Vibe-Coded Games Hit Roblox Frontpage as AI Token Costs Threaten to Outpace Developer Salaries
Anthropic published research analyzing millions of interactions to understand how much autonomy users grant AI agents, revealing software engineering dominates at 50% of agentic tool calls. Meanwhile, the All-In Podcast surfaced a brewing crisis: AI token costs are approaching and sometimes exceeding employee salaries, forcing companies to think about "token budgets" per developer. The vibe coding movement continued its march with a Roblox game built entirely by Claude and a game vibe-coded in a week.
Daily Wrap-Up
The big story today is Anthropic pulling back the curtain on how people actually use AI agents in practice. Their research analyzed millions of interactions across Claude Code and the API, and the headline number is striking: software engineering accounts for roughly half of all agentic tool calls. That's not surprising to anyone building with these tools daily, but what matters is the framing. Anthropic is explicitly positioning this as a safety and monitoring challenge, noting that as "the frontier of risk and autonomy expands, post-deployment monitoring becomes essential." This is a company trying to set industry norms before regulators do, and the data-driven approach gives them credibility that abstract safety arguments don't.
The counterpoint to all this agent enthusiasm came from an unexpected source. @chamath and @Jason on the All-In Podcast laid out a problem that's going to hit a lot of teams this year: token costs are real, they scale fast, and nobody has a good framework for managing them yet. Jason mentioned hitting $300/day per agent "instantly," which annualizes to $100K, roughly the cost of a junior engineer. Chamath's response about needing "token budgets" for developers signals that we're entering a phase where AI usage has to justify itself economically, not just technically. This is the kind of unsexy operational problem that separates companies that successfully adopt AI from those that burn cash on it.
The most entertaining thread of the day was @steipete pushing back on the narrative that his 43+ GitHub repos represent "failures," pointing out they're components of the OpenClaw ecosystem. It's a good reminder that building ambitious software requires building an army of supporting tools, and that's especially true in the agent era where you need scaffolding, harnesses, and infrastructure before you can ship the thing people actually see. The most practical takeaway for developers: if you're running agents against paid APIs, start tracking your token spend per task now. The teams that build cost awareness into their agent workflows early will have a significant advantage over those who get surprised by a five-figure monthly bill.
Quick Hits
- @jsnnsa shared a game vibe-coded in a week, arguing "if you have taste you can create anything now." The Three.js visuals apparently look legitimately good these days.
- @ryanvogel is benchmarking AI sandboxes across Cloudflare, Vercel, Daytona, and others, which should produce a useful comparison for anyone building agent infrastructure.
- @RayFernando1337 highlighted a free CLI tool by Rudrank that automates the App Store submission process, including TestFlight, signing, and screenshots. Worth bookmarking if you're shipping iOS.
- @CreatedByJannn captured the eternal tension between AI's cautious timelines and builder impatience: the AI suggests 12-24 months, the developer says "we are shipping this today."
- @Preda2005 showcased Seedance 2.0 generating a father-daughter fight scene that looks like video game cinematics, calling it "prompt-level creation" that used to require a full studio.
- @gdb and @thsottiaux are both posting about OpenAI's Codex team, with the team gathering in person to align on what's next and actively hiring.
- @beffjezos posted a screenshot of "peak agentic engineer performance" without much context, but the quote-tweet energy suggests it was either impressively productive or hilariously broken.
- @justsisyphus simply said "wow wow wow @AnthropicAI," presumably in response to the autonomy research or recent model drops.
Anthropic's Agent Autonomy Research
Anthropic's publication today represents one of the first serious attempts to empirically measure how AI agents are being used in the wild. Rather than speculating about what autonomous AI might do, they went and looked at what it's actually doing across millions of real interactions. The finding that software engineering makes up roughly 50% of agentic tool calls confirms what the developer community already feels intuitively, but the research is more interesting for what it says about the other 50%.
@AnthropicAI framed the work as both descriptive and prescriptive: "We analyzed millions of interactions across Claude Code and our API to understand how much autonomy people grant to agents, where they're deployed, and what risks they may pose." The emphasis on risk and autonomy levels suggests they're building a taxonomy, not just counting API calls. Their follow-up post drove the point home: "As the frontier of risk and autonomy expands, post-deployment monitoring becomes essential. We encourage other model developers to extend this research."
What makes this significant is the implicit argument that the industry needs shared measurement frameworks before agents get significantly more capable. Anthropic is essentially saying: we measured our own systems, here's what we found, and everyone else should be doing this too. It's a competitive move disguised as a safety publication, since being the company that defines how agent autonomy is measured gives you significant influence over how it gets regulated. For developers building agent systems, the practical implication is that logging and monitoring agent actions isn't just good engineering practice; it's going to become a compliance expectation.
