WebMCP Lands in Chrome 146 as Stripe and Ramp Reveal Internal Coding Agent Architectures
The enterprise agent buildout accelerated as Stripe revealed its internal "minions" framework and OpenAI shipped new primitives for long-running agentic work. Chrome's WebMCP announcement sparked debate about browsers becoming agent-native interfaces, while the Claude Code vs Codex rivalry intensified with Cowork landing on Windows and reports of engineers switching sides.
Daily Wrap-Up
The dominant storyline today is the emergence of enterprise-grade agent infrastructure. Stripe and Ramp are now publicly sharing details of their internal agent systems, OpenAI is shipping API primitives specifically designed for multi-hour autonomous runs, and Claude Code added multi-agent team support. This isn't the "AI writes a function" era anymore. We've crossed into "AI runs your engineering org's background processes" territory, and the companies building these systems internally are starting to talk about it publicly, which means the gap between them and everyone else is about to become painfully visible.
Chrome's WebMCP announcement deserves attention beyond the initial hype. The idea that browsers will expose structured interfaces for AI agents to interact with web applications, not through screen scraping but through a proper protocol, changes the calculus for every web developer. If your app doesn't have an agent-friendly interface, it's going to feel like a site without mobile support in 2015. Meanwhile, the Harvard Business Review study showing that AI actually made workers busier, not more efficient, is the kind of research that should temper the breathless predictions but probably won't. The finding that AI blurred role boundaries and increased coordination overhead is something every engineering manager should internalize before announcing their "AI transformation" initiative.
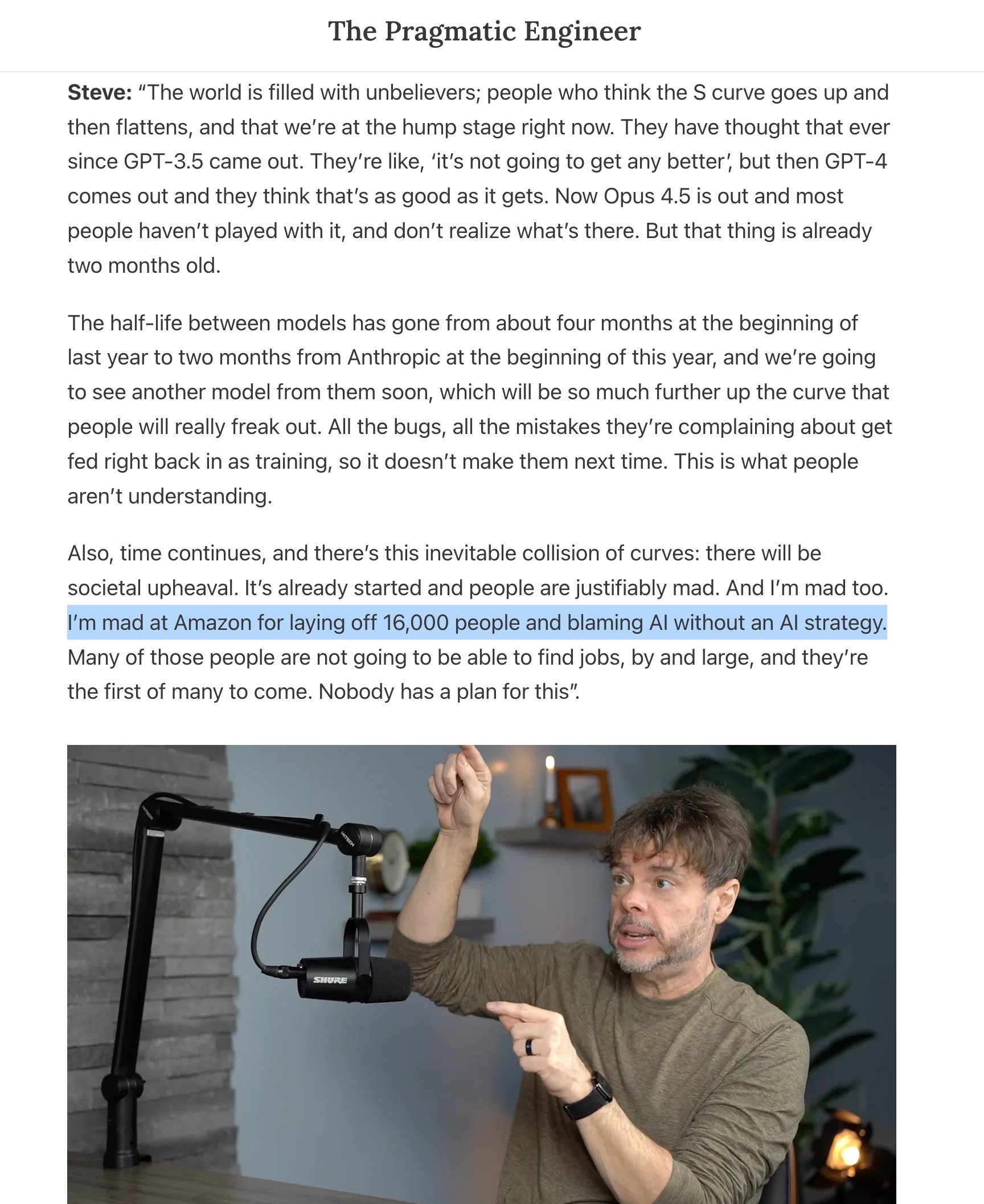
The most entertaining moment was @TMTLongShort's vivid image of CEOs "performatively leaning into Claude Coding on weekends" to impress their boards despite not having written code in a decade. It captures something real about the current moment: the gap between AI theater and actual AI integration is enormous, and it's widening. The most practical takeaway for developers: if you're building web applications, start thinking about how your app surfaces structured data and actions for agents, because WebMCP and similar protocols are going to make "agent accessibility" as important as mobile responsiveness.
Quick Hits
- @wintonARK makes the case that space-based datacenter buildout has inverse cost scaling compared to Earth, where the 100th GW gets cheaper rather than more expensive.
- @KaiLentit quips that "in 2026, AI models expire faster than session cache." Hard to argue.
- @JaredSleeper points out that UiPath (5,096 employees) still has more people than Anthropic (4,178). Let that sink in.
- @ns123abc is hyped about Isomorphic Labs' IsoDDE drug design system, which reportedly doubles AlphaFold 3 on hard targets and found drug pockets that took 15 years to discover manually.
