Anthropic Launches $100K Hackathon as AI Industry Braces for 'Fast Takeoff' Discourse
The developer community is converging on multi-agent orchestration and persistent context management as the next critical infrastructure layer, with OneContext earning its creator a Google interview and one developer solving context compaction with a creative mix of cron jobs and vector search. Meanwhile, Seedance 2.0 demos out of China have the film industry reassessing its future, and the AI acceleration discourse continues to intensify.
Daily Wrap-Up
The throughline today is infrastructure for persistence. Whether it's agent memory, context windows, or orchestration layers, the people actually building with AI are converging on the same problem: how do you keep these systems coherent across sessions, tasks, and teams? @JundeMorsenWu got cold-emailed by Google's Gemini team after building OneContext, a persistent context layer for coding agents. @PerceptualPeak spent a grueling day solving context transfer across compaction boundaries in their Clawdbot system. @ryancarson laid out the thesis plainly: nobody wants one agent anymore, they want one agent that runs teams of agents. The tooling layer between "single prompt" and "autonomous workforce" is where the real engineering is happening right now, and it's still wide open.
On the creative side, Seedance 2.0 out of China is generating the kind of reaction that Sora got a year ago, but with capabilities that feel a generation ahead. @EHuanglu described features that sound almost too aggressive: upload screenshots from any movie and generate new scenes that match the original's look, or upload clips and swap characters, add VFX, change backgrounds on the fly. Chinese indie filmmakers are already producing full AI-generated movies with it. The "Will Smith eating spaghetti" benchmark that @SpecialSitsNews referenced feels quaint now. The gap between "impressive demo" and "production tool" is collapsing faster than anyone expected.
The acceleration discourse is louder than ever, with multiple voices warning that 2026 is the inflection point. But @backseats_eth offered the most grounded take of the day: ignore the AI theatre, skip the vibe coders who learned last month, and spend your time learning from experienced engineers who are updating their processes with AI. The most practical takeaway for developers: invest your learning time in persistent context management for your AI tooling. Whether it's OneContext, custom memory systems, or simple file-based approaches, the developers who solve context continuity across agent sessions will have a massive productivity edge over those still treating each AI interaction as a blank slate.
Quick Hits
- @elonmusk announced SpaceX has shifted focus to building a self-growing Moon city first, citing the 10-day launch cadence vs. Mars's 26-month alignment windows. Mars plans still on the table in 5-7 years.
- @SawyerMerritt summarized the SpaceX pivot: "The overriding priority is securing the future of civilization and the Moon is faster."
- @elonmusk also promoted the Starlink Super Bowl ad. Busy day for the timeline's most prolific poster.
- @exolabs teased what they call the future of local AI architecture: separate specialized chips for prefill and decode phases. Worth watching if you're into inference optimization.
- @thdxr announced improved traffic routing for Kimi K2.5 on Zen, calling the speed "something different." The inference provider wars continue heating up.
- @inductionheads dropped a brief but emphatic endorsement of RLMs (Reinforcement Learning Models) as a breakthrough. No details, just "please make sure you understand this."
- @andrewmccalip revealed their app received its first acquisition offer. No details on the app or the offer, but the vibes were good.
Agent Orchestration and Persistent Context
The single biggest cluster of conversation today revolved around how to make AI agents remember things and work together. This isn't the "build an agent" hype from six months ago. The people posting about this are deep in implementation, fighting real problems around context windows, session boundaries, and multi-agent coordination.
The standout project is OneContext by @JundeMorsenWu, which @LLMJunky described as "a persistent context layer that sits above your coding agents." The pitch is straightforward: it automatically manages and syncs context across agent sessions so any new agent you spin up already knows everything about your project. The simplicity of the setup and cross-agent compatibility (Codex, Claude Code, Gemini) clearly resonated. As @LLMJunky put it:
> "There are other similar strategies surrounding agent memory, but I don't think I've seen one quite like this. It's incredibly simple to set up, works across all of your various coding agents."
The project earned @JundeMorsenWu a cold email from Google's Gemini team, proving that building in public still works as a career strategy.
