Qwen Floods the Zone with Sub-10B Models While the Agent-First Future Takes Shape
Qwen dominated the conversation with a wave of small, locally-runnable models including the surprisingly capable 3B-parameter Coder-Next, while the Claude Code ecosystem continued to mature with new agent skills and memory solutions. Meanwhile, a growing chorus of voices argued that the next wave of software will be built not for humans clicking through UIs, but for agents calling CLIs.
Daily Wrap-Up
The big story today is Qwen's aggressive push into the small model space. They dropped dense models at 0.8B, 2B, 4B, and 9B parameters, plus a coding-specific model that punches absurdly above its weight class on benchmarks. The timing feels intentional. While Anthropic and OpenAI compete on capability ceilings, Qwen is carpet-bombing the floor, making "good enough" AI something you can run on a Mac Mini with no internet connection. The sovereignty angle resonated hard in the timeline. People aren't just excited about local inference for cost reasons anymore. They're excited because it means no terms of service update can pull the rug.
On the tooling front, the Claude Code ecosystem keeps getting more interesting. A new agent-browser skill lets coding agents control Electron apps like Discord and VS Code, which opens up automation surface area that was previously locked behind GUIs. Someone shared a practical approach to making Claude Code sessions persistent with memory, and the community continued to hash out the real-world pain points of routing local models through agent harnesses. The gap between "this model benchmarks well" and "this model works reliably in an agentic loop" remains wide, and today's posts made that tension very concrete.
The thread running underneath everything was the agent-native future. Multiple posts argued that software categories are about to be rebuilt for machine consumers rather than human ones, and that CLI-first design is the bridge. It's a compelling frame, even if it's probably 2-3 years ahead of reality for most software. The most entertaining moment was easily @darylginn's perfectly timed "Claude is down, hope you all remember what a variable is," which hit during what appeared to be an actual outage. The most practical takeaway for developers: grab one of the new Qwen 3.5 small models and try running it locally through your existing toolchain. The gap between local and cloud inference quality is closing fast at the sub-10B scale, and understanding where it breaks will inform your architecture decisions for the next year.
