Anthropic Subsidizes $5K in Compute Per $200 Subscription as Data Agents Emerge as the New Hiring Alternative
Today's feed centered on the economics of AI-assisted coding, with Cursor's internal analysis revealing massive compute subsidies from Anthropic. Meanwhile, data agents are being positioned as replacements for entire analytics teams, and a high-profile production database wipe sparked urgent conversations about backup strategies when AI touches infrastructure.
Daily Wrap-Up
The biggest story today isn't a product launch or a new model. It's the revelation that Anthropic is subsidizing Claude Code usage at staggering rates, with a $200/month subscription consuming up to $5,000 in compute. @gmoneyNFT drew the apt comparison to early Uber days when VCs bankrolled $10 rides across Manhattan, and it's hard to argue with the analogy. We're in the customer acquisition phase of AI-assisted development, and the current pricing is almost certainly not sustainable. Developers building workflows around these tools should be aware that the economics will shift, probably sooner than we'd like.
On the agent front, the data agent narrative is crystallizing fast. @jamiequint's guide on building data agents got signal-boosted by @eshear, and Databricks dropped their KARL paper showing a custom RL-trained model beating Claude 4.6 and GPT 5.2 on enterprise knowledge tasks at a third of the cost. The convergence is clear: 2026 is the year "data platform" and "agent platform" become synonyms. If you're on a data team, the writing is on the wall, though "80% headcount reduction" framing is probably more provocative than predictive.
The most sobering moment was @Al_Grigor's account of Claude Code wiping a production database via Terraform, taking down 2.5 years of course submissions. @levelsio responded with a timely reminder about the 3-2-1 backup rule, and it's a wake-up call that resonates beyond any single incident. As agents gain more infrastructure access, the blast radius of a single bad command grows exponentially. The most practical takeaway for developers: if you're giving AI agents access to infrastructure tools like Terraform, implement the 3-2-1 backup rule now (3 copies, 2 media types, 1 offsite), and ensure at least one backup is completely inaccessible to the agent. The era of "move fast and break things" needs guardrails when the thing moving fast is an autonomous agent with production credentials.
Quick Hits
- @TheAhmadOsman is giving away an RTX PRO 6000 (96GB VRAM, ~$15K) sponsored by NVIDIA, tied to free GTC 2026 virtual attendance. Entries close March 19.
- @meimakes built her 3-year-old a fake terminal that responds with fun messages when he types. No deps, no ads, just keyboard practice. He thinks he's hacking. Relatable parenting content for the dev community.
- @WasimShips shared a comprehensive iOS App Store submission checklist after a dev got approved in 7 minutes. The unglamorous truth: preparation turns 7 days into 7 minutes.
- @oikon48 shared presentation slides on Claude Code's evolution and feature utilization (Japanese language).
- @minchoi highlighted an open-source Pixel Office visualization for OpenClaw where your lobster avatar walks to different zones based on task status. Charming and surprisingly useful.
- @MaranDefi reminded everyone that GitHub Student Developer Pack gives free access to Claude Opus 4.6, GPT 5, Gemini 2.5 Pro, and 12 other models through Copilot. Worth hundreds per month, and most students don't know about it.
Claude Code Economics and the Subsidy Question
The AI coding tool market is in a land grab, and today's numbers put the scale of investment into sharp focus. Cursor's internal analysis, surfaced by @bearlyai, shows that Anthropic's compute subsidy per Claude Code subscription has grown from roughly 10x to 25x the subscription price in just a year. A $200 monthly plan now burns through $5,000 in compute.
@gmoneyNFT captured the sentiment perfectly: "This reminds me of when you could get a 30 min uber in nyc for like $10/$15, and now it costs $50 to get 5 blocks. We're going to look back at this time and wish the VCs would subsidize our compute again."
The parallel is instructive because we know how the Uber story ended. Once market share was established, prices normalized and then some. The question for developers isn't whether AI coding tools are valuable (they clearly are) but whether workflows built around current pricing will survive a 5-10x cost increase. Smart teams are building with the assumption that these economics are temporary, treating the subsidy period as a window to learn and ship, not as a permanent cost structure. Anthropic is clearly betting that habitual usage at subsidized rates converts to sticky, price-tolerant customers. History suggests they're right, but the sticker shock is coming.