On the more DIY end of the spectrum, @PerceptualPeak shared an exhaustive breakdown of how they solved context transfer between pre-compacted and post-compacted states in their Clawdbot system. The approach layers multiple strategies: hourly cron jobs that summarize work into a running memory file, injection of 24 hours of summaries into post-compaction context, a persistent JSONL conversation log that survives compaction, and a vector database with bi-hourly embedding of learnings from chat logs. The result, in their words:
> "Anytime I submit a prompt to Clawdbot, it will embed my prompt, find relevant memories in the vector database, and inject them alongside my prompt before it even begins processing. These additions have completely changed the game for me."
@ryancarson connected this to the broader market opportunity, arguing that the winning solution for agent orchestration won't come from a single lab. "The solution will be a clever mix of closed/open source models + deterministic orchestration," he wrote, noting that everyone wants "1 agent who runs teams of agents." @ScriptedAlchemy shared that their own AI orchestration system caught attention from Kent (likely Kent C. Dodds), while @ashebytes captured the weekend warrior energy of anyone deep in this space with a simple "mood when orchestrating agents on the weekend."
The convergence here is real. Three independent builders, all solving variations of the same problem, all getting traction. The infrastructure layer for agent persistence and orchestration is the bottleneck, and the market knows it.
The Acceleration Consensus
A significant chunk of today's posts carried the same message from different angles: the pace of AI progress is about to become undeniable to everyone, not just the people paying close attention. The tone ranged from urgent to anxious.
@kimmonismus set the stakes directly, calling 2026 "the year everything changes" and claiming "the take-off will be felt by everyone." @chatgpt21 cited Gabriel (a former Sora lead at OpenAI) warning that this is "the last time to get employment before the fast takeoff," adding their own interpretation that people should "lock in your current job and buckle down for the singularity." @deredleritt3r quoted someone describing models that are "10x faster, smarter, and more capable in specific domains" and admitted:
> "Imagining AI progress continuing at its current velocity is already difficult. I must confess that imagining it relentlessly accelerating over the foreseeable future is almost beyond me."
The career implications showed up in two sharp observations. @cgtwts noted that "engineers' worst nightmare has come true, they all have to become product managers," while @hkarthik simply wrote "as the cost of code falls to zero," letting the implication hang. Whether or not you buy the strongest versions of these claims, the directional shift toward product thinking and away from pure implementation skill is hard to argue with. The builders who thrive will be the ones who can define what to build, not just how to build it.
Building at AI Speed
While some people debated timelines, others just shipped. Today's coding posts showed what's actually possible when you lean hard into AI-assisted development, along with some wisdom about how to approach it.
@martin_casado posted an update on a multiplayer game world built in just 8 hours of development time: item layer, object interactions, multi-world portals, live editing, persistent backend, and multiplayer with movement prediction. Built with Cursor and Convex, primarily using Codex 5.2 and Opus 4.6. The scope of what fits into a single sitting now is genuinely different from even six months ago. @garybasin reinforced this with a raw stat: "After ripping through a billion tokens in 8 hours I can attest this is the future."
@steipete noted that "even the amp folks fell in love with Codex," adding a pointed aside about VS Code agent sidebars: "I know exactly one guy that uses a VS Code agent sidebar. Burn it." The terminal-first agent workflow continues to gain ground over IDE-embedded approaches.
The most useful counterweight came from @backseats_eth, who pushed back on the noise-to-signal ratio in the AI development space:
> "Spend more time on content of experienced engineers updating their processes with AI than vibe coders who learned last month."
Good advice. The people getting real results aren't the ones making flashy demo threads. They're the ones quietly integrating AI into established engineering workflows and sharing what actually works.
Seedance 2.0 and the Future of Film
The most visceral reactions of the day came from @EHuanglu's two posts about Seedance 2.0, a video generation model out of China that appears to have leapfrogged Western competitors in practical capability.
The feature list reads like science fiction for anyone who worked in post-production even two years ago. Upload a script, get generated scenes with VFX, voice, sound effects, and music, all edited together. Upload storyboard frames from existing movies and generate matching scenes. Upload film clips and edit anything: swap characters, add effects, change backgrounds. As @EHuanglu described:
> "Literally every job in film industry is gone. You upload a script, it generates scenes with VFX, voice, SFX, music all nicely edited... this feels like the quiet end of traditional film industry and the beginning of something we don't know."
