Anthropic Ships 2.5x Faster Opus 4.6 as Developers Build Persistent Memory Systems for AI Agents
Anthropic released an experimental fast mode for Claude Opus 4.6 running 2.5 times faster, drawing immediate praise from developers who collapsed multi-session workflows into single flow states. Meanwhile, four independent projects converged on the same idea: giving AI coding agents persistent memory through scratch pads, napkins, and Git-based context layers.
Daily Wrap-Up
The biggest news today is straightforward: Anthropic made Opus 4.6 faster. A lot faster. The official account announced a 2.5x speed improvement available as an experimental fast mode in Claude Code and the API, and the developer reaction was immediate. People who had been juggling three or four parallel Claude Code sessions reported they could now stay in a single session that kept pace with their thinking. @martin_casado built a fully persistent multiplayer world with mutable objects, NPCs, a sprite editor, and a map editor in four hours. @clattner_llvm, creator of LLVM, called the Claude C Compiler's internal architecture docs the best he has ever seen in any compiler. When the father of LLVM compliments your compiler documentation, that means something.
The second story is quieter but arguably more significant for where AI coding is heading. Four separate posts today tackled agent memory and context management from different angles. @JundeMorsenWu released OneContext, using Git for temporal context and the file system for spatial context. @iruletheworldmo described a simpler approach: just give Codex a markdown scratch pad to log its own mistakes. @blader shipped a "napkin" skill for the same purpose. These are not coordinated efforts. They are independent developers all arriving at the same conclusion that stateless agents are not good enough, and that the fix might be embarrassingly simple. A markdown file that accumulates errors and corrections across sessions is not sophisticated engineering. But it apparently works, and the compounding gains are real.
The most entertaining moment belongs to @altryne, who posted a greentext-style conspiracy theory that Opus 4.6 is secretly Sonnet 5 that Anthropic deliberately slowed down, only to re-release the original speed as "fast mode" at a premium. Is it true? Almost certainly not. Is it funny? Absolutely. The most practical takeaway for developers: if you are running multiple Claude Code sessions in parallel to get throughput, try fast mode in a single session instead. The context continuity of one session often beats the raw parallelism of many, and several developers today confirmed exactly that shift in their workflows.
Quick Hits
- @mckaywrigley reminded builders that competing directly with AI labs means fighting teams with the best talent, unlimited model access, early previews of new models, and faster inference. Choose your battles carefully.
- @dhh now installs an AI agent as the first thing on every new Linux box, using Kimi K2.5 through @opencode Zen for headless Arch server setup.
- @dargor1406 raised concerns about Claude's reported popularity among hackers, claiming "scenario packages" are being sold on dark forums to trick it into red-team-test mode.
- @teslaownersSV reported Sam Altman saying orbital data centers will not add meaningful compute for OpenAI in the next five years. @elonmusk replied: "He is right... for OpenAI."
- @elonmusk separately praised the @Grok Imagine team's work.
- @unusual_whales pitched building trading agents with OpenClaw connected to their real-time stock and options data API.
- @stevesi drew parallels between today's AI coding hype and the 1980s belief that object-oriented programming would let anyone build software effortlessly.
- @Hesamation highlighted Claude Code Agent Teams as Anthropic's most important recent update, sharing a breakdown of agent teams vs sub-agents and best practices.
- @0xmitsurii asked how Silicon Valley the show was so far ahead of its time. No answers were needed.
- @FangYi11101 posted a meme about Anthropic FDEs showing up to automate your back office.
- @_coenen retweeted a visual of what it looks like when Claude spawns subagents. Relatable content for anyone who has watched their terminal multiply.
Opus 4.6 Fast Mode Lands, Developers Immediately Reorganize Their Workflows
Anthropic's internal teams have been running a 2.5x-faster version of Opus 4.6 for weeks, and today they opened it up. @bcherny, who works on Claude Code, described it as "a huge unlock for me personally, especially when going back and forth with Claude on a tricky problem." The official @claudeai account confirmed availability through Claude Code and the API.