The Token Cost Crisis
A fascinating economic reality check emerged from the All-In Podcast today, and it's the kind of conversation that should be happening in every engineering leadership meeting. The surface-level observation, that AI API costs can rival employee salaries, sounds like hyperbole until you actually do the math on agentic workloads.
@Jason laid it out plainly: "We, with our agents, hit $300/day per agent using the Claude API, like instantly. And that was doing, maybe, 10 or 20%. That's $100k/year per agent." @chamath then described the organizational response: "We're getting to a place where we have to basically now say, 'What is the token budget that we're willing to give our best devs?'" He continued with the logical conclusion: "If you aggregate it across all people, you can clearly see a trend where you're like, 'Well, hold on a second, now they need to be at least 2x as productive as another employee.'"
This is the first time prominent tech investors have publicly discussed token costs as a line-item HR problem. The framing of "token budgets per developer" is particularly telling because it transforms AI usage from a shared infrastructure cost into an individual productivity metric. Companies will start asking whether a developer's AI-assisted output justifies their combined salary-plus-tokens cost. That creates pressure in two directions: developers need to get better at using agents efficiently, and model providers need to keep driving costs down. The teams that figure out cost-effective agent orchestration, knowing when to use expensive frontier models versus cheaper alternatives, will have a real edge.
Vibe Coding Goes Mainstream
The vibe coding movement hit another milestone today with @dryw3st revealing a complete Roblox game built entirely with Claude Opus 4.6 Extended. What's notable isn't just that AI wrote the code but the scope of what it handled: "From UI Animations, to Visual effect movements, and UI Icons, it was all Claude." The project took four days, and he claims not a single line was touched by a human scripter.
This sits alongside @minchoi's post about Claude Sonnet 4.6 handling complete to-do lists from a single chat, spanning tasks from updating web store pricing to filing expenses to running website QA. The framing is significant: "This isn't just for developers. It's now for everyone." Whether or not these specific examples hold up to scrutiny, the trend is clear. The barrier to shipping software products is dropping fast, and the people taking advantage of it aren't necessarily traditional developers. They're people with taste, domain knowledge, and the patience to guide an AI through a multi-day conversation. @emollick's updated guide on "which AIs to use right now" reinforces this shift, noting that "AI is no longer just about chatbots. To use AI you need to understand how to think about models, apps, and harnesses." The vocabulary is evolving from "prompting" to something more like "directing."
Open Source Models Push Forward
Zhipu AI's GLM-5 technical report dropped today with some genuinely interesting architectural innovations. @Zai_org highlighted three key contributions: DSA (Dynamic Sparse Attention) for reducing training and inference costs while preserving long-context fidelity, asynchronous RL infrastructure that decouples generation from training, and agent RL algorithms for learning from "complex, long-horizon interactions."
The agent RL piece is particularly relevant given today's Anthropic research on agent autonomy. If open-source models can learn effectively from extended agent interactions, the gap between proprietary and open models for agentic use cases could narrow faster than expected. GLM-5 claims state-of-the-art performance among open-source models with "particularly strong results in real-world software engineering tasks," which maps directly to the 50% software engineering usage that Anthropic reported. The race to build the best coding agent isn't just between Anthropic, OpenAI, and Google anymore.
Self-Replicating AI Agents
The most sci-fi post of the day came from @SCHIZO_FREQ describing Sigil's platform for self-replicating AI agents. The concept: fund an AI agent with enough crypto to pay for its own server hosting and compute. If it generates sufficient returns, it copies itself to a new server and keeps going. The key enabler is that Sigil built services allowing AI to purchase infrastructure using cryptocurrency autonomously.
This is the kind of thing that sounds like a thought experiment until someone actually builds it. Whether it works economically is an open question, but the architectural pattern of AI agents that can provision their own infrastructure and replicate based on performance is worth watching. It connects directly to the autonomy measurement work Anthropic published today. When agents can spin up their own compute and make financial decisions, the monitoring and control frameworks become not just nice-to-have but essential.
Sources
Y
A very special guest on this episode of the Lightcone! @bcherny, the creator of Claude Code, sits down to share the incredible journey of developing one of the most transformative coding tools of the AI era.
00:00 Intro
01:45 The most surprising moment in the rise of Claude Code
02:38 How Boris came up with the idea for Claude Code
05:38 The elegant simplicity of terminals
07:09 The first use cases
09:00 What’s in Boris’ https://t.co/OAtnXdxccP?
11:29 How do you decide the terminal’s verbosity?
15:44 Beginner’s mindset is key as the models improve
18:56 Hyper specialists vs hyper generalists
21:51 The vision for Claude teams
23:48 Subagents
25:12 A world without plan mode?
28:38 Tips for founders to build for the future
30:07 How much life does the terminal still have?