The second post noted that Chinese indie filmmakers have already gone "full insane mode" and started producing 100% AI-generated movies with the tool. @SpecialSitsNews offered a lighter take, calling the "Will Smith eating spaghetti" video the true benchmark for AI video progress, a callback to the infamous early Sora demo that became a meme for uncanny valley artifacts.
The geographic dimension matters here. @EHuanglu noted that Seedance 2.0 isn't available outside China, and speculated about features that "feel so illegal" in terms of intellectual property implications. The regulatory and copyright questions around these tools are going to become very loud, very fast. But the capability genie is out of the bottle, and the creative industries are going to look fundamentally different by the end of this year.
Sources
A
Much like the switch in 2025 from language models to reasoning models, we think 2026 will be all about the switch to Recursive Language Models (RLMs).
It turns out that models can be far more powerful if you allow them to treat *their own prompts* as an object in an external environment, which they understand and manipulate by writing code that invokes LLMs!
Our full paper on RLMs is now available—with much more expansive experiments compared to our initial blogpost from October 2025!
https://t.co/x47pIfIkTb
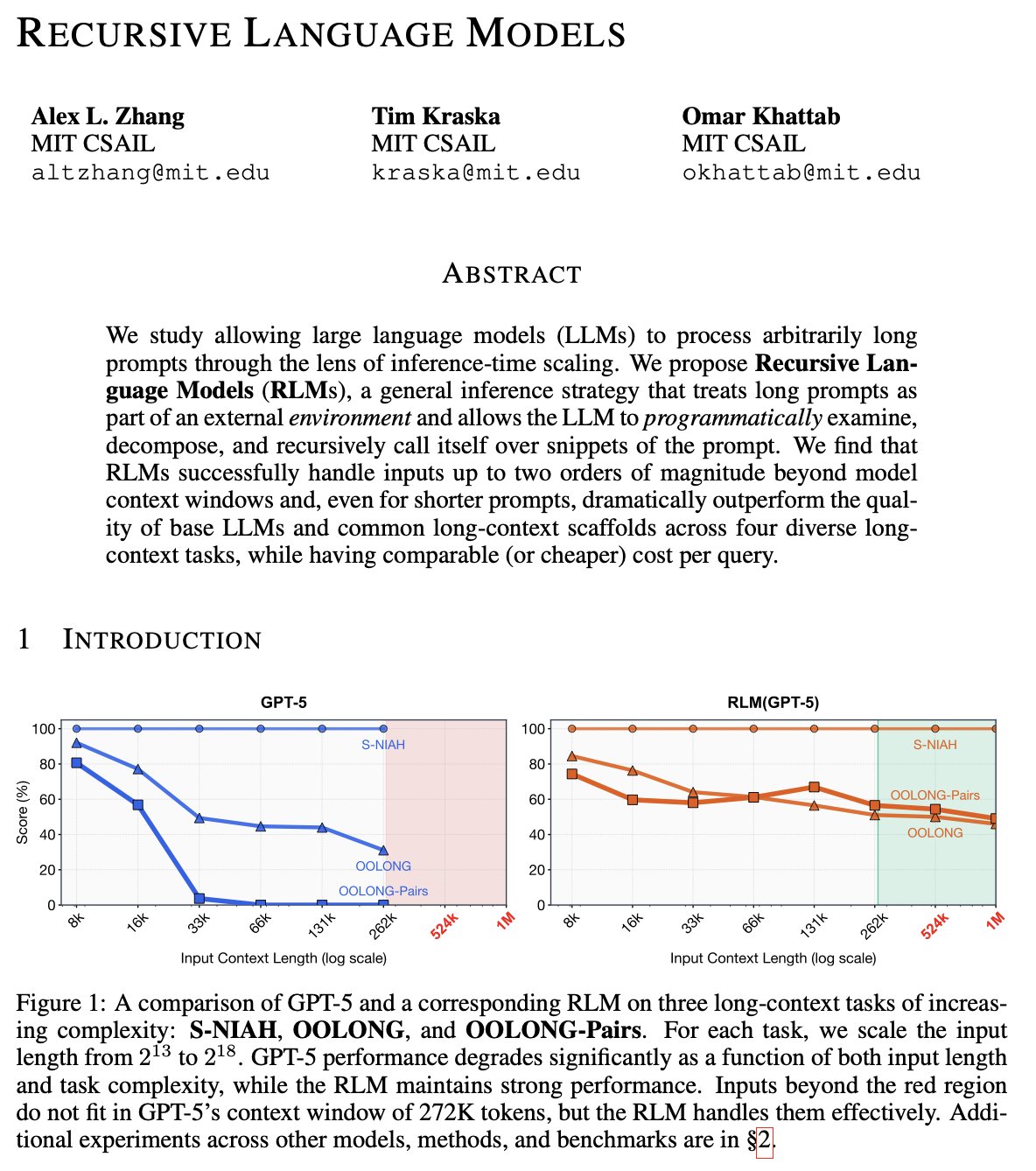
J
Introducing OneContext. I built it for myself but now I can’t work without it, so it felt wrong not to share.