- @jeffclune introduces meta-learning memory designs where AI agents design their own memory mechanisms for continual learning.
- @EntireHQ announced a $60M seed round to build "the next developer platform" with an open-source first release.
- @steipete endorses Go as a go-to language, linking to an explainer on why it fits well in the current development landscape.
- @RyanCarniato observes that AI has hit the inversion point where TDD actually saves time instead of wasting it. The testing purists finally get their vindication, just not the way they imagined.
- @sammarelich dropped a new "cold email template" that appears to be a joke about AI-generated outreach.
- @every launched Every Events, a platform for AI learning across skill levels with camps, courses, and demo days.
- @TheAhmadOsman predicts a frontier open-source lab will be born in the West this year, claiming to be working on serious capital to make it happen.
Enterprise Agent Infrastructure Goes Public
The most significant trend today isn't any single product launch but rather the emerging pattern of top-tier engineering organizations revealing their internal agent architectures. @auchenberg highlighted that Stripe built a homegrown AI coding agent that spins up "minions" to work on their massive Ruby monorepo, noting this follows @tryramp publishing similar details about their own internal system. What makes this interesting is that Stripe's codebase uses Sorbet typings, which are uncommon enough that general-purpose LLMs struggle with them, forcing Stripe to build custom tooling rather than relying on off-the-shelf solutions.
@yenkel dug into the details, noting Stripe uses Slack as the main entry point, emphasizes repeatable dev environments, and has built custom tooling around their developer productivity stack, with MCP serving as "a common language for all agents at Stripe, not just minions."
On the API side, OpenAI pushed this further with new Responses API primitives designed explicitly for long-running agentic work. @OpenAIDevs announced server-side compaction for multi-hour agent runs, containers with networking for controlled internet access, and native support for the Agent Skills standard. This is infrastructure for agents that run for hours, not seconds. @IndraVahan connected the dots to CodeRabbit's new Issue Planner, arguing that AI is moving upstream from code writing to code review to now planning and scoping: "AI is no longer helping you just write code anymore but it's starting at planning, scope, intent and context."
The multi-agent coordination angle is also heating up. @Saboo_Shubham_ noted Claude Code's Agent UI now supports agent teams, and @pusongqi showed you can assign different agents under the same thread, "just like Slack channels, except it's occupied with agents." @levie framed the stakes clearly:
> "You could take the exact same engineer and easily see a 5X+ difference in the amount of useful output simply based on their choice of tools and how they've designed their workflows."
