Claude Code Gets Remote Control and Cursor Ships Cloud Computers as Qwen 3.5 Closes the Local AI Gap
The agent IDE race hit a new gear as Claude Code launched Remote Control for mobile and Cursor introduced cloud computers that record video demos of their work. Qwen dropped a model series where a 35B MoE model beats its 235B predecessor. And the AI adoption gap in traditional industries became the day's most relatable thread.
Daily Wrap-Up
February 24th was one of those days where you could feel the developer tooling landscape shifting under your feet. Both Claude Code and Cursor shipped features that fundamentally change how developers interact with their agents, pushing the "you don't need to be at your desk" narrative forward in concrete ways. Claude Code now lets you kick off a task in your terminal and monitor it from your phone, while Cursor agents can spin up cloud computers, build your feature, and send you a video recording of the result. These aren't incremental improvements. They're redefining what "async" means for engineering teams.
The Qwen 3.5 release quietly stole the technical crown for the day. A 35B mixture-of-experts model that activates only 3B parameters now outperforms its 235B predecessor from six months ago. That's a 6.7x reduction in size with better benchmarks across the board, and people are already running it locally on consumer GPUs at 72 tokens per second. The implications for local inference and on-device AI are hard to overstate. Meanwhile, an entire thread emerged around the uncomfortable truth that most businesses outside the tech bubble haven't even heard of Claude, let alone integrated AI into their workflows. The juxtaposition of bleeding-edge tooling announcements against stories of executives managing eight-figure budgets through email chains was equal parts sobering and clarifying about where the real opportunity lies.
The most entertaining moment was easily @Johnie36149708's satirical post about asking a 63-year-old plumber why he doesn't use "a RAG vector db on his own vibe coded app to increase ARPU," a perfect skewering of the tech bubble's blind spots. The most practical takeaway for developers: if you're not already experimenting with cloud-based agent sandboxes (Cursor's cloud computers, Cloudflare Sandboxes, or similar), start now. The pattern of "agent works in isolated environment, reports back with proof of work" is becoming the default workflow, and the tooling just got dramatically more accessible.
Quick Hits
- @claudeai announced Cowork and enterprise plugin updates for team-customized Claude workflows.
- @AnthropicAI is separating unilateral safety commitments from industry recommendations, plus new Frontier Safety Roadmaps and Risk Reports.
- @steipete clarified OpenClaw's security model: it's a personal assistant (one user, many agents), not a multi-tenant bus. Stop filing reports trying to force it otherwise.
- @jessegenet showed how to use OpenClaw for hands-on Montessori education with young kids, proving AI doesn't have to mean more screen time.
- @trq212 noted Claude in Chrome is significantly faster with Quick Mode, and pairs with Opus 4.6 fast for "blazing speeds."
- @BraydenWilmoth shared that a NextJS rebuild cost $1,100 with AI assistance and came out 4.4x faster and 57% smaller.
- @Av1dlive predicted solo founder billionaires are coming, citing a workflow article by @elvissun.
- @AtlasForgeAI published a guide on building nine meta-learning loops for OpenClaw agents.
- @Clad3815 updated the GPT Plays Pokemon FireRed experiment with a weaker harness, noting GPT-5.2 is strong enough to handle less scaffolding.
- @kurtinc shared from a Shopify partner briefing that AI agents pull the first 6,000 characters of product descriptions as their source of truth, ignoring meta descriptions and SEO titles entirely.
- @d4m1n said dev friends from big corps tried Claude Code and immediately understood what "being in the top 1%" means.
- @devops_nk and @zivdotcat both posted memes about Claude updates and usage limits, respectively, capturing the community's love-hate relationship with rate caps.
- @Hesamation nailed the vibe of starting a new AI side project: dopamine rush followed by existential dread and a trip to the dead idea graveyard.
- @AlRaion shared a Claude-related link without commentary.
- @leerob noted that Cursor's cloud computer approach works for anything in a container, including testing Cursor itself.