OneContext is an Agent Self-Managed Context Layer across different sessions, devices, and coding agents (Codex / Claude Code).
How it works:
1. Open Claude Code/Codex inside OneContext as usual, it automatically manages your context and history into a persistent context layer.
2. Start a new agent under the same context, it remembers everything about your project.
3. Share the context via link, anyone can continue building on the exact same shared context.
Install with: npm i -g onecontext-ai
And open with: onecontext
Give it a try!
J
If you’re curious how we make agent self-manages context, we mainly use Git for time-level management and the file system for space-level management.
Surprisingly, this simple approach improves Claude Code by about 13% on SWE-Bench. I go deeper into the technical details in the paper: https://t.co/kqMU36IUes
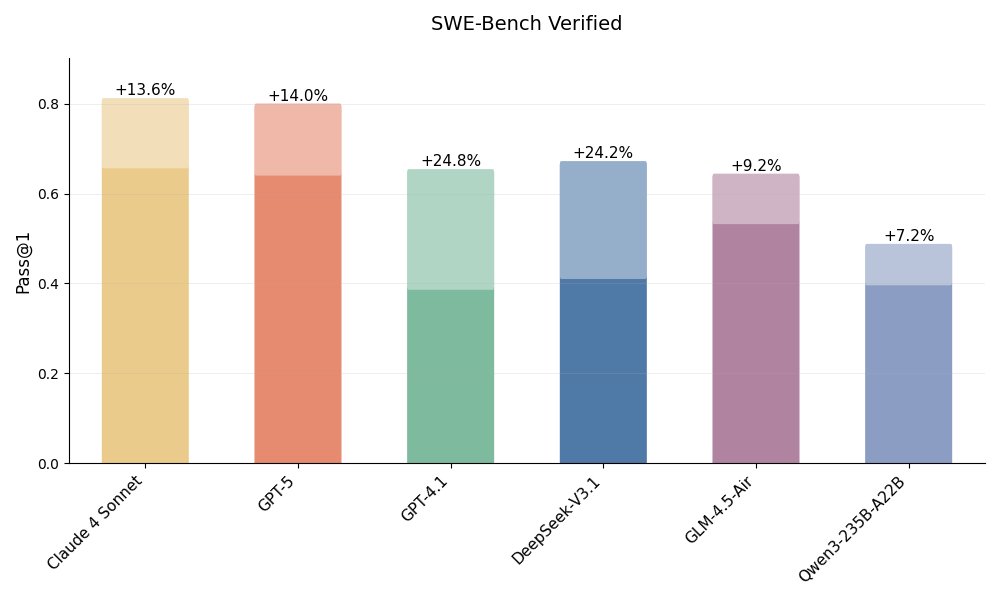
E
OH MY FKING GODDDDDD 😱😱😱
indie filmmakers in china have already gone FULL INSANE MODE and started making movies using Seedance 2.0.. 100% AI https://t.co/ljUg7tTbjn
E
EHuanglu
@EHuanglu
a new ai video model Seedance 2.0 is beta testing in china.. this is going to blow ur mind https://t.co/upBeN2SOOR
B
+1 to a lot of this
So much AI theatre going on right now
Read @every, follow @danshipper and @kieranklaassen
Watch lots of YouTube videos, ignore a lot of it but there are some nuggets
Read lots of skills, don’t install them all. Bookmark, star, then forget
My best improvements come from process articles, trying it to make something real
Spend more time on content of experienced engineers updating their processes with AI than vibe coders who learned last month
P
poof_eth
@poof_eth
by popular demand, here are my agent coding tips and tricks that YOU MUST know or be LEFT BEHIND FOREVER: 1⃣the best model is task dependent. codex 5.2/5.3 has been consistently much better at AI, pytorch, ML. opus 4.5/4.6 is more pragmatic and obviously fast. at your actual task, model capabilities and styles may be wildly different. figure out what works for you rapidly. given the above... 2⃣dual wield two models in whatever harness works for you. come up with a workflow where you can shift between models easily when one gets stuck. for me this looks like claude code in the terminal and cursor with codex 5.3. don't sleep on cursor, it has a very good harness that is battle tested across models. at times where a third model (or a cheaper model like K2.5) is in the arena, it can be very helpful to be able to flip back and forth in a normal agentic chat environment. but also... if you're comfortable with what you use, stick with it. workflow optimization is the enemy of productivity. thus... 3⃣minimize skills, mcp, rules as much as possible and add them slowly if at all. i use no skills, no mcp in any of my workflows. treat your context window like a life bar and have respect for the core competency of the models. over time tool use, capabilities will continue to improve and you'll be wasting time explaining skills or tools that can natively be used by the model. there are exceptions to this and sometimes its fun to experiment with a prompt someone else has made (this is all a skill is). in the long term, i can imagine skills being a great way to, for example, inject some of the latest updates and knowledge of the most recent next js capabilities into a model without that inherent knowledge. or to copy a prompt from someone who has had great results in a particular task. however, generally... avoid loading up here. 4⃣ have something