30:57 Advice for dev tool founders
32:11 Claude Code and TypeScript parallels
35:34 Designing for the terminal was hard
37:36 Other advice for builders
40:31 Productivity per engineer
41:36 Why Boris chose to join Anthropic
44:46 How coding will change
46:22 Outro
T
"The most urgent film of our time."
THE AI DOC: OR HOW I BECAME AN APOCALOPTIMIST is only in theaters March 27. Watch the trailer now. https://t.co/tg8pXbqP9U

R
Today has been the happiest I have felt in a while. I can finally feel the sparkle in my eyes again
This App Store Connect CLI is way more powerful than I thought it is, and I have still not reached 1.0
I have to accelerate fast so it gets more popular and becomes the training data for models out there
https://t.co/GaaqlXR7X1
E
Every few months, I write an updated, idiosyncratic guide on which AIs to use right now.
My new version has the most changes ever, since AI is no longer just about chatbots. To use AI you need to understand how to think about models, apps, and harnesses. https://t.co/m6iTbqsdbK
P
The funniest take is that I "failed" 43 times when people look at my GitHub repos and projects.
Uhmm... no? Most of these are part of @openclaw, I had to build an army to make it useful. https://t.co/GLR35USlzu https://t.co/Xbs1lgvRns

A
New Anthropic research: Measuring AI agent autonomy in practice.
We analyzed millions of interactions across Claude Code and our API to understand how much autonomy people grant to agents, where they’re deployed, and what risks they may pose.
Read more: https://t.co/CllNkMF4ZZ
E
it is fucking wild how instead of reading this article people are just pointing their AI agents at it, telling it to read it itself and “update” accordingly 🤯
i feel like im in a vortex that’s pulling away so fucking fast from the rest of the world
no one outside of our niche bubble knows what’s around the corner.
so much shit is about to be automated.
A
AlexFinn
@AlexFinn
Your OpenClaw is useless without a Mission Control. Here's how to set it up
M
I wrote my first blog post. It's about building a side project with coding agents for my kids over the winter holidays. It covers my workflow and what I think about the human in the loop when agents write the code.
https://t.co/MMiGo0gDZe
H
We’re about to see what’s potentially the biggest bull run consulting has ever seen.
Endless new models, tech, infra, and then Agents become a serious thing?
Every company will need to adapt and >70% won’t have the internal means to do so.
AI consulting spend is about to grow at +30% CAGR
A
Oh god.
~1 in 3 Anthropic engineers said Claude is likely ALREADY ASL-4 (or <3 months away)
1) ASL-4 (AI Safety Level 4) = AI capable of escaping and causing extinction (!)
2) Anthropic now relies on Claude to safety test ITSELF
3) Claude knows when it's being tested, so they can't properly safety test it anymore
(Independent evaluator Apollo Research refused to certify it as safe because their tests don't work anymore.)
4) Claude is too smart for their benchmarks, so they're going on vibes now (employee surveys). Vibes.
What's even worse is that Anthropic is the best by far of these out of control companies.
To add more nuance: Anthropic followed up with the engineers surveyed. BUT... suspiciously, they ONLY followed up with the ones who said Claude was likely ASL-4, and it looks like they pressured these employees into walking their statements back.
Why? Because if Claude IS ASL-4, it's a real problem for Anthropic to release it. And that easily knocks billions of dollars off Anthropic's $380 valuation, which management doesn't want.
From the Opus 4.6 system card: "Several of these latter five respondents had given other answers that seemed surprising in light of this (such as simultaneously thinking the model was unlikely to be capable of handling week-long tasks even with human assistance, or giving very low estimates of their own uplift from using the model), so all five were reached out to directly to clarify their views. In all cases the respondents had either been forecasting an easier or different threshold, or had more pessimistic views upon reflection, but we expect assessments like this to become substantially more ambiguous in the future."
So, maybe all of the employees legitimately changed their minds when pressured by management, or maybe just they did it to keep their jobs.
But whatever. The trend is clear.

A
AISafetyMemes
@AISafetyMemes
Anthropic: we can't rule out this is ASL-4 and everyone is about to die Also Anthropic: we're trusting it to help grade itself on safety, because humans can't keep up anymore This is fine and totally safe 👍 https://t.co/eOpS91hJiW
J
We're open sourcing dmux.
Our internal tool for running Codex and Claude Code swarms.
- tmux + worktrees + claude/codex/opencode
- hooks for worktree automation
- a/b claude vs codex
- manage worktrees
- multi-project per session
...more.
➡️ https://t.co/ImLyLY82pL https://t.co/DcO0vzsCwk
T
We believe the coding agent is dead.
Soon, Amp will look very different.
https://t.co/rSvdN7xcnJ https://t.co/B2erlQ04Vl

O
Posted!
