Factory AI Ships Agent Readiness Framework as Claude Code Ecosystem Gains Design Canvas, Skills Store, and Visual Debugging
The Claude Code ecosystem saw a burst of new tooling including an infinite design canvas, visual feedback debugger, and a viral 7,500-star guide, while Factory AI formalized how organizations should evaluate their codebases for autonomous development. A skills discovery RFC proposed using .well-known URIs, Prefect launched their MCP governance platform Horizon, and AirLLM made 70B models runnable on 4GB GPUs.
Daily Wrap-Up
January 21st was the day the Claude Code ecosystem stopped being just a coding tool and started looking like a platform. Between Pencil giving agents an infinite design canvas, Agentation providing visual feedback loops, a community skills library crossing 100 entries, and a comprehensive guide racking up 7,500 GitHub stars in under four days, the surface area of what Claude Code can touch expanded dramatically in a single news cycle. Meanwhile, Factory AI dropped their Agent Readiness framework, which felt like the industry's first serious attempt to quantify something everyone has been handwaving about: whether your codebase is actually ready for autonomous agents to work in it.
The other thread worth tracking is the emerging infrastructure for agent skills and context. Cloudflare's @elithrar proposed a .well-known/skills/index.json standard for discovering agent capabilities, and Prefect launched Horizon to turn MCP from a protocol into a governed enterprise platform. These are plumbing moves, not flashy demos, but they signal that the ecosystem is maturing past the "cool hack" phase into something that needs real discovery, distribution, and access control. When the infrastructure layer starts getting serious investment, the application layer is about to get wild.
The most entertaining moment was @esrtweet declaring we're already in the Singularity and it's "screwing up the business planning of everybody in tech," paired perfectly with @hamptonism's meme about driving to your $450k SWE job knowing Claude does everything. But @GergelyOrosz offered the real punchline: inside Big Tech, the internal token usage leaderboard is dominated by distinguished engineers and VPs who rarely coded before LLMs arrived. The most practical takeaway for developers: invest time making your repos agent-ready with pre-commit hooks, documented environment setup, and fast local validation. As @matanSF pointed out, the difference between an agent waiting 10 minutes for CI versus 5 seconds for a local check compounds into hours of wasted cycles.
Quick Hits
- @mehulmpt declared "the end of ed-tech is near," presumably before seeing Google launch free AI-powered SAT practice exams on the same day.
- @__Talley__ made a Polymarket promo video in 30 minutes with 4-5 prompts, adding "video editors are cooked" to the growing list of professions on notice.
- @scaling01 shared that Anthropic is "preparing for the singularity," linking to what appears to be internal planning docs.
- @hamptonism posted the now-classic "driving to your $450k SWE job knowing Claude does everything" meme.
- @GergelyOrosz noted that inside Big Tech, the token usage leaderboard is dominated by distinguished engineers and VPs who rarely coded day-to-day before LLMs.
- @theo pointed to current Claude Code community efforts as what "good devrel looks like in 2026."
- @dweekly worked for a Fortune 100 that called itself "on the frontier of AI" while only 1% of employees had access to any form of it.
- @esrtweet argued we're living inside the Singularity right now, and nobody knows what to build that will still have value in three months.
- @tomosman shared how Clawd.bot is changing their daily workflow.
- @TheRealMcCoy broke down photonic computing: light-based processors that handle matrix multiplications in a single pass, potentially delivering massive speed gains and lower energy use for AI workloads.
The Claude Code Ecosystem Hits Critical Mass
The sheer volume of Claude Code tooling that dropped on a single day suggests the ecosystem has crossed some invisible threshold from "interesting CLI tool" to "platform that spawns its own economy." @tomkrcha launched Pencil, an infinite WebGL design canvas that runs parallel design agents locally, stores files in a git-friendly .pen format, and pipes designs directly into Claude Code for implementation. On the debugging side, @benjitaylor released Agentation, a visual feedback tool where you click elements, add notes, and copy markdown that gives agents element paths, selectors, and positions:
> "I was able to build the entire documentation site solely using Claude Code + Agentation, including all the animated demos." -- @benjitaylor
The Anthropic team themselves revealed the kind of work Claude Code is enabling internally. @trq212 described porting their entire rendering engine, a migration that "could have taken on the order of 1-2 years for a single engineer" and that they "would have never been able to prioritize" without Claude Code. They also surfaced a garbage collection bug in their rendering pipeline that only manifested in certain terminal/OS combinations, a reminder that agent-built software still needs real-world testing across environments.
