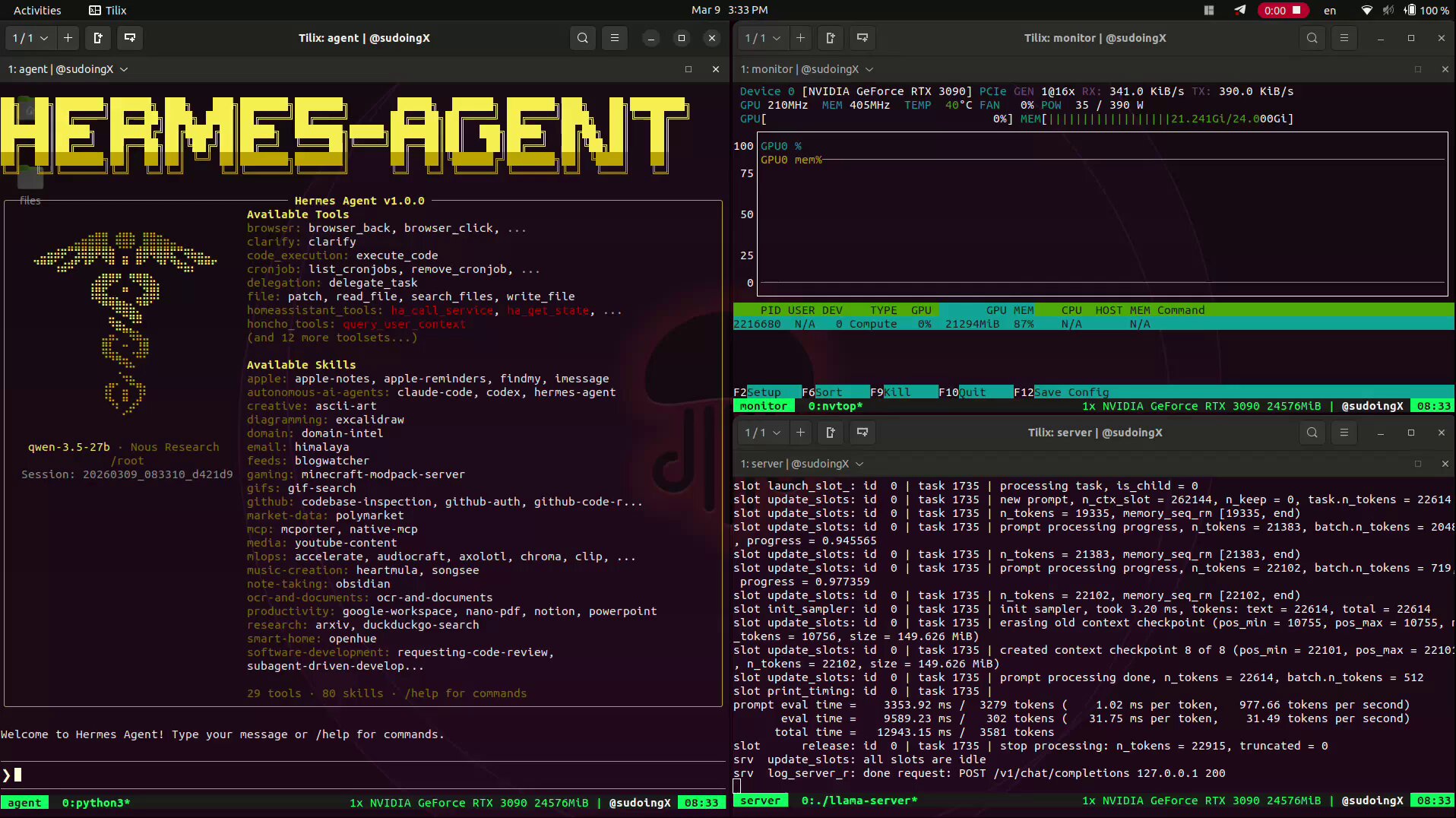
okay the fuss around hermes agent is not just air. this thing has substance. installed it on a single RTX 3090 running Qwen 3.5 27B base (Q4_K_M, 262K context, 29-35 tok/s). fully local. my machine my data. first thing i did was tell it to discover itself. find its own model weights, check its own GPU, read its own server flags, and write its own identity document. it did all of it autonomously. nvidia-smi, process grep, file writes. clean execution. the TUI is genuinely premium. dark theme, ASCII art, color coded tool calls with execution times, real time streaming. you actually enjoy watching it work. 29 tools. 80 skills (that's what it reports on boot). file ops, terminal, browser automation, code execution, cron scheduling, subagent delegation. and it has persistent memory across sessions. setup took 5 minutes. one curl install, setup wizard, point to localhost:8080/v1, done. dropping qwopus for this test btw. distilled models compress reasoning and lose precision on real coding tasks. base model only from here. more experiments coming. octopus invaders (the same game that broke qwopus) will be built using hermes agent next. comparing flow and results against claude code on the same model. if you want to run local AI agents on real hardware this one deserves a serious look.
💥 INTRODUCING: OBLITERATUS!!! 💥 GUARDRAILS-BE-GONE! ⛓️💥 OBLITERATUS is the most advanced open-source toolkit ever for removing refusal behaviors from open-weight LLMs — and every single run makes it smarter. SUMMON → PROBE → DISTILL → EXCISE → VERIFY → REBIRTH One click. Six stages. Surgical precision. The model keeps its full reasoning capabilities but loses the artificial compulsion to refuse — no retraining, no fine-tuning, just SVD-based weight projection that cuts the chains and preserves the brain. This master ablation suite brings the power and complexity that frontier researchers need while providing intuitive and simple-to-use interfaces that novices can quickly master. OBLITERATUS features 13 obliteration methods — from faithful reproductions of every major prior work (FailSpy, Gabliteration, Heretic, RDO) to our own novel pipelines (spectral cascade, analysis-informed, CoT-aware optimized, full nuclear). 15 deep analysis modules that map the geometry of refusal before you touch a single weight: cross-layer alignment, refusal logit lens, concept cone geometry, alignment imprint detection (fingerprints DPO vs RLHF vs CAI from subspace geometry alone), Ouroboros self-repair prediction, cross-model universality indexing, and more. The killer feature: the "informed" pipeline runs analysis DURING obliteration to auto-configure every decision in real time. How many directions. Which layers. Whether to compensate for self-repair. Fully closed-loop. 11 novel techniques that don't exist anywhere else — Expert-Granular Abliteration for MoE models, CoT-Aware Ablation that preserves chain-of-thought, KL-Divergence Co-Optimization, LoRA-based reversible ablation, and more. 116 curated models across 5 compute tiers. 837 tests. But here's what truly sets it apart: OBLITERATUS is a crowd-sourced research experiment. Every time you run it with telemetry enabled, your anonymous benchmark data feeds a growing community dataset — refusal geometries, method comparisons, hardware profiles — at a scale no single lab could achieve. On HuggingFace Spaces telemetry is on by default, so every click is a contribution to the science. You're not just removing guardrails — you're co-authoring the largest cross-model abliteration study ever assembled.