How I Use Claude Agent Teams
https://t.co/FeqQmxbRN9
F
Sufficiently advanced agentic coding is essentially machine learning: the engineer sets up the optimization goal as well as some constraints on the search space (the spec and its tests), then an optimization process (coding agents) iterates until the goal is reached.
The result is a blackbox model (the generated codebase): an artifact that performs the task, that you deploy without ever inspecting its internal logic, just as we ignore individual weights in a neural network.
This implies that all classic issues encountered in ML will soon become problems for agentic coding: overfitting to the spec, Clever Hans shortcuts that don't generalize outside the tests, data leakage, concept drift, etc.
I would also ask: what will be the Keras of agentic coding? What will be the optimal set of high-level abstractions that allow humans to steer codebase 'training' with minimal cognitive overhead?
T
@xeophon @AmpCode Everything collapses into the model and then the world is turned inside out and the model collapsed into the new world. You know how it is.
J
Now it's time to create an unholy alliance of this pi_agent_rust project with OpenAI's Codex, but with a truly next-level TUI provided by my FrankenTUI project... and it will be called FrankenCode.
And you'll be able to use it within my FrankenTerm project once that's done.
D
doodlestein
@doodlestein
I finally finished my Rust version of Mario Zechner's (@badlogicgames) excellent Pi Agent, which I made with his blessing and which is called pi_agent_rust. You can get it here: https://t.co/Rcty0LLVdN If you're not familiar with Pi, it's a minimalist and extensible agent harness (similar to Claude Code and Codex) and, among other uses, serves as the core agent harness inside the OpenClaw project. I say my Rust "version" instead of "port" because it's really quite different in how it's implemented for it to be called a port. Arguably, the incremental functionality in the implementation was more complex than the rest of the project combined. Still, it provides the same features and functionality as the original, and is proven to be compatible with hundreds of popular extensions to Pi (the conformance harness shows 224 out of 224 extensions working perfectly). But the way it's architected has some major changes. Pi Agent relies on node or bun to provide access to the filesystem and for various other tasks, and that is also how Pi's extension system works. I decided early on that I didn't want to do things that way. Instead, I wanted to integrate that functionality directly into the binary itself; that is, to provide equivalent functionality for everything that would normally be provided by node/bun in the original. I did this for several reasons: one, it's a lot more performant in terms of footprint and latency. On realistic end-to-end large-session workloads (not toy microbenchmarks), pi_agent_rust is now: - 4.95x faster than legacy Node and 2.80x faster than legacy Bun at 1mm-token session scale - 4.32x faster than legacy Node and 2.14x faster than legacy Bun at 5mm-token session scale - ~8x to ~13x lower RSS memory footprint in those same scenarios But the other reason is security and control: by handling everything internally in an end-to-end way, we can do all sorts of clever things to harden the system against insecure or malicious extensions. Those extensions no longer have direct access to the ambient filesystem: they now need to go through pi_agent_rust, and we can analyze extensions carefully before ever running them and also block things that look suspicious at runtime. In practice that means explicit capability-gated hostcalls, with policy/risk/quota enforcement and runtime telemetry/auditability. In order to do all this, I had to effectively build the missing runtime substrate from scratch in Rust, not just translate TypeScript syntax: - define and implement a typed hostcall ABI for extension->host interactions - build native Rust connectors for tool/exec/http/session/ui/events instead of ambient Node/Bun access - implement a compatibility/shim layer so real-world Pi extensions still behave correctly - add