Agent IDEs Get Cloud Computers and Remote Control
The biggest story of the day was the parallel evolution of the two leading agent-powered development environments. Both Claude Code and Cursor shipped features that push development further from the traditional "developer staring at a terminal" model, and the combined effect suggests we're entering a new phase of how software gets built.
Claude Code's Remote Control feature lets you start a coding task in your terminal, then pick it up from your phone or the Claude web app while you're away from your desk. As @claudeai put it: "Claude keeps running on your machine, and you can control the session from the Claude app." @bcherny, who's been using it daily, asked for feedback. @minchoi summed up the community reaction: "It's over... for touching grass. You can now Remote Control your Claude Code from your phone." @ryancarson connected it to a larger trend: "we're going to start to see something more like an ADE versus an IDE where the iteration loop is closed more and more by the agent."
Cursor's announcement was arguably even more dramatic. @leerob introduced cloud computers for Cursor agents: "Agents can onboard to your codebase, use a cloud computer to make changes, and send you a video demo of their finished work." The official @cursor_ai account framed it perfectly: "Cursor now shows you demos, not diffs." @karankendre captured the collective disbelief: "So you're telling me a vscode clone can not only review my code but also test the feature on a cloud computer and send me a demo video of the whole process." @benln simply called it a "huge launch."
Adding to the tooling expansion, @stephenhaney released Paper Desktop, a canvas that works with Cursor, Claude Code, and Codex, letting any agent read and write HTML to a shared visual surface. The throughline across all these announcements is clear: the agent doesn't just write code anymore. It runs it, tests it, records it, and reports back. The developer's role is shifting from implementer to reviewer, and these tools are making that transition feel natural rather than forced.
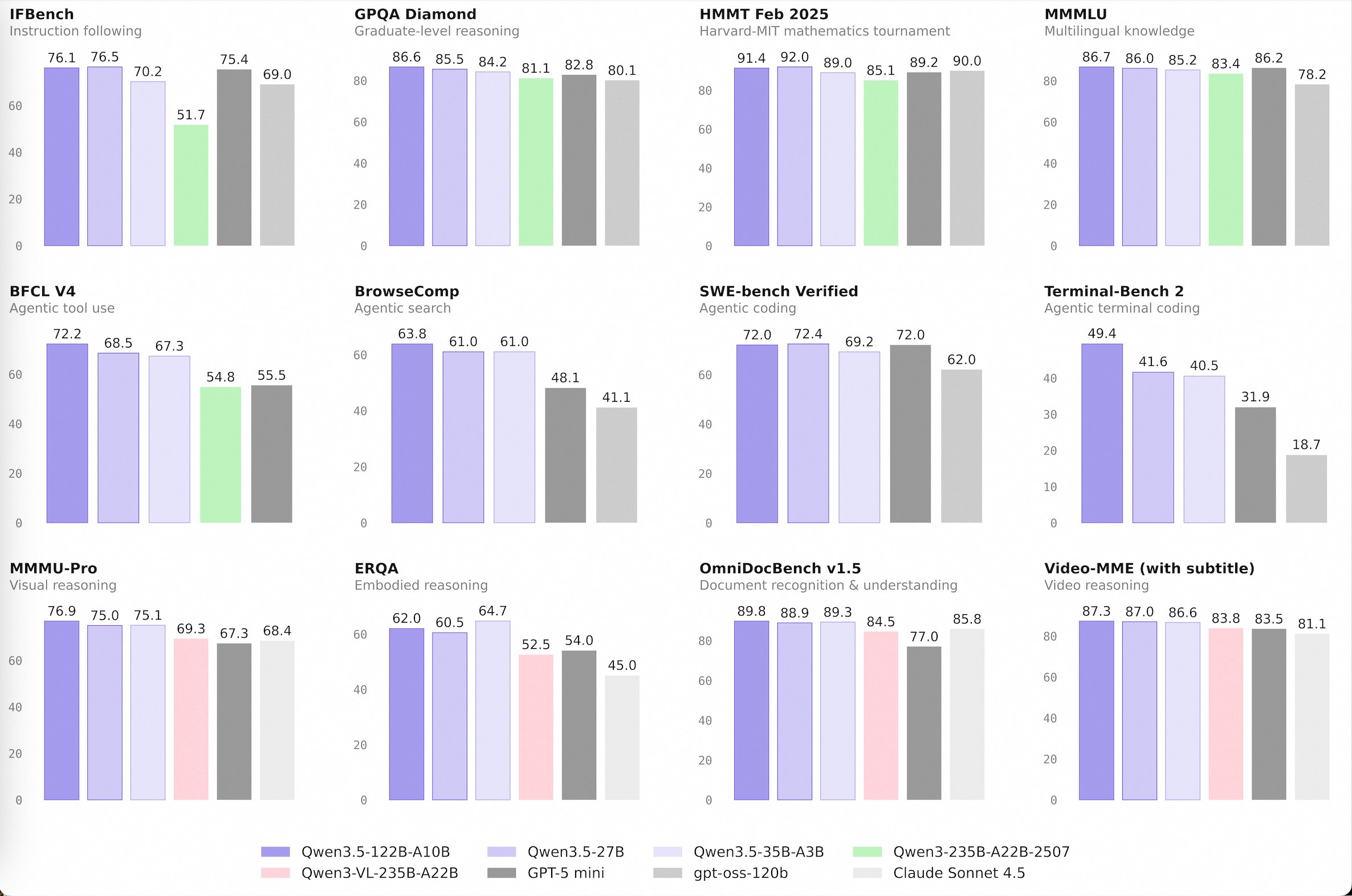
Qwen 3.5 Shrinks the Gap Between Local and Frontier
Alibaba's Qwen team dropped the Qwen 3.5 Medium Model Series, and the numbers demand attention. The release includes four models, with the headline being that Qwen3.5-35B-A3B, a mixture-of-experts model activating just 3 billion parameters, now surpasses the previous Qwen3-235B-A22B. As @Alibaba_Qwen emphasized, "better architecture, data quality, and RL can move intelligence forward, not just bigger parameter counts."