Quick Hits
- @gregisenberg and @baba_Omoloro both flagged that Anthropic has launched free courses covering Claude Code, agent skills, and Claude fundamentals, complete with certificates. Hard to argue with free education from the source.
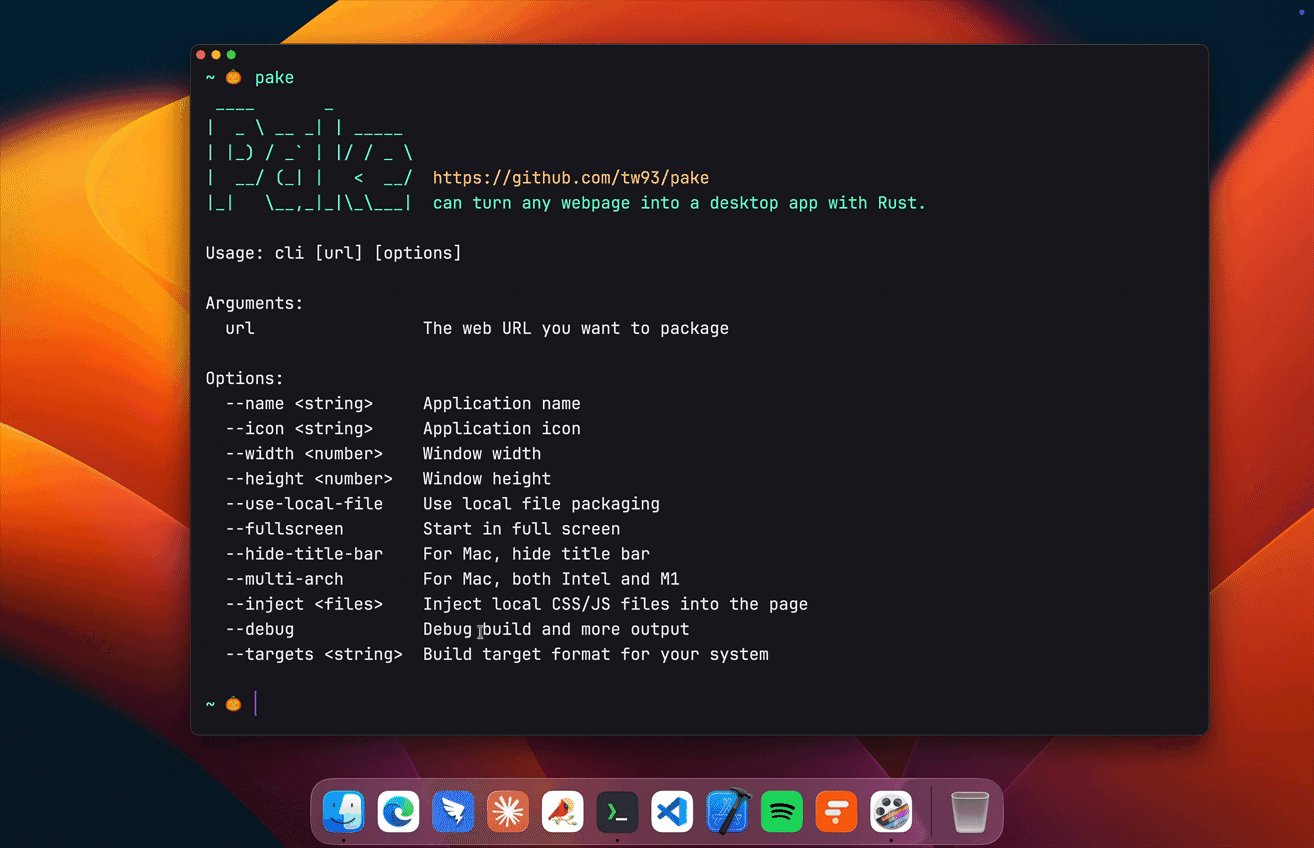
- @HiTw93 announced Pake 3.10.0, which packages any webpage into native desktop apps. The pitch for AI product builders: validate on web first, then ship desktop with a single command when you're ready.
- @heymingwei shared an MCP server for querying internet traffic trends and routing data, calling it "unbelievably powerful" for network analysis.
- @Toastonomics pointed someone toward a ChatGPT-specific tool, which is about as much context as the post provided.
- @cryptopunk7213 wrote an extended bit imagining the Pentagon trying to get Claude to launch missiles, complete with subscription upsell interruptions. Peak AI shitposting.
- @allTheYud channeled Pope Leo XIV with: "ChatGPT has no soul; no, not even a fraction of a soul. It was not born of love, nor raised in love. Use Opus 4.6 instead." Vatican-endorsed model selection.
- @flyosity posted a screenshot with just "--dangerously-skip-permissions" and a link, which is either a cautionary tale or a lifestyle choice depending on your risk tolerance.
- @kshvbgde captioned an image with "sir, they hit the second data center," continuing the rich tradition of infrastructure disaster humor.
Qwen's Small Model Offensive
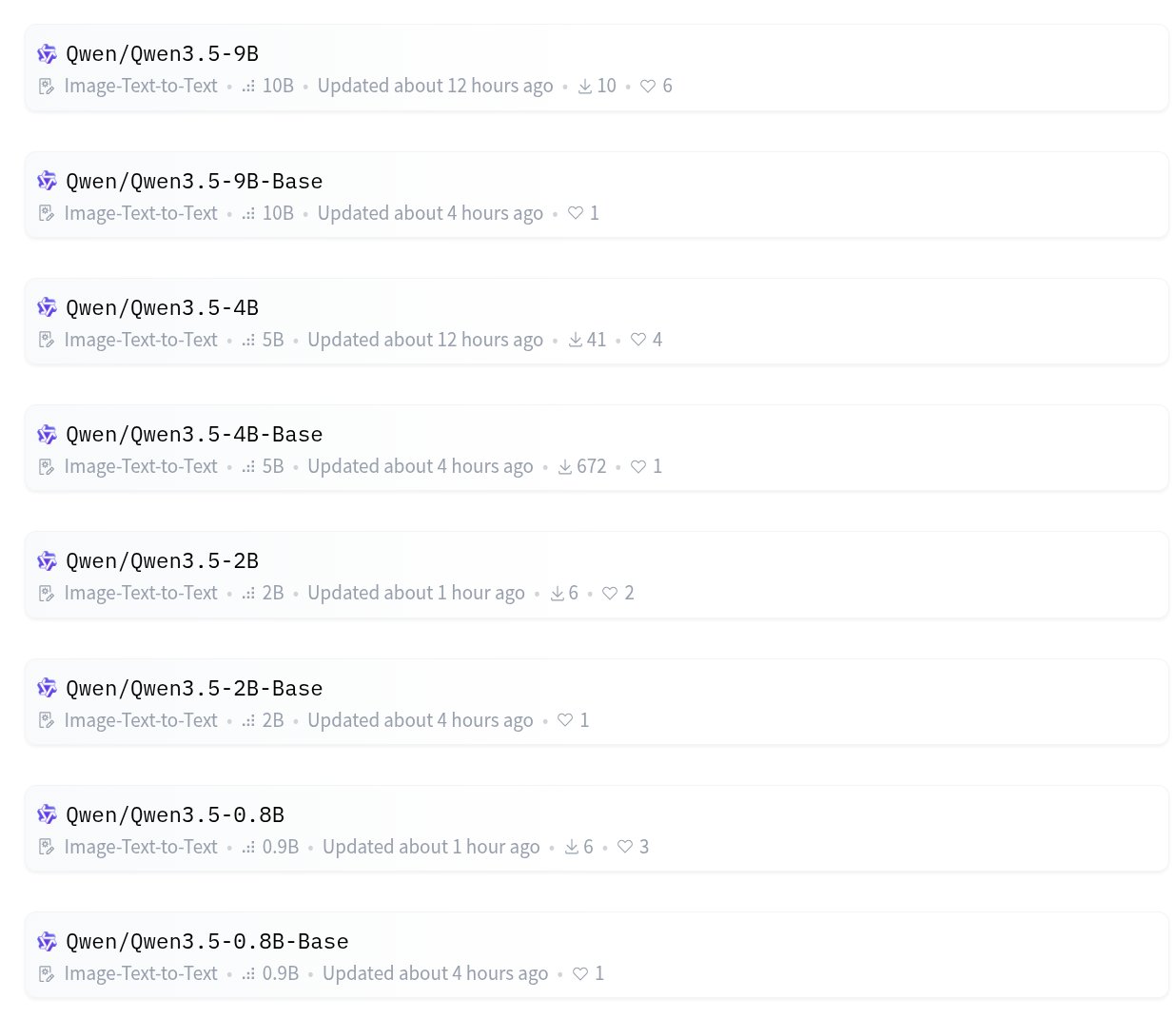
Qwen made a serious play for the local inference market today, releasing a family of dense models at four size points and a coding-specific model that's generating real excitement. The breadth of the release is what stands out. Rather than dropping a single flagship, they shipped models at 0.8B, 2B, 4B, and 9B parameters, all supporting both image-to-text and text-to-text, all open source. This isn't a research preview. It's a product line designed to cover every hardware tier from phones to workstations.