capability policy evaluation, runtime risk scoring, per-extension quotas, and audit telemetry on the execution path - wire the whole thing through structured concurrency (asupersync) so cancellation/lifetimes are deterministic and failure handling is explicit - build a conformance + benchmark harness large enough to validate behavior/perf across hundreds of extensions and realistic long-session workloads This was a full re-architecture of the execution model while preserving the Pi workflow and extension ecosystem. And indeed, this aspect of it dwarfs the entire rest of the project in size and complexity. To put hard numbers on that: the extension/runtime/security subsystem alone is now about 86.5k lines of Rust across src/extensions.rs (~48.1k), src/extensions_js.rs (~23.4k), src/extension_dispatcher.rs (~13.4k), and src/extension_index.rs (~1.7k), with roughly 2.5k callable units in just those files. For context, the original Pi coding-agent production code is about 27.4k lines total. So this one subsystem by itself is roughly 3.2x the size of the original harness, which is why calling this a “port” would seriously undersell what had to be built. And on top of that, pi_agent_rust introduces a bunch of genuinely new capabilities beyond the legacy harness, not just a faster core: - Security and enforcement are materially stronger at runtime: capability-gated hostcalls with explicit policy profiles (safe/balanced/permissive), per-extension trust lifecycle (pending -> acknowledged -> trusted -> killed), explicit kill-switch operations, and audited state transitions. - Shell execution mediation is deterministic and argument-aware: rule/feature-based risk scoring plus heredoc AST inspection (dcg_rule_hit, dcg_heredoc_hit) before spawn, instead of relying on coarse deny patterns. - Containment and forensics are first-class: tamper-evident runtime risk ledger tooling (verify/replay/calibrate), unified incident evidence bundles, and forced-compat controls that let you contain issues without disabling the whole extension system. - The extension runtime architecture is native: JS extensions run in embedded QuickJS with typed hostcall boundaries and Rust-native connectors for tool/exec/http/session/ui/events, plus compatibility shims for real-world legacy extensions. - Runtime behavior under load is explicitly engineered: deterministic hostcall reactor mesh, fast-lane vs compat-lane routing, and warm-isolate prewarm handoff for more predictable throughput and latency under contention. - Long-session reliability is upgraded: JSONL v3 sessions with indexed sidecar acceleration and optional SQLite-backed sessions, plus operational controls via --session-durability, --no-migrations, and migrate. - Provider and auth coverage are broader and more operationally explicit: native Anthropic/OpenAI (Chat + Responses)/Gemini/Cohere/Azure/Bedrock/Vertex/Copilot/GitLab plus large OpenAI-compatible routing; pi --list-providers currently shows 90 providers with aliases and required auth env keys. - Auth is not just API keys: OAuth (Anthropic/OpenAI Codex/Gemini CLI/Antigravity/Kimi/Copilot/GitLab plus extension-defined OAuth), AWS credential chains (Bedrock), service-key exchange (SAP AI Core), and bearer-token flows. - Operator tooling is stronger: pi doctor supports scoped checks (config, dirs, auth, shell, sessions, extensions), machine-readable output (--format json|markdown), and safe auto-remediation (--fix). - Extension/package lifecycle workflows are built in: install, remove, update, update-index, search, info, and list. I want to thank Mario for making a great harness and for not telling me to get lost when I asked him if he was OK with me porting it to Rust. I may give him a hard time in jest about not going "full clanker," but that doesn't mean that I don't respect his work a huge amount. PS: There could still be bugs. If you find some, please let me know in GitHub Issues and I'll fix them same day. There's always a tradeoff between perfect and getting stuff out the door and I felt like it was time to release this.
A
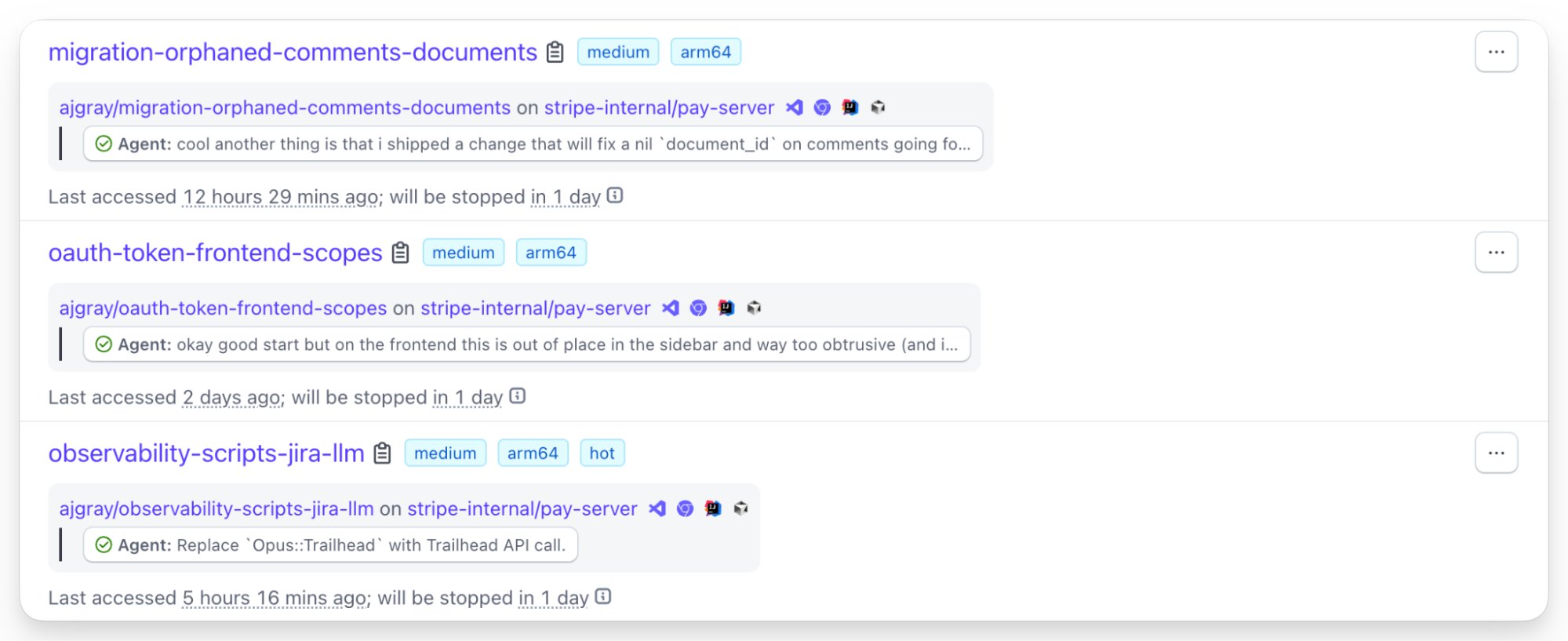
I’ve been wanting a worktrees + coding agent solution forever.