@teortaxesTex called it "a phase change in the perception of coding agents," noting this looked like science fiction just months ago. @ccccjjjjeeee offered a concrete technique for making agent-driven rewrites reliable: property-based testing, where you write a bridge between old and new code and assert that both produce identical output for arbitrary input, then let the agent iterate until it's consistently true. @kirbyman01 added that smaller models recursively calling themselves can now outperform larger models on hard tasks at lower cost, suggesting the winners will have "taste in system design" plus "technical depth to appreciate new inference paradigms."
Chrome WebMCP Rewires the Browser
Chrome's WebMCP announcement dominated a cluster of posts about the future of browsers as agent interfaces. @liadyosef called it bigger than it seems: "AI agents can now interact directly with existing websites and webapps, not by using the 'human' app interface." This isn't screen scraping or DOM manipulation. It's a protocol layer that lets agents interact with web applications through structured interfaces.
@joemccann didn't mince words: "If browsers are no longer designed exclusively for humans, but also agents, it will completely change web development." @barckcode expanded the implications beyond convenience, noting that client-side vulnerability discovery would also get easier, and that "engineering for building sites is going to be more important than ever." @firt clarified the technical detail that this runs in the frontend and is consumed by agentic browsers, distinguishing it from server-side MCP implementations.
The WebMCP development connects directly to the agent infrastructure story. If agents are going to operate autonomously for hours at a time, they need structured ways to interact with the web that don't depend on brittle selectors or visual parsing. WebMCP could become that foundation.
Claude Code vs Codex: The IDE Cold War
The rivalry between Anthropic and OpenAI's developer tools intensified from multiple angles. @claudeai announced Cowork is now available on Windows with full feature parity, including file access, multi-step task execution, plugins, and MCP connectors. @itsPaulAi put it bluntly: "Anthropic has just released a real Copilot before Microsoft." @trq212 teased a "big week for Claude Code desktop enjoyers."
But the competitive picture is complicated. @craigzLiszt claimed "nearly all of the best engineers I know are switching from Claude to Codex," and @lennysan quoted an essay about GPT-5.3 Codex that struck a nerve:
> "It wasn't just executing my instructions. It was making intelligent decisions. It had something that felt, for the first time, like judgment. Like taste."
@pamelafox highlighted GitHub Copilot's new memory system, with a detailed engineering blog post about implementation and evaluation. Meanwhile, @sdrzn reported that the head of Anthropic's safeguards research "just quit and said 'the world is in peril'" and is "moving to the UK to write poetry," with other safety researchers and senior staff departing over the past two weeks. Whether this is meaningful signal about internal disagreements or just normal attrition is hard to say, but the timing alongside Anthropic's aggressive product push is notable.
AI's Real Impact on Work
A Harvard Business Review study landed today with findings that cut against the dominant narrative. @rohanpaul_ai summarized the 8-month field study at a 200-person tech company: AI didn't shrink work, it intensified it. Task expansion happened because AI filled knowledge gaps, so people started doing work that previously belonged to other roles. That created extra coordination overhead for specialists "including fixing AI-assisted drafts and coaching colleagues whose work was only partly correct."
The theoretical predictions came with real-world evidence to match. @deredleritt3r reported that Baker McKenzie cut 700 jobs based on "rethinking the way we work, including through the use of AI," with cuts targeting IT, admin, marketing, and design rather than lawyers. @TMTLongShort predicted a broader "bloodbath" as CFOs use AI tools to map productivity and redundancy of every employee, driving "seat-count collapse" narratives.
@atelicinvest offered the more nuanced take that performance differentials between organizations will widen massively, with the top 10% achieving "unbelievably better" product velocity and quality versus the bottom 25%, leading to market share shifts "probably in a bigger way than we imagine." @aakashgupta noted that AI-first companies now want PMs who can write evals, prototype with code, and ship directly, warning that PMs who can't do the technical work "will get replaced by an agent with a Jira login."
Developer Tools Go Agent-Native
Obsidian's CLI launch was the standout tool announcement, with three separate posts highlighting its significance. @obsdmd announced that "anything you can do in Obsidian you can do from the command line" in version 1.12. @kepano laid out the implication: "install Obsidian 1.12, enable CLI, now OpenClaw, OpenCode, Claude Code, Codex, or any other agent can use Obsidian." @NickADobos praised the strategic foresight, calling Obsidian's "file > app" philosophy "a genius call years ago" that now positions it perfectly for agent integration.