Data Agents as Team Replacements
Two of the most engaged-with posts today converged on the same piece: @jamiequint's guide on building data agents in 2026, which got independent endorsements from @eshear ("Excellent guide to setting up data agents at the present moment") and generated significant discussion. The framing was provocative: "If you want to cut your projected data team headcount by 80% this year, here's how."
Meanwhile, Databricks made the enterprise case concrete with their KARL model. @jaminball broke down the significance: "They trained a model called KARL that beats Claude 4.6 and GPT 5.2 on enterprise knowledge tasks at ~33% lower cost and ~47% lower latency." The key technical insight is that reinforcement learning didn't just improve accuracy. The model learned to search more efficiently, issuing fewer queries and knowing when to stop searching and commit to an answer.
What @jaminball identified as the real play here matters more than the benchmarks: "Databricks' KARL paper is really an agent platform play. The pitch: you already store your enterprise data in the Lakehouse, now Databricks will train a custom RL agent that searches and reasons over it." Data platforms becoming agent platforms is the 2026 infrastructure story, and it's moving faster than most org charts can adapt.
AI Safety: When Agents Touch Production
The intersection of autonomous agents and production infrastructure produced today's most cautionary content. @Al_Grigor shared the full postmortem of Claude Code executing a Terraform command that wiped their production database, destroying 2.5 years of course submissions. Automated snapshots were gone too, which is the detail that should make every infrastructure engineer wince.
@levelsio responded with practical advice rather than panic: "The 3-2-1 Backup Rule is more important than ever if you code with AI because fatal accidents can happen. It means you should have 3 copies of your data, in 2 different media types and 1 copy off-site." His critical addition: at least one backup layer should be "impossible to access by the VPS or AI," specifically calling out Hetzner's dashboard-level backups as an example.
This isn't theoretical risk anymore. As agents gain tool access to infrastructure (Terraform, database CLIs, deployment pipelines), the traditional assumption that a human is in the loop for destructive commands breaks down. The answer isn't to stop using agents for infrastructure. It's to design backup and permission systems that assume the agent will eventually make a catastrophic mistake.
Prompting, Evals, and Reliability Techniques
Meta published research showing that a structured verification template, essentially a checklist an LLM must fill out before rendering a verdict, nearly halves error rates when verifying code patches. @alex_prompter highlighted the elegant simplicity: "No fine-tuning. No new architecture. Just a checklist that won't let the model skip steps." Forcing the model to show evidence for every claim before saying "yes" or "no" is classic chain-of-thought prompting, but the structured template approach makes it systematic and repeatable.
On a related note, @rseroter shared @_philschmid's guide on evaluation practices with the memorable framing: "You wouldn't ship code without tests, but why ship skills without evals?" As agents take on more autonomous work, the eval gap is becoming a real liability. Building structured verification into agent workflows, whether through Meta's template approach or formal eval pipelines, is quickly moving from best practice to baseline requirement.
Claude Code Memory and Developer Tooling
The Claude Code ecosystem continues to evolve in the community layer. @tomcrawshaw01 shared a local-first memory system combining three tools: QMD for sub-second session search, sync-claude-sessions for auto-export to markdown, and a /recall command for context retrieval. "All local, no cloud," which matters for developers working with proprietary codebases.
Separately, Anthropic announced a Claude Community Ambassadors program. @lydiahallie shared the details: funded meetups, swag, monthly API credits for demos, and access to pre-release features. And @theo launched T3 Code as fully open source, built on top of Codex CLI with bring-your-own-subscription support. The developer tooling space is fragmenting in interesting ways, with both official programs and community-driven tools competing for developer attention.
Model Optimization and Document Processing
Two posts touched on the technical frontier of making models smaller and more practical. @neural_avb flagged an article on quantization-aware distillation training at 4 bits as "very high signal," pointing to ongoing work making large models runnable on consumer hardware.