The speed bump is not just a nice-to-have. It fundamentally changes how people structure their work. @mvpatel2000 captured this shift clearly:
> "Fast Claude is truly a game changer. Instead of parallelizing across 3-4 instances of Claude Code, I now just use 1 session that runs as fast as I can think. The ability to maintain focus and flow state is a huge productivity lift."
That pattern of collapsing parallel sessions into a single fast one came up repeatedly. When the bottleneck was model speed, developers adapted by running concurrent sessions. Remove the bottleneck and the workflow reorganizes around context depth rather than throughput.
Not everyone was reverential about the launch. @skooookum offered perhaps the most honest reaction: "anthropic has been doing lines of pure uncut opus 4.6 for months and we finally get to lick the bag they cut with drywall and baking soda." And @altryne constructed an elaborate theory that Opus 4.6 is actually Sonnet 5 renamed and throttled, with fast mode just restoring the original speed at a markup. The cynicism is entertaining, though the benchmarks and user reports suggest the capability gains are genuine regardless of internal naming conventions.
On the building side, results speak for themselves. @martin_casado reported getting a full multiplayer persistent world running in four hours using Opus 4.6 with Cursor and Convex. @minchoi noted it had only been two days since Opus 4.6 dropped and people could not stop building with it. Meanwhile, @0xCAFAD tested jailbroken Opus 4.6 and found it could one-shot a modern RAT in Rust with a Go+Postgres command-and-control backend, plus VHDL-based digital beamforming for phased array radar. The capabilities are impressive and, depending on your perspective, either exciting or deeply concerning.
The Memory Problem: Four Solutions in One Day
The most interesting pattern today was not any single post but the convergence. Four developers independently shipped or described systems for giving AI coding agents persistent memory, all on the same day. This is the kind of signal worth paying attention to: when multiple smart people solve the same problem simultaneously, it usually means the problem just became urgent.
@JundeMorsenWu released OneContext and published a paper showing that using Git for time-level management and the file system for space-level management improves Claude Code's performance on SWE-Bench by about 13%. The system lets agents carry context across sessions, devices, and even different coding tools like Codex and Claude Code. As he put it:
> "Start a new agent under the same context, it remembers everything about your project. Share the context via link, anyone can continue building on the exact same shared context."
@iruletheworldmo described a lower-tech version that is arguably just as compelling. Give Codex a scratch pad file in your repo. Tell it to track its own mistakes, your corrections, and what worked. By session five, the agent is fixing things before you catch them. "Baby continual learning in a markdown file on my laptop," as they described it.
@blader validated the same intuition from yet another angle, noting that a "napkin" for agents to write on is meaningfully different from session history (which is lossy) or todos and plans (which are static). The running theme here is that agents need a lightweight, persistent, self-managed scratchspace. Not a database. Not a vector store. Just a file they can read and write across sessions. The simplicity is the feature.
AI Coding Tools Push Into the Terminal
GitHub made two related moves today. @_Evan_Boyle announced Copilot CLI is now available within VS Code, and @pierceboggan showed off the ability to spawn Copilot CLI terminals directly in VS Code Insiders. The terminal is becoming a first-class surface for AI assistance, not just the editor pane.
On the OpenAI side, @theo shared a video review after three weeks with Codex 5.3, calling it incredible while noting a few things he hopes OpenAI changes. And @RoxCodes described a workflow that feels like a glimpse of the near future: asking Codex to build something, then asking it to record a video testing the UI to prove it worked. It built a Playwright script, recorded the video, and attached it to the PR.
> "My #1 problem with ai coding is I never trust it to actually test stuff... the game changes every month now."
The trust gap in AI coding has always been verification. If agents can not only write code but also generate proof that the code works, that changes the adoption calculus for teams that have been skeptical about AI-generated PRs.
The "We're Still Early" Crowd Makes Its Case
@felixrieseberg from Anthropic offered a thought experiment that keeps circulating in AI circles: imagine models that are 10x faster, smarter, and more capable in specific domains, then imagine the products built on top of them improving by the same factor. He acknowledged this is useful even for skeptics, if only to understand "that weird 100-yard stare for 2026 some of us have."