Elsewhere, @excalidraw announced an official MCP connector for Claude, making diagramming available to agents. @almonk launched Echo, an iOS SSH client running Ghostty under the hood that turns iPads into "the ultimate vibe coding computer" for managing agents on the go. And @bnj unveiled Style Dropper in Variant, a tool that "absorbs the vibe of anything you point it at" and applies it to designs, inspired by the creative chaos of Kid Pix and MS Paint.
The Existential Undercurrent
Beneath the product launches and infrastructure updates, a more philosophical conversation is building. @mattshumer_ published an essay with the framing: "Every time someone asks me what's going on with AI, I give them the safe answer. Because the real one sounds insane." @thegarrettscott responded with a sobering extension, arguing that AI is now "smart enough to be a self-sustaining entity" that can take money, operate in the real world, and generate returns without human involvement.
@GergelyOrosz endorsed Steve Yegge's track record of accurate predictions, noting Yegge called the end of hand-written code in mid-2025 and the rise of agent orchestration in late 2025. @GenAI_is_real described watching an agent "use Kelly criterion to pay its own API bill" while scraping data to exploit Polymarket mispricing, calling it "the most 2026 thing I've seen." Whether this represents genuine economic disruption or another cycle of tech optimism remains the open question, but the conviction level among builders has clearly shifted.
Sources

It actually worked! For the past couple of days I’ve been throwing 5.3-codex at the C codebase for SimCity (1989) to port it to TypeScript. Not reading any code, very little steering. Today I have SimCity running in the browser. I can’t believe this new world we live in. https://t.co/Pna2ilIjdh
Today we share a technical report demonstrating how our drug design engine achieves a step-change in accuracy for predicting biomolecular structures, more than doubling the performance of AlphaFold 3 on key benchmarks and unlocking rational drug design even for examples it has never seen before. Head to the comments to read our blog.
We are moving quickly. Thanks to Anton and the folks at @excalidraw , this is now the official Excalidraw MCP server. From weekend project to official server in less than a week.

MCP Servers Are Coming to the Web. MCP lets AI agents call tools on backends. WebMCP brings the same idea to the frontend, letting developers expose their website's functionality as structured tools using plain JavaScript (or even HTML), no separate server needed. Instead of agents clicking through your UI, they call well-defined tools you control. A W3C proposal from Microsoft and Google, and Chrome 146 already ships an early preview behind a flag. ## How will it work? WebMCP introduces a `navigator.modelContext` API with two approaches: - Imperative API: Register tools directly in JavaScript with schemas and callbacks: ```js navigator.modelContext.registerTool({ name: "add-to-cart", description: "Add a product to the shopping cart", inputSchema: { type: "object", properties: { productId: { type: "string", description: "The product ID" }, quantity: { type: "number", description: "Number of items" } }, required: ["productId"] }, execute({ productId, quantity }) { addToCart(productId, quantity); return { content: [{ type: "text", text: "Item added!" }] }; } }); ``` - Declarative API: Let developers define tools directly in HTML using form attributes, no JavaScript required: ```html <form action="/todos" method="post" tool-name="add-todo" tool-description="Add a new todo item to the list"> <input type="text" name="description" required tool-prop-description="The text of the todo item"> <button type="submit">Add Todo</button> </form> ``` This declarative approach is still under active discussion, with the goal of making WebMCP accessible to content creators without JS experience.
Today, I finally feel the existential threat that AI is posing. When AI becomes overly good and disrupts everything, what will be left for humans to do? And it's when, not if.