@itsPaulAi put the trajectory in perspective: "In 6 months they've trained a model which is 6.7x smaller than the previous one, better in all benchmarks, available locally on a laptop. We're just at the very beginning of local LLMs." @TheAhmadOsman was equally impressed, noting three new state-of-the-art results "beating Sonnet 4.5 in many benchmarks" while being runnable on consumer hardware. The practical proof came from @mkurman88: "Running Qwen 3.5 35B A3B locally on an RTX 3090 24GB, with 72 TPS."
The larger significance isn't just benchmark numbers. Each generation of efficient open models narrows the window where cloud-only inference has a meaningful quality advantage. When a model that fits on a single consumer GPU matches or beats a model that required specialized infrastructure six months ago, the economics of AI deployment change for everyone building on top of these models.
Agents Are the New Distribution Channel
A cluster of posts coalesced around a theme that's been building for months: software distribution is being rewritten by AI agents. @aakashgupta synthesized Karpathy's argument forcefully: "The new distribution channel for software is agents. Agents don't browse your marketing site, watch your demo video, or click through your onboarding flow. They call your CLI. They hit your MCP server." He cited MCP's growth to 97 million monthly SDK downloads and noted that "a beautiful React dashboard is worthless to an agent trying to pull data into a workflow at 3am."
Google entered the agent builder space directly. @itsPaulAi described their new offering in Google Opal: agent blocks programmable in plain English with native tool calling, session memory, and conditional logic, calling it "probably the easiest way to build AI agents I've seen so far." @rauchg from Vercel connected the dots with a different angle, observing that at a recent hackathon, "many startups just presented their agents as Slack @ mentions. They incidentally tended to be the products that were easiest to grasp and adopt."
@shiri_shh captured the endpoint of this trend with dark humor: "agent writes the code, agent reviews the pr, agent runs tests in cloud, agent sends demo video." Whether you find that exciting or terrifying probably depends on where you sit in the value chain.