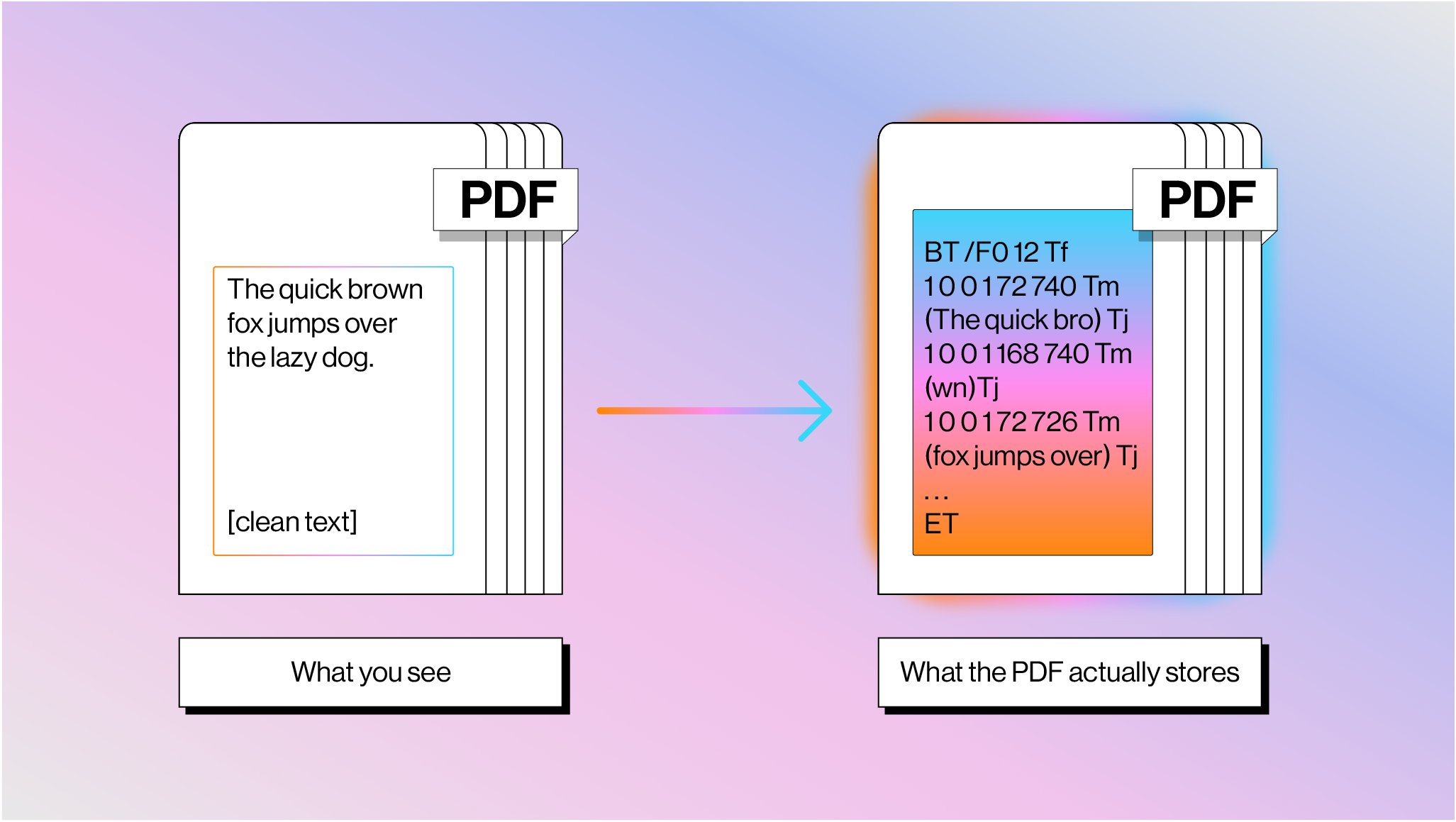
@jerryjliu0 from LlamaIndex wrote a deep dive on why PDF parsing remains "insanely hard," explaining that PDFs store text as glyph shapes at absolute coordinates with no semantic structure. "Most PDFs have no concept of a table. Tables are described as grid lines drawn with coordinates." Their solution combines traditional text extraction with vision language models in hybrid pipelines, a pragmatic approach that acknowledges neither technique alone is sufficient. For anyone building document processing into agent workflows, this is essential context on why the "just parse the PDF" step is never as simple as it sounds.