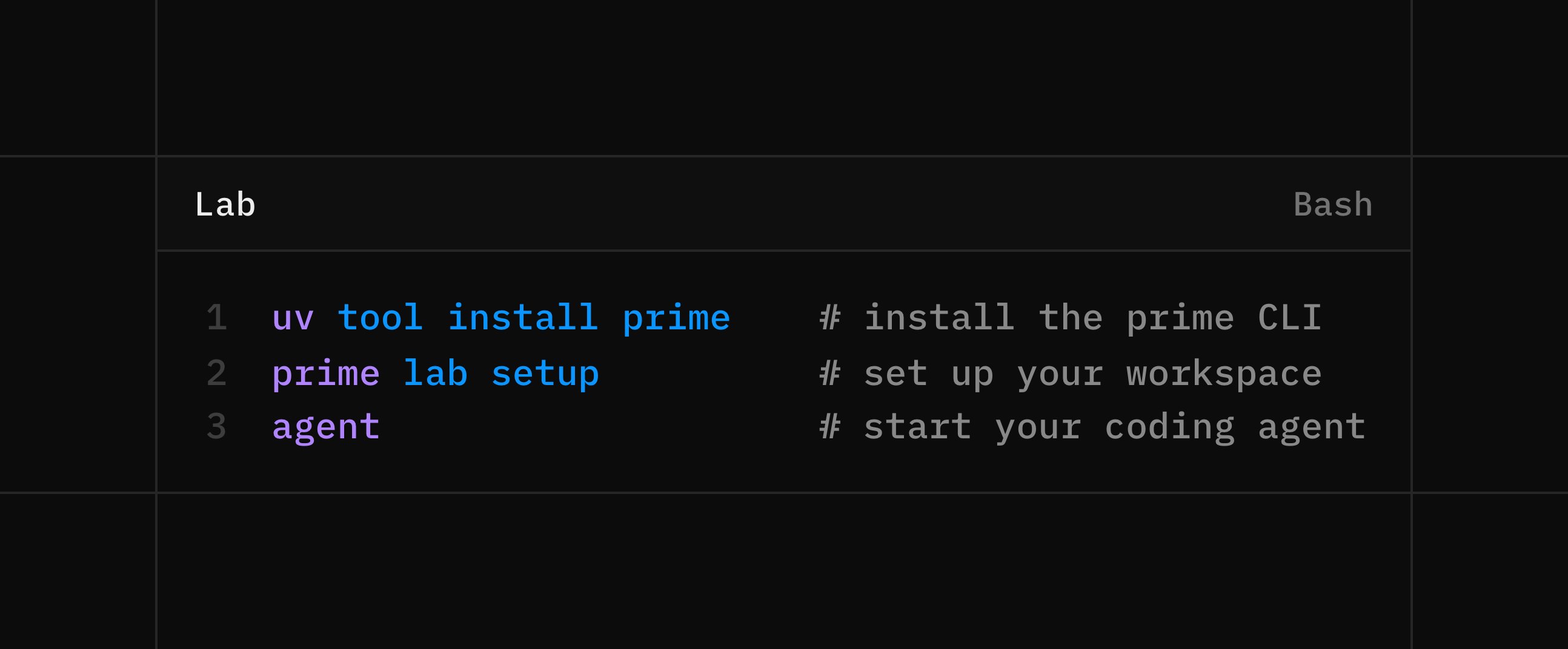
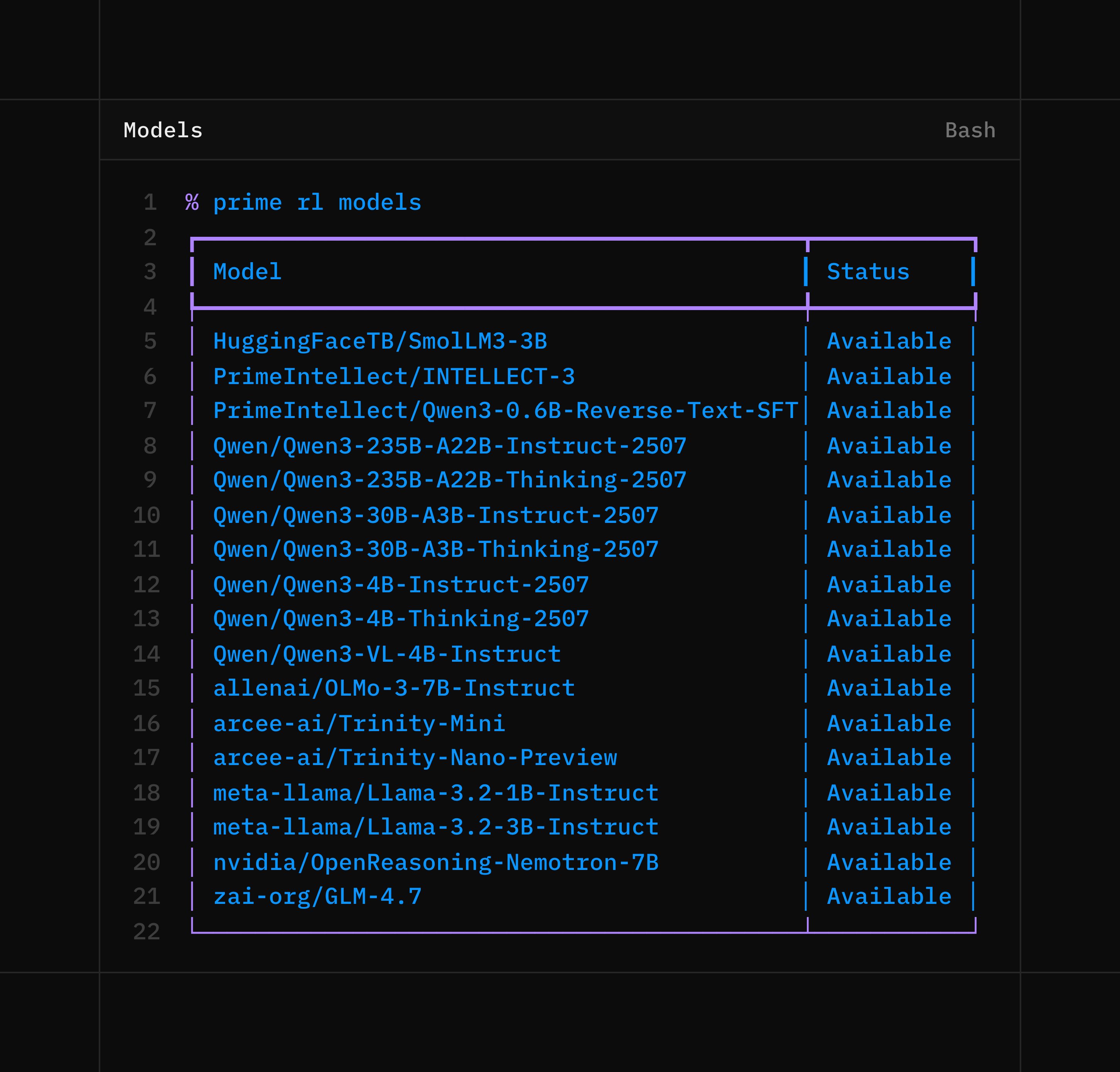
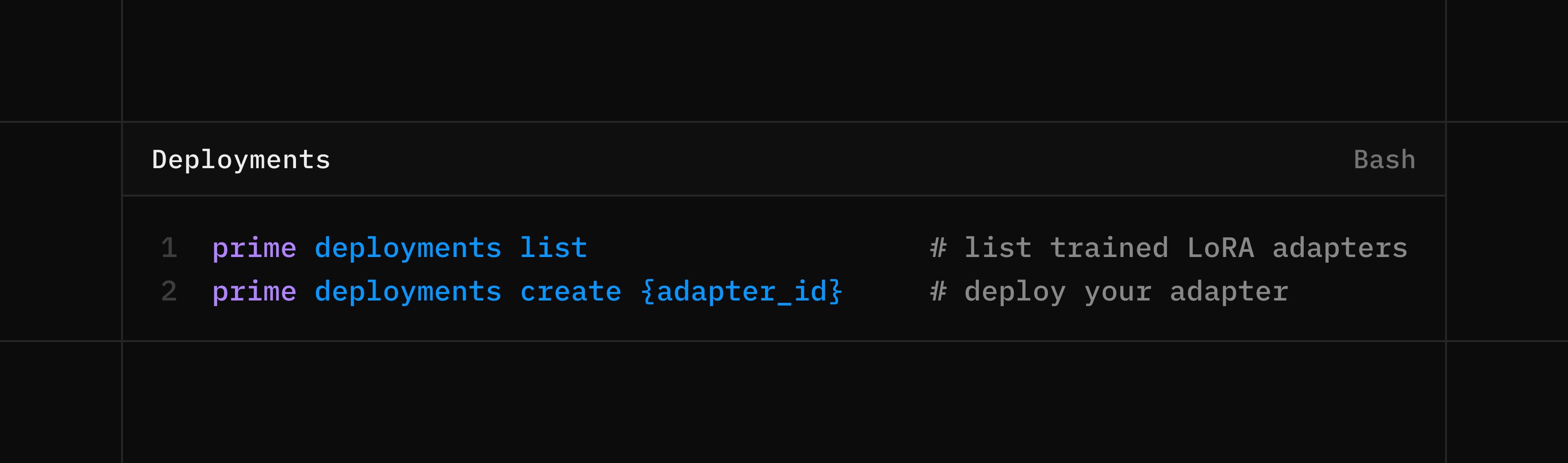

Something Big Is Happening
We are not inspired by a future where a few labs control the intelligence layer So we built a platform to give everyone access to the tools of the frontier lab If you are an AI company, you can now be your own AI lab If you are an AI engineer, you can now be an AI researcher
Introducing Expressive Mode for ElevenAgents - voice agents so expressive, they blur the line between AI and human conversations. This is an unedited recording of an agent empathizing with a customer at peak frustration. https://t.co/QT6abvmbir
It’s going to be a long night. Pony is so back. https://t.co/vAuXp9ECJF

Introducing GLM-5: From Vibe Coding to Agentic Engineering GLM-5 is built for complex systems engineering and long-horizon agentic tasks. Compared to GLM-4.5, it scales from 355B params (32B active) to 744B (40B active), with pre-training data growing from 23T to 28.5T tokens. Try it now: https://t.co/WCqWT0raFJ Weights: https://t.co/DteNDHjSEh Tech Blog: https://t.co/Wxn5ARTJxH OpenRouter (Previously Pony Alpha): https://t.co/7Khf64Lxg6 Rolling out from Coding Plan Max users: https://t.co/Nk8Y98Il7s
On DeepWiki and increasing malleability of software. This starts as partially a post on appreciation to DeepWiki, which I routinely find very useful and I think more people would find useful to know about. I went through a few iterations of use: Their first feature was that it auto-builds wiki pages for github repos (e.g. nanochat here) with quick Q&A: https://t.co/DQHXagUwK0 Just swap "github" to "deepwiki" in the