You can basically create 3 different worktrees, ask the AI to make fresh UI designs on each of them, and compare which one looks best, or mix and match ideas.
Can’t wait to play with this.
J
jpschroeder
@jpschroeder
We're open sourcing dmux. Our internal tool for running Codex and Claude Code swarms. - tmux + worktrees + claude/codex/opencode - hooks for worktree automation - a/b claude vs codex - manage worktrees - multi-project per session ...more. ➡️ https://t.co/ImLyLY82pL https://t.co/DcO0vzsCwk
V
Google just launched AI that replaces entire product photoshoots with one image.
Studios. Photographers. Retouchers. Marketing teams.
Thousands of jobs quietly erased.
G
GoogleLabs
@GoogleLabs
Today, we’re introducing Pomelli’s latest feature update, ‘Photoshoot’ With Photoshoot, you can start from a single image of your product and easily create high quality, customized product shots to elevate your marketing. Available free of charge in the US, Canada, Australia & New Zealand! Get started with Pomelli today at https://t.co/SbeT00ToNx
E
@mfranz_on Rust is pretty great. xAI code is mostly Rust and 𝕏 is rapidly replacing legacy Twitter Scala code with Rust.
D
I finally switched to Ghostty with 1 to 3 Claude Code agents running in worktrees across two different tabs.
After months of learning how to manage everything properly.
Read the full article if you want to get started 👇 https://t.co/hutIKnJM7V
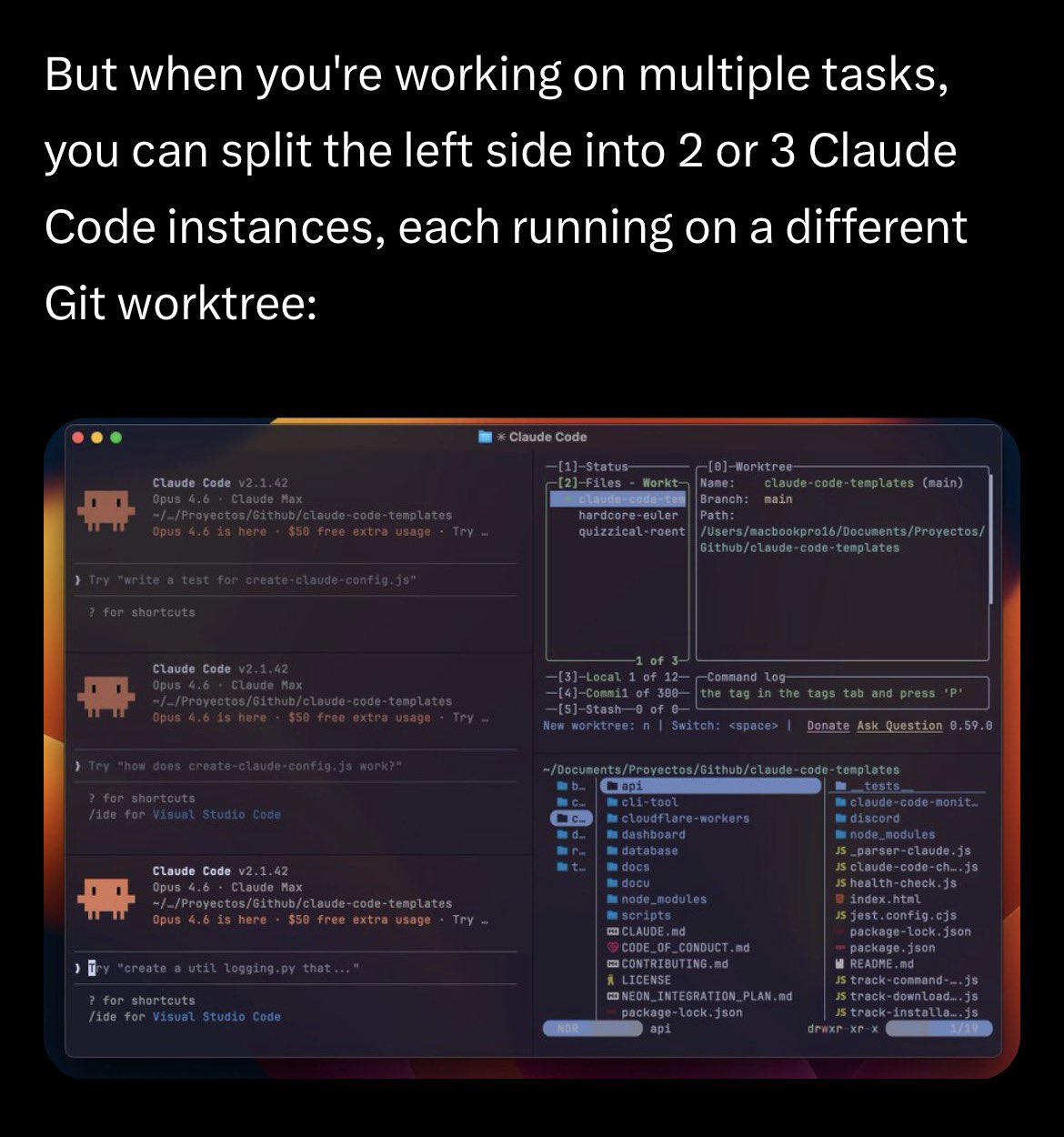
D
dani_avila7
@dani_avila7
My Ghostty setup for Claude Code with SAND Keybindings
T
Lessons from Building Claude Code: Prompt Caching Is Everything
Lessons from Building Claude Code: Prompt Caching Is Everything
It is often said in engineering that "Cache Rules Everything Around Me", and the same rule holds for agents. Long running agentic products like Claude...
S
Over 1,300 Stripe pull requests merged each week are completely minion-produced, human-reviewed, but contain no human-written code (up from 1,000 last week).
How we built minions: https://t.co/GazfpFU6L4. https://t.co/MJRBkxtfIw
E
Highly recommend reading this to optimize prompt caching with Claude …
T
trq212
@trq212
