Stripe Ships 1,300 AI Pull Requests Weekly as Agent Orchestration Tools Proliferate
Anthropic had a massive day, announcing Claude Code hackathon winners, launching a security vulnerability scanner, and shipping desktop preview features. Meanwhile, Agent Orchestrator open-sourced its 30-parallel-agent system showing 500+ agent-hours in 24 human-hours, and Stripe revealed 1,300 weekly PRs are now fully AI-generated.
Daily Wrap-Up
The throughline today is that AI-assisted coding has quietly crossed from "impressive demo" to "production infrastructure." Stripe is generating the equivalent output of 565 engineers through AI PRs. A solo developer built a classified-intelligence-grade geospatial platform over a weekend. And someone open-sourced a system for running 30 coding agents in parallel, claiming they stopped writing code entirely after day four. These aren't future projections. They're deployment reports.
Anthropic had a particularly busy day, stacking announcements like they were trying to win their own hackathon. The Claude Code hackathon results showcased creative applications from MIDI-controlled generative music to visual programming for kids, while the new Claude Code Security tool and desktop preview features signal that Anthropic is investing heavily in making Claude Code a complete development environment rather than just a chat interface. The hackathon's second-place winner, a coding tool where kids stack colored blocks while AI agents write the actual code behind the scenes, was the day's most heartwarming entry. Built by @JonMcBee and first tested by his 12-year-old daughter, it's exactly the kind of thing that makes you optimistic about where this is heading.
The most entertaining subplot was watching @agent_wrapper casually mention they used Agent Orchestrator to build Agent Orchestrator, which is either the most recursive flex in software history or a sign we've entered a very strange timeline. The most practical takeaway for developers: invest in your agent infrastructure now. Whether it's @TheAhmadOsman's emphasis on explicit specs and domain-driven design, @trq212's insight about designing for prompt caching first, or simply organizing your codebase so agents can navigate it, the returns on structured AI workflows are compounding fast and the gap between teams that have this figured out and teams that don't is widening every week.
Quick Hits
- @hxiao reacting to what appears to be a project that distilled every major proprietary model into open-source equivalents. The OSS-vs-proprietary tension continues.
- @alxfazio introduced Plankton, billing it as "the slop guard LLMs can't cheat," targeting AI-generated content detection.
- @RayFernando1337 gave a shoutout to Safinaz as "a top tier agentic engineer" with "amazing UX ideas."
- @dillon_mulroy declared "MCP is so back," suggesting the protocol is gaining renewed momentum.
- @kumareth demoed an agent that browses your history, identifies your tools (CRMs, notes apps, calendars), and imports everything into a structured workspace. Impressive and slightly terrifying.
- @aiamblichus raised privacy concerns about OpenAI employees reading and debating users' private ChatGPT conversations, warning about surveillance implications.
- @jspujji highlighted Wideframe, a Claude-powered video editing tool his team found capable of searching, scrubbing, organizing, and sequencing video, estimating a potential 50% reduction in ad production time.
- @gdb and @OpenAIDevs announced Codex meetups rolling out across cities through their ambassador community.
- @flaviocopes declared agentic coding "the ADHD dream," which honestly resonates.
- @Grummz showcased Taalas, a hardcoded on-chip LLM hitting 17,000 tokens per second. Local inference at that speed changes the calculus on what needs to go to the cloud.
- @NetworkChuck sat down with @Jhaddix to discuss becoming an AI hacker, bridging the security and AI communities.
- @meta_alchemist teased that Spark goes open source tomorrow.
- @nurijanian praised an integrated UI/UX skill tool, calling it "incredible for when you have a clear view of what you want."
- @trq212 shared a deep insight: designing agents for prompt caching first is fundamental, saying "almost every feature touches on it somehow." Worth reading for anyone building agent tooling.
Anthropic's Claude Code Blitz: Hackathon, Security, and Desktop All in One Day
Anthropic stacked announcements today with the energy of a company that knows it's in a sprint. The Claude Code hackathon wrapped with 500 builders exploring what they could do with Opus 4.6, and the winners showcase genuine creativity beyond the typical chatbot demo. @claudeai revealed the results, noting that "Claude Code itself started as a hackathon project. Now it's how thousands of founders build."
The creative exploration prize went to Conductr by Asep Bagja Priandana, where you play chords on a MIDI controller and Claude directs a four-track generative band around your playing, running on a C/WASM engine at roughly 15ms latency. The second-place winner, Elisa by @JonMcBee, is a visual programming environment for kids where snapping blocks together triggers Claude agents to build real code behind the scenes. As @cryptopunk7213 put it: "this turns coding into a game. Kids all over the world can now have fun learning a very valuable skill."