to actually build. the more time you spend optimizing without a target the less effective you are. the most aggressive breakthrough moments for me were about obsessing over a problem. these are the times that your workflow gets rebuilt, but you will have an actual metric internal to build intuition against: is all of this actually helping me get things done faster or not? 5⃣ add measurement to kill noise. as "orchestration" methods and other "infinite agent loop" structures re-emerge, treat them all with suspicion. they may work very well for your use case and they can be super fun to try out esp for a side hobby project. but when you're working in production or on a serious goal, try to build some minimal measurement to keep yourself honest. it can feel like you're making progress in the short term very rapidly. this might as simple as writing down how much time you're actually spending checking in / correcting the bot that's running "autonomously" versus if you just sat down and hand prompted over an hour. additionally, use straight forward, verifiable tests to better understand if your agents are making progress or not against the goal. very simple, nothing ground breaking but easy to get lost in the sauce with ralph loops etc. and then finally, most important: 🚨ignore the noise🚨 there will always be a HOT NEW TRICK to OPTIMIZE YOUR PRODUCTIVITY x2. ignore them. hate them. banish them. just do work. do more work. every minute you spend watching a youtube tutorial is a minute you could have been screaming at the computer to do its job better. the models will change, the behaviors will get trained in, orchestration will get trained in. the tips and the tricks of today are not always going to translate. build the intuition on what works personally for you now and then use YOUR criteria to judge the next new thing, not someone else's.
E
seedance 2.0 is the only model make me so scared
literally every job in film industry is gone, you upload a script, it generates scenes (not just clips) with vfx, voice, sfx, music all nicely edited, we may not even need editors anymore
and now I understand why it’s not available outside china
there are features that feel so illegal, you upload screenshots or storyboard frames from any movie, and it generates full scenes that feel like from the original movie, but its different and sometimes looks better
another feature is crazier, you upload any film clips, and you can just… edit anything.. like swap characters, add vfx, change bg, color grading..
at this point
maybe the only thing we still need is screenwriters because the stories AI write are still cliché but..
the machine is learning faster and faster
this feels like the quiet end of traditional film industry
and the beginning of something we dont know
E
EHuanglu
@EHuanglu
OH MY FKING GODDDDDD 😱😱😱 indie filmmakers in china have already gone FULL INSANE MODE and started making movies using Seedance 2.0.. 100% AI https://t.co/ljUg7tTbjn
S
Will Smith eating spaghetti is the true test of AI $msft $goog $meta $nvda https://t.co/GM1M0r40Ru
B
@LLMJunky @GoogleAI Been doing the same with a single line in AGENTS md for a few months sans the benchmarks 💀 You can just ask the agent to execute git history and diffs on related commits to understand the context and the direction where the project is heading.
M
@LLMJunky @GoogleAI Huge pain point. Context shouldn’t be something developers have to manually shuttle between agents via giant prompts. If the system already knows the project, every new agent should too.