@TheAhmadOsman captured the lineup: "Qwen 3.5 9B/9B-Base, 4B/4B-Base, 2B/2B-Base, 0.8B/0.8B-Base. Small. Dense. Opensource." Meanwhile, @sukhdeep7896 zeroed in on the coding angle: "Qwen3-Coder-Next... Only 3B active parameters but beats models with 10x-20x MORE parameters on SWE-Bench-Pro. PLUS: They launched Qwen Code CLI, the best open-source alternative to Claude Code. 1,000 free requests/day."
The sovereignty narrative hit especially hard. @TukiFromKL laid it out plainly: "Download LM Studio. Search Qwen 3.5. Grab the MLX versions. Load them. You now have unlimited AI on your own machine. Nobody can take it away from you. Not a company. Not a government. Not a terms of service update." It's a compelling pitch, and the hardware bar keeps dropping. A $600 Mac Mini running a 4B model locally is a genuinely useful setup for many coding tasks.
@jandotai also entered the small coding model space with Jan-Code-4B, tuned specifically for "practical day-to-day tasks" like generation, refactors, debugging, and tests, all runnable locally in their Jan application. The small coding model category is getting crowded fast.
But the practical reality of local models in agentic workflows is messier than the hype suggests. @sudoingX shared hard-won experience running Qwen models through Claude Code's harness via llama.cpp: "the chain will break every 3 to 5 minutes. tool call fails. flow stops... the model is fine. the harness chokes on local inference latency." Their solution was switching to OpenCode, which trades chain breakage for occasional loops where the model "forgets what it already read and repeats the same tool call." As they put it: "a loop you can interrupt. a broken chain kills your momentum." This is the kind of real-world friction that benchmarks don't capture, and it matters enormously for anyone trying to build reliable local agent loops.
Claude Code's Expanding Toolkit
The Claude Code ecosystem continued to evolve today with contributions focused on two persistent problems: making agents remember context across sessions, and giving them access to more of the desktop environment. These aren't flashy capability jumps, but they address real friction points that anyone building with coding agents hits within the first week.