@affaanmustafa's "Longform Guide to Everything Claude Code" hit 7,500 stars and 1,000 forks in under four days, covering token optimization, memory persistence, verification loops, and subagent orchestration. @simplifyinAI highlighted a new open-source library with 100+ pre-made agents, skills, and templates. And @alexhillman shared a battle-tested pattern that solves a surprisingly basic problem:
> "Claude Code doesn't know what time it is. Or what time zone you are in. So when you do date time operations of ANY kind, things get weird fast. My early solution: use Claude Code hooks to run a bash script that generates current date time, timezone of host device, friendly day of week. Injects it silently into context." -- @alexhillman
@alexhillman also emphasized the value of Claude Code's session transcripts as a source for memory, pattern recognition, and self-generating workflows. @jarredsumner announced that Bun's next version will include --cpu-prof-md, which prints CPU profiles as Markdown so LLMs can read and grep them, a small but telling sign that developer tools are being redesigned with AI consumers as a first-class audience. @jakubkrcmar observed that open-source projects like Clawd.bot are quickly becoming what leading AI companies and startups dream of building, and @paraddox shared the "simplest Ralph loop" for running Claude Code autonomously in a 50-iteration bash loop.
Agent Readiness Becomes a Measurable Framework
Factory AI formalized what's been a growing intuition across the industry: your codebase's readiness for autonomous agents matters as much as the agents themselves. Their Agent Readiness framework scores repositories across eight axes at five maturity levels, giving engineering leaders a concrete rubric instead of vibes. @EnoReyes framed it as an organizational imperative:
> "Agent Readiness is the most essential focus area for a software organization looking to accelerate. As an engineering leader it's your responsibility to start this effort now. Without it, your adoption of AI will actively decelerate your org." -- @EnoReyes
@bentossell distilled it to five words: "all repos should be agent-ready." @matanSF provided the practical evidence, listing how missing pre-commit hooks force agents to wait 10 minutes for CI, undocumented env vars lead to guess-fail loops, and tribal knowledge trapped in Slack means agents can't verify their own work.
The code review conversation ran parallel and complementary. @ScottWu46 from Devin argued that until you can confidently hit "Merge" on a 5,000-line agent PR, you're still bottlenecked on reviewing code yourself, and that an AI-powered review UX making you 5x faster beats an arms-length bug catcher at 80% accuracy. @walden_yan echoed this, noting "it felt pretty slop to say AI will review the code that it wrote" and focusing instead on helping humans understand what they're merging. @steveruizok offered the most creative approach: asking Claude to reimplement the PR on a new branch with "a narratively optimized perfect git history." These perspectives converge on the same insight: the bottleneck has shifted from writing code to understanding and validating it.
Skills Discovery Gets a Standards Proposal
Cloudflare's @elithrar proposed using the .well-known URI standard for agent skill discovery, publishing an RFC for a /.well-known/skills/index.json endpoint that agents can hit to find relevant capabilities. Instead of hunting through repos, docs, or separate skill registries, agents would have a standardized discovery mechanism. @elithrar was careful to note this isn't premature standardization: "I don't consider an RFC a standard. Big on the 'C' here!"
@jlowin announced Prefect Horizon, positioning it as the "context layer" where AI agents interface with business systems. Built on FastMCP (now at a million downloads a day), Horizon adds managed hosting, a central registry, role-based access control down to the tool level, and audit logging. @LLMJunky demonstrated what mature skills look like in practice, generating a complete flash promo video from a single prompt using a CodexSkills skill, calling the result "cracked."
Building Agents That Actually Work
@pauldix declared verification loops "the superpower for 2026," arguing that agents will build all the software if you give them context and tools to verify and iterate. @alexhillman offered a concrete pattern for making this work:
> "If you ask your AI assistant more questions than it asks you, you're gonna have a bad time. The real magic is combining confidence scoring with interviewing workflows. Effectively 'if you're not above X confidence threshold, stop and use this interview workflow until you're above that threshold' solves a wide swath of problems." -- @alexhillman
@rezzz extended this by describing how they had Claude interview them about ergonomics, fears, preferences, and working style so the system adapts to the human rather than the reverse. @Abhigyawangoo offered the counterpoint with "why your AI agents still don't work," a useful reality check as the hype cycle intensifies.
Models, Voice, and Running Big Models Small
NVIDIA released PersonaPlex-7B, a full-duplex conversational model that can listen and speak simultaneously using a dual-stream transformer. @DataChaz highlighted that it enables instant back-channel responses and interruptions that feel human, with fully zero-shot persona control. It's open-source under MIT, which matters for anyone building low-latency voice agents.