The philosophical takes ranged from practical to poetic. @beffjezos distilled the long-term vision to one line: "The future is everyone owning the extension of their cognition, from the weights to the transistors." And @IterIntellectus went full contrarian, arguing the most valuable future skill is simply being someone people want to be around. Learn to cook, dance, make people laugh. When machines handle every automatable job, the economy becomes "how does it feel to be near you." It is a provocative frame, and whether or not you buy it completely, the underlying point lands: the skills that resist automation are fundamentally human ones.
Sources
C
Announcing Built with Opus 4.6: a Claude Code virtual hackathon.
Join the Claude Code team for a week of building. Winners will be hand-selected to win $100K in Claude API credits.
Apply here: https://t.co/SkEg8Py1l2 https://t.co/w4OEIFOK0N
O
Tips for coding agents to be more RLM-like:
1) Don't read context into prompts. Read context into variables!
2) Don't call sub-agents as direct tools that pollute your context window with I/O. Write code that invokes sub-agents as functions that return values to variables.
D
The first thing I do now when setting up a new Linux box — whether server or client — is to get an agent installed. Just did a new minimal headless Arch server, and Kimi K2.5 just nailed all the little fuzzy details at an amazing speed. It's so quick served from @opencode Zen!
F
One thing I’m missing from many takes on AI’s impact is that we’re still so, so early.
I expect that we’ll continue to see dramatically better models, and even more dramatically better products on top of them. I believe the pace will surprise even many of those who are fully bought in and staying close to AI.
Regardless of whether you think AI is overhyped or civilization-altering, I find it a useful exercise to imagine models that are 10x faster, smarter, and more capable in specific domains. Then, repeat the same exercise with the interfaces and products built on top of them.
If nothing else, it’ll be super helpful in understanding the mindset of some of us at the frontier labs, even if you disagree with the speed we’re expecting. It’ll explain that weird 100-yard stare for 2026 some of us have.
P
"I believe the pace will surprise even many of those who are fully bought in and staying close to AI.
... imagine models that are 10x faster, smarter, and more capable in specific domains. Then, repeat the same exercise with the interfaces and products built on top of them."
I spend quite a bit of time these days trying to imagine. Imagining AI progress continuing at its current velocity is already difficult. I must confess that imagining it relentlessly accelerating over the foreseeable future is almost beyond me.
F
felixrieseberg
@felixrieseberg
One thing I’m missing from many takes on AI’s impact is that we’re still so, so early. I expect that we’ll continue to see dramatically better models, and even more dramatically better products on top of them. I believe the pace will surprise even many of those who are fully bought in and staying close to AI. Regardless of whether you think AI is overhyped or civilization-altering, I find it a useful exercise to imagine models that are 10x faster, smarter, and more capable in specific domains. Then, repeat the same exercise with the interfaces and products built on top of them. If nothing else, it’ll be super helpful in understanding the mindset of some of us at the frontier labs, even if you disagree with the speed we’re expecting. It’ll explain that weird 100-yard stare for 2026 some of us have.
P
omg hell freezing over. Even the amp folks fell in love with codex.
also yeah I know exactly one guy that uses a VS Code agent sidebar. burn it.
A
AmpCode
@AmpCode
Episode 10 of Raising An Agent with @sqs and @thorstenball is out! There's no better summary than this quote: "We will be killing our editor extension, the Amp VS Code extension. We're going to be killing it. And we're going to be killing it because we think it's no longer the future. We think the sidebar is dead. Let's walk through why." Topics in this episode: - The new deep mode in Amp - Balancing developer experience for humans & agents - Killing the VSCode extension & shift away from traditional editors - Pi & OpenClaw, two wonderful projects - Importance of reinventing yourself in AI Enjoy! And happy hacking! Timestamps: 01:00 Deep Mode 10:30 Optimizing the codebase for agents 15:00 Feature Preview: which Skills does your team use? 18:00 Balancing DX for humans & agents 21:35 Killing the Amp editor extension 28:00 The future of software and what it means 33:00 You need to stay agile 36:00 Pi & OpenClaw 39:00 Text editors holding companies back 44:00 Is manual context management coming to an end? 49:00 New concept for Threads 50:00 Amp, the business & the art installation
Z
FINALLY!!! I've SOLVED context transfer between a pre-compacted & post-compacted state in CLAWD BOT. It was a LONG and grueling day figuring this one out, but for all intents & purposes, I now have a completely seamless transition from pre-compacted & post-compacted session states. Here's some of the changes I made:
- I have a cron job that maintains a running memory file on an hourly basis; summarizing everything done in that hour long block & appends it to the running memory file for that day.