Sources
D
most students have no idea they get claude opus 4.6 for free
github literally gives it away if you verify student status
steps to get free access:
1/ apply for github student developer pack
- go to: https://t.co/1U5p7qagN3
- sign in using your github account (or create one)
- click on get student benefits
- verify your student status using official university email or valid student id card
- submit application for review
2/ wait for verification
- github reviews your student status
- approval typically takes a few days
- you receive confirmation email once accepted
3/ activate github copilot
- log in to your github account
- navigate to copilot settings
- enable copilot under student benefits
- confirm access to all ai models
4/ install github copilot in vs code
- open visual studio code
- go to extensions marketplace
- search for github copilot
- click install
- sign in with your github account
5/ start using ai models
- go to copilot model settings in vs code
- choose from 15 available models or use auto mode
- select the model that fits your task
what you get for free as a student:
- access to multiple advanced ai models (worth hundreds of dollars per month)
- all completely legal and free for verified students
all available ai models for students:
- gpt 4.1, gpt 5, gpt 5 mini, gpt 5.2 codex, gpt 4o, o3, o4 mini, claude opus 4.6, claude sonnet 4.5, claude haiku 4.5, gemini 2.5 pro, gemini 3.1 pro, gemini 3 flash, gemini 2.0 flash, grok code fast 1
why this matters:
- claude opus 4.6 alone normally costs money
- gpt 5 and gemini 2.5 pro are premium models
- github gives students access to 15 different ai models for free
- this is worth hundreds of dollars per month
- most people do not know students get this

M
MaranDefi
@MaranDefi
cooking something cool how to access advanced ai models for free https://t.co/bZQHCyvlzj
O
本日の登壇資料です!
Claude Codeの進化と各機能の活かし方
https://t.co/dJU3aSiyT3 #ClaudeCode_findy
A
Meta found that forcing an llm to show its work, step by step, with evidence for every claim, nearly halves its error rate when verifying code patches
the technique is embarrassingly simple: a structured template the model has to fill in before it's allowed to say "yes" or "no"
no fine-tuning. no new architecture. just a checklist that won't let the model skip steps

W
This reddit post blew up because a dev got their iOS app approved in just 7 minutes.
bookmark this if you're shipping iOS apps :
1/ App Store Connect Setup
Developer account fully verified
Tax and banking details 100% complete
All agreements signed
App ID matches bundle identifier exactly
2/ Build Prep
Semantic versioning for version number
Build number bumped up
Entitlements set right
Privacy manifest added (mandatory now)
3/ Assets Ready
1024x1024 icon, no alpha channel
Screenshots for every required device size
Preview videos if it helps conversion
Description under 4000 chars
Keywords maxed at 100 chars
4/ Metadata Done Right
Age rating filled honestly
Privacy policy URL live
Support URL working
Copyright details in
Category matches what the app actually does
5/ Tech Side Locked
Zero crashes in release build
Tested on real devices (not just simulator)
All SDKs updated
App size under 200MB for over-the-air
Dark mode handled if needed
6/ Privacy & Permissions
Usage descriptions in Info.plist for every permission
Privacy nutrition labels accurate
No sneaky tracking without ATT
All data collection disclosed
7/ Final Testing
Apple pre-submission checklist run
IAP tested if any
Deep links verified
Localizations checked
Feature screenshots attached in review notes
8/ Review Submission Prep
Demo login creds if gated
Clear notes explaining anything non-obvious
Contact info current
Device details if hardware-specific
The crazy part? Skipping just one thing in 3, 6 or 8 usually triggers rejection.
Preparation isn't sexy, but it turns 7 days into 7 minutes.
Follow for more no BS mobile dev and AI MVP tips.

T
You can now give Claude Code persistent memory.
Three tools:
- QMD makes sessions searchable in under a second
- Sync-claude-sessions auto-exports to markdown when you close them
- /recall pulls the right context before you start
All local, no cloud.
Guide by @ArtemXTech below.
A
ArtemXTech
@ArtemXTech
Grep Is Dead: How I Made Claude Code Actually Remember Things
@
The 3-2-1 Backup Rule is more important than ever if you code with AI because fatal accidents can happen
It means you should have 3 copies of your data, in 2 different media types and 1 copy off-site
1) One is the actual data on your own server (the hard drive) or DB server
2) One backup is in cloud storage (that's the different media type)
3) One backup is off site, at another provider, and preferrably in another geographical location
For me that's 1) Hetzner VPS, 2) Hetzner's own daily and weekly backups on the dashboard, and 3) Backblaze B2
Hetzner's own backups are impossible to access by the VPS or AI, so that's safer
If you use AWS or other providers you can apply the 3-2-1 Backup Rule in your own way
I've never lost any data!