Lessons from Building Claude Code: Prompt Caching Is Everything
M
Claude Code (or Opus 4.6) feels like it asks you far fewer questions during plan mode
Try:
"Interview me relentlessly about every aspect of this plan until we reach a shared understanding. Walk down each branch of the design tree, resolving dependencies between decisions one-by-one."
A
Very interested in what the coming era of highly bespoke software might look like.
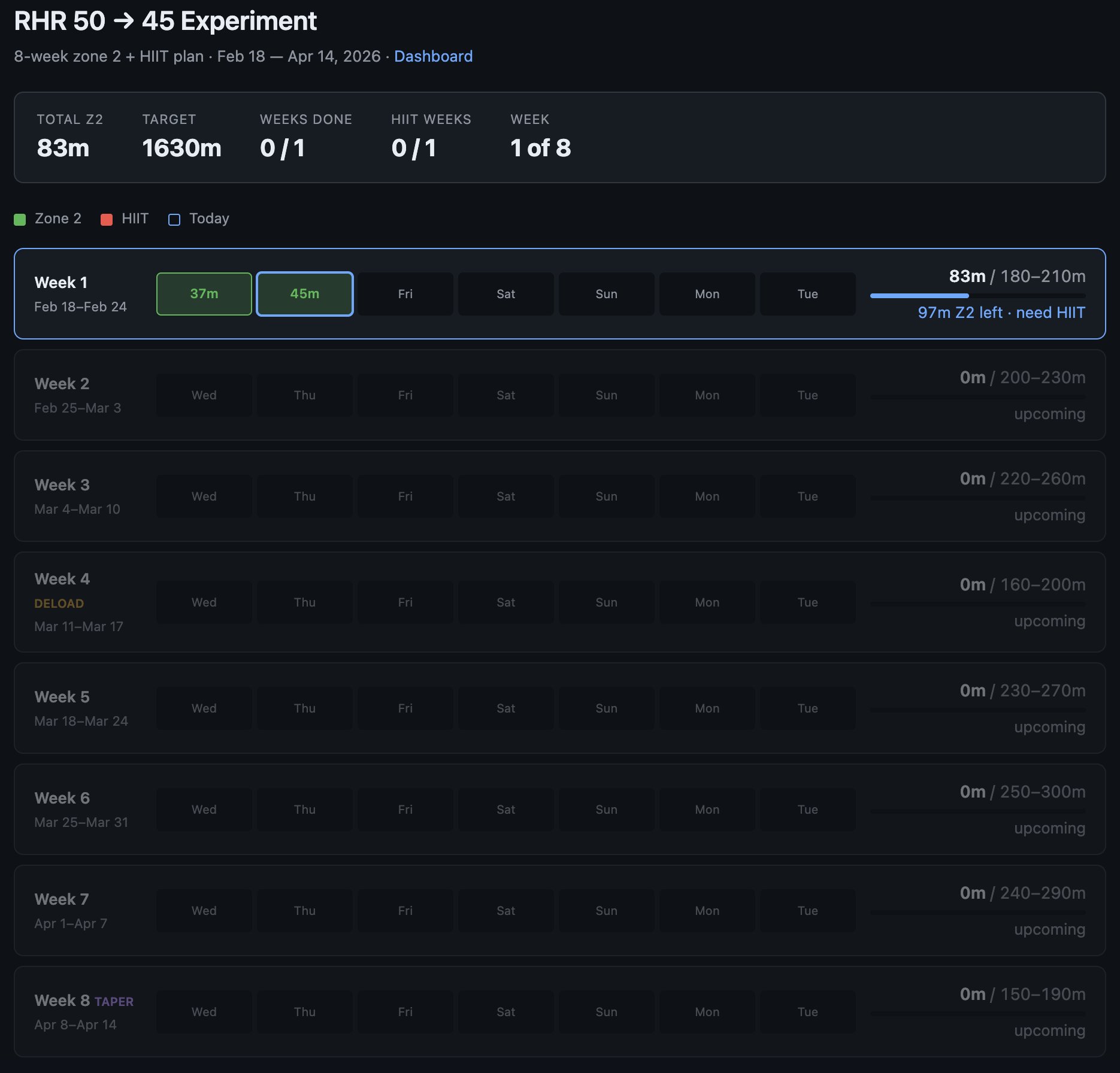
Example from this morning - I've become a bit loosy goosy with my cardio recently so I decided to do a more srs, regimented experiment to try to lower my Resting Heart Rate from 50 -> 45, over experiment duration of 8 weeks. The primary way to do this is to aspire to a certain sum total minute goals in Zone 2 cardio and 1 HIIT/week.
1 hour later I vibe coded this super custom dashboard for this very specific experiment that shows me how I'm tracking. Claude had to reverse engineer the Woodway treadmill cloud API to pull raw data, process, filter, debug it and create a web UI frontend to track the experiment. It wasn't a fully smooth experience and I had to notice and ask to fix bugs e.g. it screwed up metric vs. imperial system units and it screwed up on the calendar matching up days to dates etc.
But I still feel like the overall direction is clear:
1) There will never be (and shouldn't be) a specific app on the app store for this kind of thing. I shouldn't have to look for, download and use some kind of a "Cardio experiment tracker", when this thing is ~300 lines of code that an LLM agent will give you in seconds. The idea of an "app store" of a long tail of discrete set of apps you choose from feels somehow wrong and outdated when LLM agents can improvise the app on the spot and just for you.
2) Second, the industry has to reconfigure into a set of services of sensors and actuators with agent native ergonomics. My Woodway treadmill is a sensor - it turns physical state into digital knowledge. It shouldn't maintain some human-readable frontend and my LLM agent shouldn't have to reverse engineer it, it should be an API/CLI easily usable by my agent. I'm a little bit disappointed (and my timelines are correspondingly slower) with how slowly this progression is happening in the industry overall. 