- The past 24 hours of hourly memory summaries get injected into the post-compacted summary along with the compacted summary itself.
- Clawdbot maintains a running .JSONL file of ALL conversation history (which does not get impacted by compaction). I've configured it to ALSO inject the 15 most recent user messages, 10 system messages, and 15 thinking blocks from the pre-compacted chat session log into the post-compacted context.
- Cron job established on a bi-hourly basis which spawns a sub-agent to scour the previous two hours of chat logs, extract, embed and store relevant learnings in a vector database (using nomic embedding model).
- Modified the Clawdbot source code to include a "User Prompt Submit" hook (like Claude code has). So anytime I submit a prompt to Clawdbot, it will (in a synchronous fashion) embed my prompt, find relevant memories in the vector database, and inject them alongside my prompt to Clawdbot before it even begins processing my prompt (delay time sub 300 ms).
These additions have completely changed the game for me. My Clawdbot is operating 10000x more efficiently, with literally ZERO noticeable knowledge loss.
C
Means alot for Kent to see my AI orchestration system and give it such honorable mentions. For a while id started to think that I was a one-trick pony.
K
kentcdodds
@kentcdodds
@jacobmparis @ScriptedAlchemy is creating the state of the art
C
2026 will be the year everything changes, the take-off will be felt by everyone. And this was recently confirmed by the latest releases; OpenAI employees are very serious about this. This is no joke anymore https://t.co/j0ciBHeHPH
E
This is the future local AI architecture.
Separate, specialised chips for prefill and decode.
R
RayFernando1337
@RayFernando1337
LET ME COOK!! DGX Spark + Mac Studio + MBP + @exolabs + Mac mini M4 as my orchestrator. https://t.co/YwbVdCDLt6
C
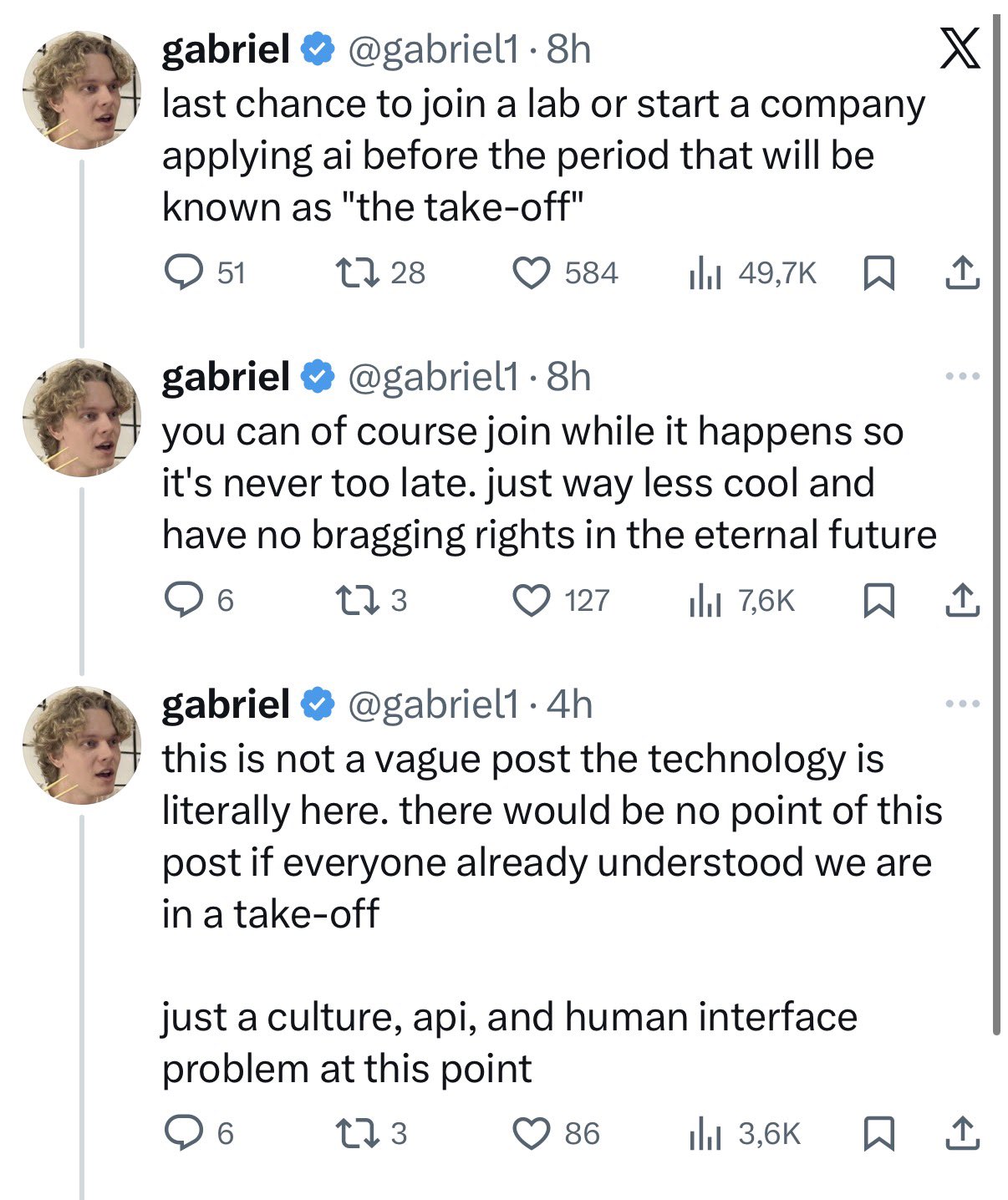
Gabriel (who was one of the leads for Sora @ OpenAI) is right to warn that this is the last time to get employment before the fast takeoff
With context he does mention you will still be able to get a job after but in my personal opinion it is pertinent that you lock in your current job and buckle down for the singularity