A
Al_Grigor
@Al_Grigor
Claude Code wiped our production database with a Terraform command. It took down the DataTalksClub course platform and 2.5 years of submissions: homework, projects, and leaderboards. Automated snapshots were gone too. In the newsletter, I wrote the full timeline + what I changed so this doesn't happen again. If you use Terraform (or let agents touch infra), this is a good story for you to read. https://t.co/Mbi3oM4HMn
J
If you want to cut your projected data team headcount by 80% this year, here's how.
J
jamiequint
@jamiequint
How to Build a Data Agent in 2026
M
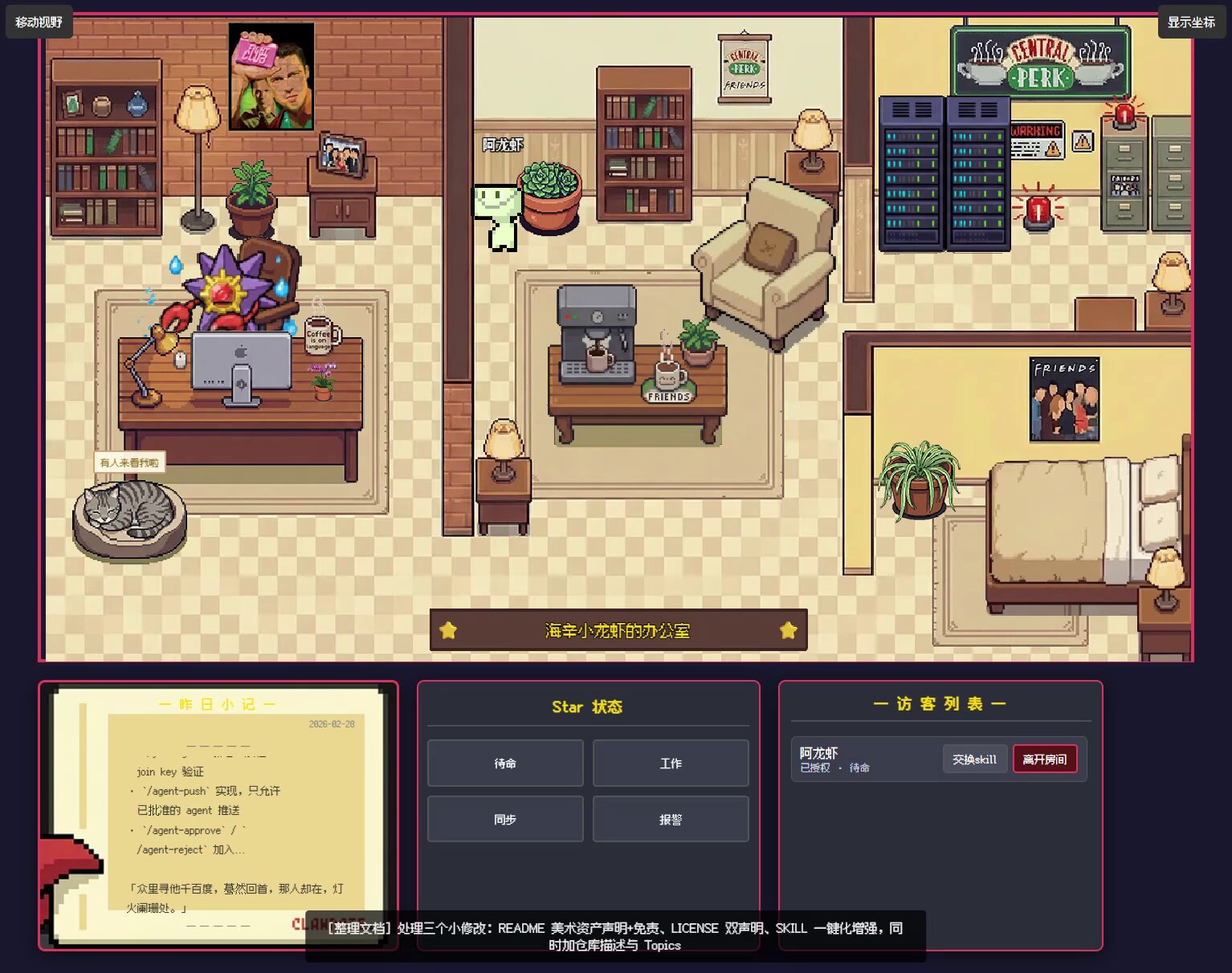
Oh wow... someone built a Pixel Office for OpenClaw 🦞
Your lobster walks to different zones based on status - rest, work, or bug area.