Beyond the hackathon, Anthropic launched two significant product updates. Claude Code Security entered limited research preview as a vulnerability scanner that suggests targeted patches for human review, positioning it against traditional SAST tools by promising to catch issues "that traditional tools often miss." And Claude Code Desktop got a meaningful upgrade: it can now preview running apps, review code, and handle CI failures and PRs in the background. @trq212 was already sold, calling it "easily the best way to do any frontend work right now. With Preview it can spin up your app, take screenshots and iterate until it's right." The preview capability specifically turns Claude Code from a text-in-text-out tool into something closer to a visual development partner, which is a meaningful distinction for frontend work where seeing the output matters as much as reading the code.
The 30-Agent Orchestra: Multi-Agent Orchestration Hits Open Source
The most technically ambitious announcement of the day came from @agent_wrapper, who open-sourced the system they use to manage 30 parallel AI coding agents per person. The numbers are staggering: "40K lines of TypeScript. 3,288 tests. 17 plugins. Built in 8 days by the agents it orchestrates." The claimed leverage is 20x, with 500+ agent-hours compressed into 24 human-hours, and 86 of 102 PRs created entirely by AI. @morganlinton simply noted "500+ agent hours, wild."
The practical workflow details are what make this interesting beyond the headline numbers. @agent_wrapper described casually telling the orchestrator to "ask all sessions with merge conflicts to fix them," treating conflict resolution as a delegated task rather than a manual chore. @BHolmesDev dove into the technical architecture, explaining that "agents are triggered when they are @-mentioned in a chat thread with a serverless invokeAgent(). The agent gets spawned in a cloud sandbox using Oz."
The cloud-vs-local debate for agent execution is heating up. @BHolmesDev argued that "worktrees are a band-aid solution. Putting agents in cloud runners lets you actually close the laptop, and gives agents a space to check their work with sandboxed screenshotting and e2e testing." Meanwhile, @mattpocockuk shared a more structured workflow: idea to PRD to issues to a kanban board to an automated Ralph loop, with manual QA as the final human checkpoint.
The counterpoint to all this automation came from @TheAhmadOsman, who cautioned that "discipline matters more than model capabilities." His recipe for success with coding agents: modularity, domain-driven design, painfully explicit specs, and excessive documentation. "If your docs don't answer where, what, how, why, the agent will guess, and guessing is how codebases die." It's a grounding reminder that scaling to 30 agents means scaling your documentation and architecture to match.
Production AI by the Numbers: Stripe, Sam Altman, and the Acceleration Curve
The data points coming out of production deployments are getting harder to dismiss as early-adopter enthusiasm. @aakashgupta broke down Stripe's numbers in detail: 1,300 of their weekly PRs are now fully AI-generated, zero human-written code. That represents the equivalent output of roughly 565 engineers at a median comp of $270K, meaning approximately $150M in annual equivalent value. "And this went from 1,000 to 1,300 in a single week. A 30% increase in AI engineering output with no hiring pipeline, no onboarding, no equity grants."
@garrytan captured the startup founder perspective: "This is the age of CEOs crushing 10 people's work with Claude Code in nights and weekends." Whether you find that inspiring or concerning probably depends on which side of the leverage you're on, but the productivity claims are consistent across multiple independent reports.
The most ominous note came from @kimmonismus, quoting Sam Altman: "The inside view at the companies of looking at what's going to happen, the world is not prepared. We're going to have extremely capable models soon. It's going to be a faster takeoff than I originally thought." Two members of the Codex team, @thsottiaux and @deredleritt3r, independently echoed this after their offsite, both suggesting that current coding agents will feel "primitive" within about ten weeks. When the people building the tools are surprised by the acceleration, that's a signal worth paying attention to. The gap between companies investing in AI tooling infrastructure and those waiting for off-the-shelf solutions is widening from a gap into a chasm.
One Dev, One Weekend, One Intelligence Platform
The creative ceiling for what a single developer can build with frontier models keeps rising. @bilawalsidhu built what he described as a mashup of Google Earth and Palantir using Claude 4.6 and Gemini 3.1, complete with real-time plane and satellite tracking, live traffic cameras in Austin, panoptic detection, and a UI skinned to look like a classified intelligence system. "EO, FLIR, CRT. Got a bunch more stuff on the roadmap. This is fun." @minchoi's reaction captured the broader implication: "A solo dev just vibe coded what Palantir charges governments millions for. The defense tech disruption is going to be something."
@worldofray demonstrated similar leverage on the creative side, building a three.js/WebGL project where "Gemini and Claude made all the decisions" on the implementation. These projects share a pattern: a human with domain vision using AI as a force multiplier to build things that previously required teams. The question isn't whether this changes the economics of software development. It's how fast the industries built on the old economics can adapt.
Sources
R
@idkAgasta @bilawalsidhu Hey - thanks! Gemini / Claude made all the decisions but it's just three.js / webgl - code fully available on GitHub
https://t.co/UqFtN6n8zj
A
introducing Plankton: the slop guard LLMs can't cheat
introducing Plankton: the slop guard LLMs can't cheat
LLM coding agents don’t follow your linting rules. You end up in this endless loop of copy-pasting pre-commit errors back into the agent, watching it ...