On the inference side, @LiorOnAI covered AirLLM's approach to running 70B models on 4GB VRAM by loading one layer at a time: load, compute, free, repeat. It can even run Llama 3.1 405B on 8GB VRAM, no quantization required by default. @AnthropicAI published a new constitution for Claude, describing it as "written primarily for Claude, and used directly in our training process."
Products and Browser Infrastructure
@usekernel launched Browser Pools, providing instant browsers pre-loaded with logins, cookies, and extensions that agents depend on. @rfgarcia spelled out the use cases: spinning up browsers for parallel QA, running large-scale evals on browser agents, and giving fleets of subagents different research tasks without paying for standby CPU time.
@Google launched full-length SAT practice exams in Gemini, grounded in content from The Princeton Review, with immediate AI feedback. @theworldlabs opened their World API for building. @Zai_org highlighted GLM Coding Plans paired with Kilo Code, focusing on the practical question of how much real work you can do without worrying about limits or cost rather than chasing the smartest model.
Sources
M
Cursor vs claude code at 200$ / month
Peyton just posted that cursor gives you ~500$ worth of usage
After extensive testing I found that claude code gives you ~3200$ in API costs
For 1$ in Cursor you get $2.5 or $16 in Claude.
And people still think they're comparable lol https://t.co/dLAQQr1UHJ

W
Fork and host your own via the repo
https://t.co/gK3g1tjiMY
W
Now you can track your @opencode and @claudeai CLI coding sessions in one place.
https://t.co/FLe8dRC8Pv provides searchable history, markdown export, and eval-ready datasets.
See tool usage, token spend, and session activity across projects.
Check out the demo. https://t.co/HGlZOOyugN
T
If you’re wondering what good “devrel” looks like in 2026, it’s this
W
waynesutton
@waynesutton
Now you can track your @opencode and @claudeai CLI coding sessions in one place. https://t.co/FLe8dRC8Pv provides searchable history, markdown export, and eval-ready datasets. See tool usage, token spend, and session activity across projects. Check out the demo. https://t.co/HGlZOOyugN
Z
Amazing blog from @kilocode 👇
"The real question isn’t 'what’s the smartest model?' It’s 'how much real work can I get done without constantly worrying about limits or cost?'
That’s the gap GLM Coding Plans are meant to fill, especially when paired with Kilo Code."
https://t.co/7C6oqCnNkD
G
We’re launching full-length, on demand practice exams for standardized tests in @GeminiApp, starting with the SAT, available now at no cost.
Practice SATs are grounded in rigorously vetted content in partnership with @ThePrincetonRev, and Gemini will provide immediate feedback highlighting where you excelled and where you might need to study more.
To try it out, tell Gemini, “I want to take a practice SAT test.”
J
Every company will have a context layer.
Today, we're launching Prefect Horizon to make that possible.
The context layer is where AI agents interface with your business. It's where teams expose their proprietary data, tools, and workflows to autonomous systems. It’s where you define what agents can see and do, and where you curate and distribute the context that makes automation useful and safe.
We know what this requires because we created FastMCP, the standard framework for working with the Model Context Protocol. We've watched it grow to a million downloads a day.
But we've also seen the protocol's limits. MCP describes how to *build* a server, not how to govern it at scale. It doesn't tell you how to deploy it, secure it, or share it with 5,000 colleagues.
We built Prefect Horizon to turn MCP from a protocol into a platform:
🚀 Horizon Deploy: Managed MCP hosting that gets you from PR to governed endpoint in 60 seconds.
📚 Horizon Registry: A central catalog for all your MCP servers, including first-party, third-party, and our new remix servers that compose multiple sources together.
🔐 Horizon Gateway: The control plane enterprises need: role-based access control down to the tool level, audit logs, and usage visibility.
💬 Horizon Agents: The last mile. Give business users an agentic interface to your company without ever knowing what "MCP" is.
This is automation for the context era.
Welcome to Horizon.

T
Excited to launch Pencil
INFINITE DESIGN CANVAS for Claude Code
> Superfast WebGL canvas, fully editable, running parallel design agents
> Runs locally with Claude Code → turn designs into code
> Design files live in your git repo → Open json-based .pen format https://t.co/UcnjtS99eF
E
Agent Readiness is the most essential focus area for a software organization looking to accelerate. As an engineering leader it’s your responsibility to start this effort now.
Without it, your adoption of AI will actively decelerate your org. Very important to get right!