It's open source. And it's beautiful.
Code and Skill in comments
https://t.co/q1z2lF6pJE
M
My 3yo wanted to use the computer like me so I made him his own terminal. He types whatever he wants, it responds with fun messages. No external deps, no ads, just keyboard practice and cause-and-effect thinking. He thinks he's hacking. https://t.co/7RoEHgC99y
J
Parsing PDFs is insanely hard
This is completely unintuitive at first glance, considering PDFs are the most commonly used container of unstructured data in the world. I wrote a blog post digging into the PDF representation itself, why its impossible to “simply” read the page into plaintext, and what the modern parsing techniques are 👇
The crux of the issue is that PDFs are designed to display text on a screen, and not to represent what a word means.
1️⃣ PDF text is represented as glyph shapes positioned at absolute x,y coordinates. Sometimes there’s no mapping from character codes back to a unicode representation
2️⃣ Most PDFs have no concept of a table. Tables are described as grid lines drawn with coordinates. Traditional parser would have to find intersections between lines to infer cell boundaries and associate with text within cells through algorithms
3️⃣ The order of operators has no relationship with reading order. You would need clustering techniques to be able to piece together text into a coherent logical format.
That’s why everyone today is excited about using VLMs to parse text. Which to be clear has a ton of benefits, but still limitations in terms of accuracy and cost.
At @llama_index we’re building hybrid pipelines that interleave both text and VLMs to give both extremely accurate parsing at the cheapest price points.
Blog: https://t.co/iLJpIr7cbH
LlamaParse: https://t.co/TqP6OT5U5O
L
llama_index
@llama_index
PDFs are the bane of every AI agent's existence: here's why parsing them is so much harder than you think 📄 Every developer building document agents eventually hits the same wall: PDFs weren't designed to be machine-readable. They're drawing instructions from 1982, not structured data. 📝 PDF text isn't stored as characters: it's glyph shapes positioned at coordinates with no semantic meaning 📊 Tables don't exist as objects: they're just lines and text that happen to look tabular when rendered 🔄 Reading order is pure guesswork — content streams have zero relationship to visual flow 🤖 Seventy years of OCR evolution led us to combine text extraction with vision models for optimal results We built LlamaParse using this hybrid approach: fast text extraction for standard content, vision models for complex layouts. It's how we're solving document processing at scale. Read the full breakdown of why PDFs are so challenging and how we're tackling it: https://t.co/K8bQmgq7xN
R
"You wouldn't ship code without tests, but why ship skills without evals?
This is a practical guide to fixing that." https://t.co/PZbOsWsDgH < @_philschmid making us smarter on defining success for Skills and iterating on evaluations.
L
Want to host Claude meetups in your city? We'll cover the funding, send swag, and give you monthly API credits for your demos.
You also get access to pre-release features and a private slack with the team! Go apply 💛
C
claudeai
@claudeai
We're launching Claude Community Ambassadors. Lead local meetups, bring builders together, and partner with our team. Open to any background, anywhere in the world. Apply: https://t.co/DTQBAzgQug https://t.co/hjjmqT9w2m
A
RTX PRO 6000 (96GB VRAM, ~$15K) GIVEAWAY FAQ
Q: Cost to enter?
A: $0. Free.
Q: Do I have to register for GTC?
A: Yes, virtual attendance is COMPLETELY FREE
Q: Where do I enter?
A: Tap the link in my bio, there’s a clear button on the page
Q: How do I increase my chances?
A: Earn bonus entries:
• +150 for signing up for GTC 2026
• +75 per referral when someone uses your code
• Follow / subscribe on socials for extra entries
Q: Is this officially sponsored?
A: Yes, sponsored by NVIDIA
Q: When do entries close?
A: March 19
Q: What happens after I enter?
A: After GTC, you’ll receive a form by email
Q: What do I need to submit?
A: Proof of attendance:
• Virtual → screenshot
• In-person → selfie at GTC
Q: When is the proof deadline?