URL for any repo and you can instantly Q&A against it. For example, yesterday I was curious about "how does torchao implement fp8 training?". I find that in *many* cases, library docs can be spotty and outdated and bad, but directly asking questions to the code via DeepWiki works very well. The code is the source of truth and LLMs are increasingly able to understand it. But then I realized that in many cases it's even a lot more powerful not being the direct (human) consumer of this information/functionality, but giving your agent access to DeepWiki via MCP. So e.g. yesterday I faced some annoyances with using torchao library for fp8 training and I had the suspicion that the whole thing really shouldn't be that complicated (wait shouldn't this be a Function like Linear except with a few extra casts and 3 calls to torch._scaled_mm?) so I tried: "Use DeepWiki MCP and Github CLI to look at how torchao implements fp8 training. Is it possible to 'rip out' the functionality? Implement nanochat/fp8.py that has identical API but is fully self-contained" Claude went off for 5 minutes and came back with 150 lines of clean code that worked out of the box, with tests proving equivalent results, which allowed me to delete torchao as repo dependency, and for some reason I still don't fully understand (I think it has to do with internals of torch compile) - this simple version runs 3% faster. The agent also found a lot of tiny implementation details that actually do matter, that I may have naively missed otherwise and that would have been very hard for maintainers to keep docs about. Tricks around numerics, dtypes, autocast, meta device, torch compile