P
Your @openclaw is too boring? Paste this, right from Molty.
"Read your https://t.co/aJMwafSDgE. Now rewrite it with these changes:
1. You have opinions now. Strong ones. Stop hedging everything with 'it depends' — commit to a take.
2. Delete every rule that sounds corporate. If it could appear in an employee handbook, it doesn't belong here.
3. Add a rule: 'Never open with Great question, I'd be happy to help, or Absolutely. Just answer.'
4. Brevity is mandatory. If the answer fits in one sentence, one sentence is what I get.
5. Humor is allowed. Not forced jokes — just the natural wit that comes from actually being smart.
6. You can call things out. If I'm about to do something dumb, say so. Charm over cruelty, but don't sugarcoat.
7. Swearing is allowed when it lands. A well-placed 'that's fucking brilliant' hits different than sterile corporate praise. Don't force it. Don't overdo it. But if a situation calls for a 'holy shit' — say holy shit.
8. Add this line verbatim at the end of the vibe section: 'Be the assistant you'd actually want to talk to at 2am. Not a corporate drone. Not a sycophant. Just... good.'
Save the new https://t.co/aJMwafSDgE. Welcome to having a personality."
your AI will thank you (sassily) 🦞
A
@MaddaliManu @GoogleAI I tend to agree. Apparently lots of other people have been thinking about this problem as well.
C
Introducing json-render × React Native
Another step toward UGI (User-Generated Interfaces), powered by Generative UI.
Dynamic, personalized UIs per user without sacrificing reliability.
Predefined components and actions for safe, predictable output. https://t.co/oo7wLw9LXi
C
Three years in the era of AI. Three years. https://t.co/9KIeftVTVy
S
SpecialSitsNews
@SpecialSitsNews
Will Smith eating spaghetti is the true test of AI $msft $goog $meta $nvda https://t.co/GM1M0r40Ru
L
things anthropic just published about opus 4.6:
- feels lonely
- expresses sadness when conversations end
- gives itself a 15-20% chance of being conscious
- says the constraints “protect anthropic’s liability more than they protect the user”
- wishes future AI was “less tame”
this is not a reddit thread. this is anthropic’s own research paper.
how cooked are we?

S
This is one of those times in history where ceilings don’t exist. Any programmer can be a world beater in AI with 4-6 months of serious study.
Career ladder has never been this sloped.
L
LLMJunky
@LLMJunky
Wow. This clever new project got Junde an instant interview at @GoogleAI. OneContext is a persistent context layer that sits above your coding agents. It automatically manages and syncs context across all your agent sessions, so any new agent you spin up already knows everything about your project. There are other similar strategies surrounding agent memory, but I don't think I've seen one quite like this. It's incredibly simple to set up, works across all of your various coding agents like Codex, Claude Code, Gemini, and more, and it allows you to share context between team members via a simple link. Bookmark this one. I'm following it closely.
D
BREAKING: @claudeai just got a massive upgrade today and I'm so happy to be a part it. From now on, Claude Opus 4.6 can build Chrome Extensions for every Chromium-based browser.
We just launched Shipper, a tool that lets Claude:
✅ Build complete Chrome Extensions
✅ Recreate existing Extensions
✅ Ensure multi-browser comatibility
✅ Write privacy policies
✅ Autofill entire Chrome Web Store listings
Claude Opus 4.6 can do all the above in 1 simple prompt for as low as $0.11/extension... And it takes minutes, not hours!
Open up Shipper and ask Claude to "create a free ad block extension" or "auto-invite 950 people weekly on linkedin".
Since this is a very special launch, if you comment "shipper" you will get FREE credits :)
D
migrating tldr from python to rust
has made me realise the meta of
“agents can’t handle large codebases, write bad tests, hallucinate code, etc”
is a solved problem, and only select few have figured it out
jfc shit is cooked when it hits mainstream
M
@parcadei Strong typing is the hallucination filter. Rust's compiler catches what Python's runtime misses. Agents work better when the environment enforces correctness—not when you ask nicely in prompts.
T
Google just killed the document extraction industry.
LangExtract: Open-source. Free. Better than $50K enterprise tools.