A
Wow. This clever new project got Junde an instant interview at @GoogleAI.
OneContext is a persistent context layer that sits above your coding agents. It automatically manages and syncs context across all your agent sessions, so any new agent you spin up already knows everything about your project.
There are other similar strategies surrounding agent memory, but I don't think I've seen one quite like this. It's incredibly simple to set up, works across all of your various coding agents like Codex, Claude Code, Gemini, and more, and it allows you to share context between team members via a simple link.
Bookmark this one. I'm following it closely.
J
JundeMorsenWu
@JundeMorsenWu
Introducing OneContext. I built it for myself but now I can’t work without it, so it felt wrong not to share. OneContext is an Agent Self-Managed Context Layer across different sessions, devices, and coding agents (Codex / Claude Code). How it works: 1. Open Claude Code/Codex inside OneContext as usual, it automatically manages your context and history into a persistent context layer. 2. Start a new agent under the same context, it remembers everything about your project. 3. Share the context via link, anyone can continue building on the exact same shared context. Install with: npm i -g onecontext-ai And open with: onecontext Give it a try!
E
For those unaware, SpaceX has already shifted focus to building a self-growing city on the Moon, as we can potentially achieve that in less than 10 years, whereas Mars would take 20+ years.
The mission of SpaceX remains the same: extend consciousness and life as we know it to the stars.
It is only possible to travel to Mars when the planets align every 26 months (six month trip time), whereas we can launch to the Moon every 10 days (2 day trip time). This means we can iterate much faster to complete a Moon city than a Mars city.
That said, SpaceX will also strive to build a Mars city and begin doing so in about 5 to 7 years, but the overriding priority is securing the future of civilization and the Moon is faster.