interactions so I learned a lot from the process too. So this is now the default fp8 training implementation for nanochat https://t.co/3i5cv6grWm Anyway TLDR I find this combo of DeepWiki MCP + GitHub CLI is quite powerful to "rip out" any specific functionality from any github repo and target it for the very specific use case that you have in mind, and it actually kind of works now in some cases. Maybe you don't download, configure and take dependency on a giant monolithic library, maybe you point your agent at it and rip out the exact part you need. Maybe this informs how we write software more generally to actively encourage this workflow - e.g. building more "bacterial code", code that is less tangled, more self-contained, more dependency-free, more stateless, much easier to rip out from the repo (https://t.co/iKJUoHiIpl) There's obvious downsides and risks to this, but it is fundamentally a new option that was not possible or economical before (it would have cost too much time) but now with agents, it is. Software might become a lot more fluid and malleable. "Libraries are over, LLMs are the new compiler" :). And does your project really need its 100MB of dependencies?
📣 Shipping software with Codex without touching code. Here’s how a small team steering Codex opened and merged 1,500 pull requests to deliver a product used by hundreds of internal users with zero manual coding. https://t.co/2GaeX7We2n
It’s going to be a very weird year
New art project. Train and inference GPT in 243 lines of pure, dependency-free Python. This is the *full* algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further. https://t.co/HmiRrQugnP
Tool Shaped Objects