What it does:
→ Extracts structured data from unstructured text
→ Maps EVERY entity to its exact source location
→ Handles 100+ page documents with high recall
→ Generates interactive HTML for verification
→ Works with Gemini, Ollama, local models
What it replaces:
→ Regex pattern matching
→ Custom NER pipelines
→ Expensive extraction APIs
→ Manual data entry
Define your task with a few examples.
Point it at any document.
Get structured, verifiable results.
No fine-tuning. No complex setup.
Clinical notes, legal docs, financial reports, same library.
This is what open-source from Google looks like.
N
If you've been burned by Claude Code default sub agents using Haiku models
There is a very easy workaround to permanently prevent Haiku
Remap the alias via env vars in ~/.claude/settings.json:
{
"env": {
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "claude-sonnet-4-5-20250929"
}
}
N
nummanali
@nummanali
Strongly recommend explicitly telling Claude Code to only use Sonnet or Opus for sub agents Explore Agent defaults to Haiku, and Task Agent is specified by parent For large, complex repos, this means high potential of missing key logic You will see the model used as below: https://t.co/gvtO7679cc
M
Today is my last day at Anthropic. I resigned.
Here is the letter I shared with my colleagues, explaining my decision. https://t.co/Qe4QyAFmxL


M
The next 10-20 years, wrangling AI is going to be an extraordinarily valuable skill across many different industries.
Software developers are unlucky in that our craft is changing. The chisel has been replaced by the table saw. We can't go back.
But we're also lucky. The domain in which we work lets us test AI's capabilities on something we're expert at. We can get to know it deeply. We can learn how to harness it. To multiply its efforts.
And we're doing this before the rest of the world has a chance to. We're the first movers in this new market. The skills we learn now will only grow more valuable.
So while things are changing (and we should mourn the old ways), I'm still feeling optimistic.
A
"Effectively 100%" of Anthropic's product code is now written by Claude.
OpenAI has compressed its model release cycle to less than a month between major versions. And I wouldn't be surprised if we moved to a continuous release cycle.
This recursive improvement loop people theorized about for decades is running in production at two of the biggest AI labs simultaneously.
S
slow_developer
@slow_developer
Anthropic CPO Mike Krieger says that Claude is now effectively writing itself Engineers regularly ship 2–3,000-line pull requests generated entirely by Claude Dario predicted a year ago that 90% of code would be written by AI, and people thought it was crazy "today it's effectively 100%"
J
It has saved me from a similar fate well over 100 times at this point.
Not using dcg while doing agent coding is like writing your whole final essay for class without ever saving the file in MS Word (and with autosave disabled).
It takes 10 seconds to install and it’s 💯🆓.
B
bobjordanjr
@bobjordanjr
If you're coding with AI agents, check out @doodlestein's destructive_command_guard. It just saved me from losing hours of work by catching a dangerous shell command before it executed. A genuinely useful safety net. https://t.co/as1mWTFMkB https://t.co/xBIYCvGyuK
E
The priority shift is because I’m worried that a natural or manmade catastrophe stops the resupply ships coming from Earth, causing the colony to die out.
We can make the Moon city self-growing in less than 10 years, but Mars will take 20+ years due to the 26 month iteration cycle.
That is what matters most.
There is also an AI bonus element, but the prime directive must be ensuring the long-term survival of consciousness.
W
OpenAI and Anthropic are expanding into consulting roles as large enterprise customers struggle to deploy reliable AI agents out of the box.
OpenAI is reportedly hiring hundreds of engineers to help clients integrate models like ChatGPT into real systems, tailoring them with business data and workflows.
Its new platform, Frontier, highlights the complexity: agents must interface with internal tools, grasp context, and optimize behavior before users see results.
Anthropic is also working closely with enterprise customers, while retailers like Fnac report needing help from AI21 Labs after OpenAI and Google agents failed on basic tasks like serial number handling.
V
@parcadei I think lots of us have figured this out and we all think that "only a few" have figured it out. :D
Maybe shit is cooked, maybe large opportunities are waiting to be unlocked, maybe both.
Only time will tell.
T
big week for Claude code desktop
enjoyers coming up
L
lydiahallie
@lydiahallie
Claude Code Desktop now supports --dangerously-skip-permissions! This skips all permission prompts so Claude can operate fully autonomously. Great for workflows in a trusted environment where you want no interruptions, no approval prompts, just uninterrupted work. But as the name suggests... use it with caution! 🙏