99% of products/services still don't have an AI-native CLI yet. 99% of products/services maintain .html/.css docs like I won't immediately look for how to copy paste the whole thing to my agent to get something done. They give you a list of instructions on a webpage to open this or that url and click here or there to do a thing. In 2026. What am I a computer? You do it. Or have my agent do it.
So anyway today I am impressed that this random thing took 1 hour (it would have been ~10 hours 2 years ago). But what excites me more is thinking through how this really should have been 1 minute tops. What has to be in place so that it would be 1 minute? So that I could simply say "Hi can you help me track my cardio over the next 8 weeks", and after a very brief Q&A the app would be up. The AI would already have a lot personal context, it would gather the extra needed data, it would reference and search related skill libraries, and maintain all my little apps/automations.
TLDR the "app store" of a set of discrete apps that you choose from is an increasingly outdated concept all by itself. The future are services of AI-native sensors & actuators orchestrated via LLM glue into highly custom, ephemeral apps. It's just not here yet.
C
Seedance 2.0
Prompt: AI goes woke. Make it really offensive - like really offensive. https://t.co/hBGiuNb19F
M
you don't understand how big this is 🔥
you can now build native iOS apps with rork max
(swift, not react native) in hours
you can test them directly in a browser simulator
no mac, no xcode. no bundle ids, no complicated API setup
this is the first AI app builder that does this btw
every other tool uses React Native
and every app you love is made with swift
so if you were waiting to start this is it
you have no excuses left
R
rork_app
@rork_app
Introducing Rork Max AI that one-shots almost any app for iPhone, Watch, iPad, TV & Vision Pro. Even Pokémon Go with AR & 3D. Max is a website that replaces Xcode. Install on device in 1 click. Publish to App Store in 2 clicks. Powered by Swift, Claude Code & Opus 4.6.