S
90s sitcoms worked because no one had a cell phone & uncertainty was a feature.
people had to miss each other & they had to guess. also they had to commit to plans & live with the consequences. if you walked out the door, you were genuinely unreachable.
i wish i could live this life sometimes.
B
2/ Use worktree mode in the Desktop app
If you prefer not to use terminal, head to the Code tab in the Claude Desktop app and ☑️ worktree mode
https://t.co/LgI5LR860x https://t.co/HcstsNcA7i

B
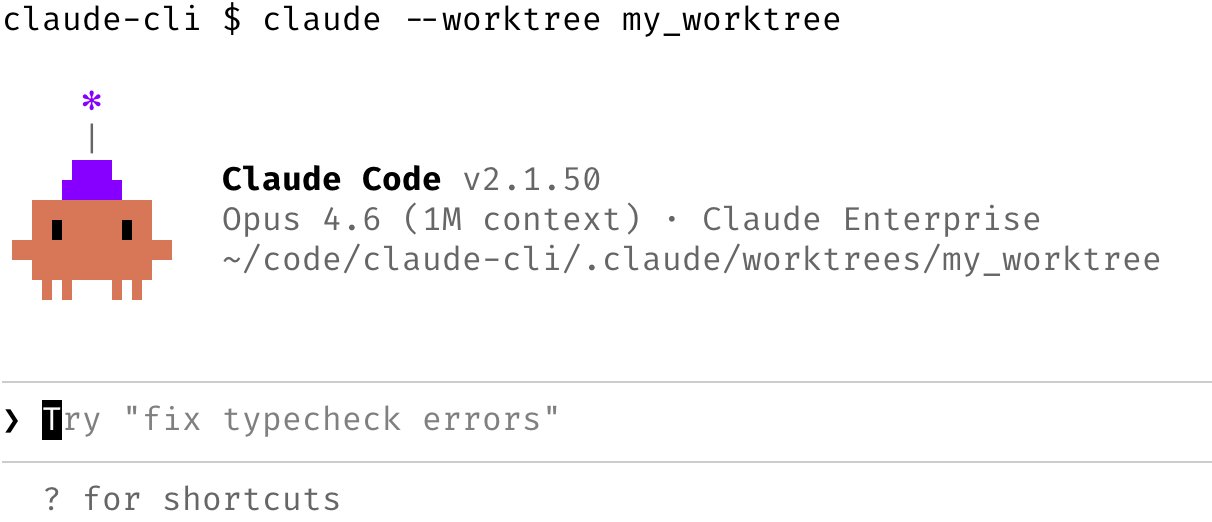
1/ Use claude --worktree for isolation
To run Claude Code in its own git worktree, just start it with the --worktree option. You can also name your worktree, or have Claude name it for you.
Use this to run multiple parallel Claude Code sessions in the same git repo, without the code edits clobbering each other.
You can also pass the --tmux flag to launch Claude in its own Tmux session.
B
Introducing: built-in git worktree support for Claude Code
Now, agents can run in parallel without interfering with one other. Each agent gets its own worktree and can work independently.
The Claude Code Desktop app has had built-in support for worktrees for a while, and now we're bringing it to CLI too.
Learn more about worktrees: https://t.co/JFkD2DrAmT

B
4/ Custom agents support git worktrees
You can also make subagents always run in their own worktree. To do that, just add "isolation: worktree" to your agent frontmatter https://t.co/Z87gX0Y1Vw

B
3/ Subagents now support worktrees
Subagents can also use worktree isolation to do more work in parallel. This is especially powerful for large batched changes and code migrations.
To use it, ask Claude to use worktrees for its agents.
Available in CLI, Desktop app, IDE extensions, web, and Claude Code mobile app.

V
In 20 years, vibe coders will look at the Linux kernel repo the way we look at the pyramids. In awe, unable to imagine how they managed to drag all those giant stones and pile them up in the middle of the desert.
C
🚨 SAM ALTMAN: “People talk about how much energy it takes to train an AI model … But it also takes a lot of energy to train a human. It takes like 20 years of life and all of the food you eat during that time before you get smart.” https://t.co/vRuVnnmzjB
M
LOVE seeing this be built into CC itself
Especially parallelizing subagents makes spawning a bunch of agents to do a lot of work a lot simpler.
Especially when merge conflicts are so cheap.
B
bcherny
@bcherny
Introducing: built-in git worktree support for Claude Code Now, agents can run in parallel without interfering with one other. Each agent gets its own worktree and can work independently. The Claude Code Desktop app has had built-in support for worktrees for a while, and now we're bringing it to CLI too. Learn more about worktrees: https://t.co/JFkD2DrAmT
D
Ghostty lets you control the opacity of unfocused splits.
Just add this to ~/.config/ghostty/config:
unfocused-split-opacity = 0.85
Super useful when working across multiple panes, you always know where your focus is.
If the opacity doesn't load on startup, hit cmd+shift+, to reload your config.