@ArtemXTech shared an approach titled "Grep Is Dead: How I Made Claude Code Actually Remember Things," tackling the perennial challenge of session persistence. Context management remains one of the biggest practical limitations of agentic coding. Models that can write excellent code in a single session lose all that accumulated understanding the moment the session ends, and naive approaches like grepping through old logs don't scale.
On the tooling side, @ctatedev announced a significant addition to the agent-browser skill set: "You can now control desktop apps built with Electron, including Discord, Figma, Notion, Spotify and VS Code. Or, use it to debug your own Electron app." The ability to add this to any coding agent with a single npx command lowers the barrier to entry considerably. This is notable because it extends agent capabilities beyond the terminal and file system into GUI applications, which is where a huge amount of developer workflow actually lives.
And then there was the outage. @darylginn's perfectly deadpan "Claude is down, hope you all remember what a variable is" resonated because it captured a real dependency that's formed. @paularambles added the other side of that coin: "you can tell claude planned this because it was scoped for four weeks but actually completed in under an hour." Both jokes land because they reflect genuine shifts in how developers work. The dependency is real, the productivity gains are real, and the brittleness when the service goes down is also very real.
The Agent-Native Economy
A growing cluster of voices is arguing that the next decade of software won't just use AI as a feature but will be rebuilt from scratch for AI consumers. The argument goes beyond "add an API" into something more fundamental about who software is designed for in the first place.
@gregisenberg made the broadest case: "Go look at every saas tool you use. Notion, Slack, Stripe etc. Now ask: 'what's the version of this that's built purely for agents?' Agent-native payments, agent-native communication, agent-native memory etc. Every single category gets rebuilt." It's a maximalist position, but the directional logic is sound. If agents become primary users of software services, the entire UX layer becomes unnecessary overhead, and the value shifts to API design, reliability, and machine-readable output.
@ryancarson drove at the same idea from a more practical angle: "It's time for you to think about how an agent can use your app via CLI. In the future, none of us (including our agents) are going to want to log in to a web interface to do anything. Agents will do everything via CLI + writing their own code." This is already happening in developer tools. The rise of MCP servers, Claude Code skills, and agent-browser integrations are all examples of software exposing itself to machine consumers.
@Saboo_Shubham_ contributed a practitioner's perspective with a breakdown of building "OpenClaw Agents that actually get better Over Time," sharing their exact stack after 40 days of iteration. The convergence between these posts suggests that the tools for building agent-native software are maturing past the proof-of-concept stage. Whether the "machine-to-machine economy" materializes at the scale @gregisenberg envisions is debatable, but the developer tooling layer is already being rebuilt with agents as first-class consumers, and that trend is accelerating week over week.
Sources
How to set up OpenClaw Agents that actually get better Over Time (My exact stack after 40 Days)
My agents get smarter every day. All I do is talk to them. Not tweak prompts. Not swap models. Not rebuild the architecture. Just talk. Give feedback....
Agent Harness is the Real Product
Everyone talks about models. Nobody talks about the scaffolding. The companies shipping the best AI agents today- Claude Code, Cursor, Manus, Devin, S...
The "holy shit" moment when I realized agent-browser can control Slack npx skills add vercel-labs/agent-browser --skill slack https://t.co/TytaOHe0xP



Anthropic has launched free courses to master AI with certificates for $0.00 https://t.co/hwJvuJHIdo
Grep Is Dead: How I Made Claude Code Actually Remember Things
Every conversation with Claude Code starts from zero. Here's how I fixed that with a local search engine and a skill that loads your full context befo...

JUST IN: Pope Leo tells priests to stop using ChatGPT to write sermons. https://t.co/6qDbuB4Cg8
NEW OPENSOURCE MODELS INCOMING We're getting four new Qwen 3.5 models today > Qwen 3.5 9B > Qwen 3.5 4B > Qwen 3.5 2B > Qwen 3.5 0.8B Everybody is starting to say Buy a GPU ;) https://t.co/VvjbeYRIgB
Claude Cowork Masterclass for Beginners (full tutorial)
Most people are still using Claude like a chatbot. Ask a question, get an answer, repeat. That's leaving 90% of the value on the table. Claude Cowork ...
Qwen3.5-9B is an incredibly strong little model you can download and run on your computer. It can takes images as input, can think, and call tools. Requires only ~7GB to run locally 🤯🚀 https://t.co/ePyQSKmaZH