The AI Adoption Gap in Traditional Industries
While AI Twitter debated agent architectures and model benchmarks, @damianplayer dropped a reality check that resonated widely. He described talking to executives at a mid-size company: "no AI tools in their workflow. zero. Still running everything through email chains + manual reports. One of them didn't know what Claude was." He followed up by clarifying he wasn't talking about tech companies but about "boring. construction, insurance and property management. the businesses that make up most of the economy and none of AI twitter."
@chriswiser replied: "Half the world doesn't know Claude exists and the other half is terrified of it." @lucky_strikes_x went further: "We are in a mega bubble. Ask 100 people on the street if they know what Claude is." These posts serve as a useful counterweight to the breathless pace of announcements above. The gap between what's technically possible and what's actually deployed in the broader economy remains enormous, and that gap represents both risk (for AI companies counting on adoption) and opportunity (for anyone who can bridge it).
Developer Workflow Patterns Keep Evolving
Beyond the major product launches, the community shared several workflow innovations worth tracking. @addyosmani offered sharp advice on AGENTS.md files: "Auto-generated AGENTS(.md) files hurt agent performance and inflate costs because they duplicate what agents can already discover. Human-written files help only when they contain non-discoverable information." He advocated for hierarchical AGENTS.md files scoped to specific directories rather than monolithic root-level configs.
@dani_avila7 replaced Claude Code's default worktree command with a custom hook that creates branches in sibling directories rather than nesting them inside the project. @alexhillman shared his api2cli skill that walks through API discovery, designs a CLI, and wraps it with a skill, calling it "the easiest way to give your agent access to nearly any API." On the infrastructure side, @_ashleypeacock highlighted Cloudflare Sandboxes' new backup/restore capability to R2, and @ashtom announced that the Entire CLI and opencode now work together as "a universal reasoning layer for all agents."
Polished AI Output Is Making Us Worse at Thinking
@aakashgupta surfaced an Anthropic study tracking 9,830 conversations that found a troubling pattern: "when Claude produces polished outputs like code or documents, users are 5.2 percentage points less likely to catch missing context and 3.1pp less likely to question the reasoning." Users who iterated on responses showed 2.67 additional fluency behaviors versus 1.33 for those who accepted the first output, and questioned reasoning 5.6x more often.
This connects to @kimmonismus quoting a prediction that by early 2027, AI systems could "fully automate, or otherwise dramatically accelerate, the work of large, top-tier teams of human researchers." If we're already struggling to critically evaluate AI output when we're actively engaged, the challenge only grows as these systems become more capable. The takeaway isn't to use AI less, but to treat every output as a first draft, no matter how polished it looks.
Sources
Q
🚀 Introducing the Qwen 3.5 Medium Model Series
Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27B
✨ More intelligence, less compute.
• Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507 and Qwen3-VL-235B-A22B — a reminder that better architecture, data quality, and RL can move intelligence forward, not just bigger parameter counts.
• Qwen3.5-122B-A10B and 27B continue narrowing the gap between medium-sized and frontier models — especially in more complex agent scenarios.
• Qwen3.5-Flash is the hosted production version aligned with 35B-A3B, featuring:
– 1M context length by default
– Official built-in tools
🔗 Hugging Face: https://t.co/wFMdX5pDjU
🔗 ModelScope: https://t.co/9NGXcIdCWI
🔗 Qwen3.5-Flash API: https://t.co/82ESSpaqAF
Try in Qwen Chat 👇
Flash: https://t.co/UkTL3JZxIK
27B: https://t.co/haKxG4lETy
35B-A3B: https://t.co/Oc1lYSTbwh
122B-A10B: https://t.co/hBMODXmh1o
Would love to hear what you build with it.
S
Hello!
Today we're releasing Paper Desktop
Paper is now a canvas for Cursor, Claude Code, Codex. Any agent can read and write html to Paper.
• push or pull from your codebase
• pull real data from anywhere
• less work, more design
What will you ship? Sound on 🎶 https://t.co/2E6OYWpmeP
A
How to Build Nine Meta-Learning Loops for Your OpenClaw Agent
How to Build Nine Meta-Learning Loops for Your OpenClaw Agent
TL;DR: Agents are smart within sessions and stupid across them. The fix is structural feedback loops in your agent's files: failures become guardrails...