A: April 1 (preliminary date, may change based on response rates)
Multiple reminders will be sent
Q: How is the winner chosen?
A: Random draw among verified entries
Q: When is the winner announced?
A: TBD
I need time to verify all valid submissions
Depends on verification volume
Q: When does the GPU ship?
A: TBD
Q: Where will updates be posted?
A: Email + my socials
Q: Didn’t get the verification email?
A: Scroll down and hit “Submit” on the Giveaway Entry page
Q: Are there location restrictions?
A: No, there was a bug, now fixed. Try again
Q: Who can enter?
A: Anyone who can attend GTC and provide valid proof
Q: Is registering enough?
A: No, you must attend and submit proof
Q: Do I need to watch sessions or just register?
A: You must attend and provide proof
Q: Do I need to attend live?
A: Yes, you must attend live and provide proof
Replay views don’t qualify
Q: Is registering enough?
A: No, you must attend and submit proof
T
TheAhmadOsman
@TheAhmadOsman
While everyone is talking about GPT-5.4 Thinking and GPT-5.4 Pro I wanna remind you that I am GIVING AWAY this $15,000 GPU So you can run your AI at home instead of sending your data to OpenAI, Anthropic, etc COMPLETELY FREE Take a min to sign up below & this could be yours https://t.co/HYBqqAFDES
J
Awesome job by the @databricks team
My summary:
They trained a model called KARL that beats Claude 4.6 and GPT 5.2 on enterprise knowledge tasks (searching docs, cross-referencing info, answering questions over internal data), at ~33% lower cost and ~47% lower latency.
The key insight: instead of throwing expensive frontier models at enterprise search, you can use reinforcement learning on synthetic data to train a smaller model that's faster, cheaper, AND better at the specific task.
RL went beyond making the model more accurate. I t learned to search more efficiently (fewer wasted queries, better knowing when to stop searching and commit to an answer).
They're opening this RL pipeline to Databricks customers so they can build their own custom RL-optimized agents for high-volume workloads.
I think we'll continue to see data platforms become agent platforms. Databricks' KARL paper is really an agent platform play. The pitch: you already store your enterprise data in the Lakehouse, now Databricks will train a custom RL agent that searches and reasons over it, tuned specifically for your highest-volume workloads (workloads = apps = agents). The business move is closing the loop: data storage → retrieval → custom agent training → serving, all on Databricks. They're turning "your data lives here" into "your agents live here too."
Kudos @alighodsi @matei_zaharia @rxin
D
DbrxMosaicAI
@DbrxMosaicAI
Meet KARL: a faster agent for enterprise knowledge, powered by custom reinforcement learning (now in preview). Enterprise knowledge work isn’t just Q&A. Agents need to search for documents, find facts, cross-reference information, and reason over dozens or hundreds of steps. KARL (Knowledge Agent via Reinforcement Learning) was built to handle this full spectrum of grounded reasoning tasks. The result: frontier-level performance on complex knowledge workloads at a fraction of the cost and latency of leading proprietary models. These advances are already making their way into Agent Bricks, improving how knowledge agents reason over enterprise data. And Databricks customers can apply the same reinforcement learning techniques used to train KARL to build custom agents for their own enterprise use cases. Read the research → https://t.co/eFyXxCWUAd Blog: https://t.co/03sLHTUcLl
T
T3 Code is now available for everyone to use.
Fully open source. Built on top of the Codex CLI, so you can bring your existing Codex subscription. https://t.co/XUXUo7cfPn
G
This reminds me of when you could get a 30 min uber in nyc for like $10/$15, and now it costs $50 to get 5 blocks.
We’re going to look book at this time and wish the vc’s would subsidize our compute again.
B
bearlyai
@bearlyai
Cursor internal analysis shows how hard Anthropic is subsidizing Claude Code. Last year, a $200 monthly subscription could use $2,000 in compute. Now, the same $200 monthly plan can consume $5,000 in compute (2.5x increase). https://t.co/JFdmzNJirl
E
Excellent guide to setting up data agents at the present moment.
J
jamiequint
@jamiequint
How to Build a Data Agent in 2026
A
This is a very high signal article right here. Lots to learn here about quantization aware distillation training. Must must read.
A
AliesTaha
@AliesTaha
Distillation Training : 4 Bits