F
FactoryAI
@FactoryAI
Introducing Agent Readiness. AI coding agents are only as effective as the environment in which they operate. Agent Readiness is a framework to measure how well a repository supports autonomous development. Scores across eight axes place each repo at one of five maturity levels. https://t.co/9POPIY3hXr
W
Start building with the World API today:
https://t.co/vGQ0MfDfYT
W
What do we actually need to review code 10x faster?
It felt pretty slop to say AI will review the code that it wrote. The key is going to be helping the HUMAN understand what they’re merging.
So we built a new interface for this
C
cognition
@cognition
Meet Devin Review: a reimagined interface for understanding complex PRs. Code review tools today don’t actually make it easier to read code. Devin Review builds your comprehension and helps you stop slop. Try without an account: https://t.co/Zzu1a3gfKF More below 👇 https://t.co/sYQLjwSk6s
M
The end of ed-tech is near
G
Google
@Google
We’re launching full-length, on demand practice exams for standardized tests in @GeminiApp, starting with the SAT, available now at no cost. Practice SATs are grounded in rigorously vetted content in partnership with @ThePrincetonRev, and Gemini will provide immediate feedback highlighting where you excelled and where you might need to study more. To try it out, tell Gemini, “I want to take a practice SAT test.”
B
Introducing Agentation: a visual feedback tool for agents. Available now: ~npm i agentation
Click elements, add notes, copy markdown. Your agent gets element paths, selectors, positions, and everything else it needs to find and fix things.
Link to full docs below ↓ https://t.co/o65U5MY7V6
B
I was able to build the entire documentation site solely using Claude Code + Agentation, including all the animated demos. Check out the full docs here: https://t.co/FRyZMEQn5Y
B
@aulneau yep! https://t.co/NxZpaJpG0V
A
@benjitaylor https://t.co/RfXiI0Dpkz
C
I got this 25-slide Stardew Valley style PPT in just one shot, made with Kimi Slides.
My prompt:
Generate a 25-slide "Project Annual Operations Report" PPT based on the Stardew Valley aesthetic.
Requirements: Frame business growth as "farm expansion" and customer acquisition as "Community Center restoration progress."
Style: 16-bit pixel art; use seasonal landscapes (Spring, Summer, Fall, Winter) as slide backdrops. Icons should include energy bars (for budget), skill levels (for team capacity), and Pierre’s General Store-styled data tables.
N
The literal first innovators of agents using browsers has released their own browser use CLI
My money is on this, I’m switching to it and using it as my main driver
G
gregpr07
@gregpr07
Introducing: Browser Use CLI + Skill (100% OSS)👀 Give your Claude Code/Codex agent a browser. Perfect for local dev🧙 "go to localhost:3000, tell me what's wrong with the UI and keep improving it until it looks pretty". It just works. Works with: ✅ Headless (fast) ✅ Your real Chrome (with logins) ✅ Cloud browsers (proxies + anti-detection) 2-line skill install. Link below ↓
S
AGI is now on the horizon and it will deeply transform many things, including the economy.
I'm currently looking to hire a Senior Economist, reporting directly to me, to lead a small team investigating post-AGI economics.
Job spec and application here: https://t.co/VAfwrMc8Tp
🍓
google are preparing for agi. is one of many agi or post agi roles.
this is coming quickly.
S
ShaneLegg
@ShaneLegg
AGI is now on the horizon and it will deeply transform many things, including the economy. I'm currently looking to hire a Senior Economist, reporting directly to me, to lead a small team investigating post-AGI economics. Job spec and application here: https://t.co/VAfwrMc8Tp
S
We're launching a new series of Agent Skills focused on Postgres Best Practices 🤖
These skills will empower your AI coding agent to produce top-notch, accurate code effortlessly
Try it out: https://t.co/bLbgnWElwL https://t.co/zY44ifHRuv

G
The GitHub Copilot SDK is here 🙌
You can take the same Copilot agentic core that powers GitHub Copilot CLI and embed it in any application, with just a few lines of code.
https://t.co/2XcdaqWdMT https://t.co/DCaF6vyYRQ

C
i thought this was a SaaS, it's not, it's an open-source package you can "npm install" to any project of yours
this is genius, i will be using this in every project going forward
B
benjitaylor
@benjitaylor
Introducing Agentation: a visual feedback tool for agents. Available now: ~npm i agentation Click elements, add notes, copy markdown. Your agent gets element paths, selectors, positions, and everything else it needs to find and fix things. Link to full docs below ↓ https://t.co/o65U5MY7V6
E
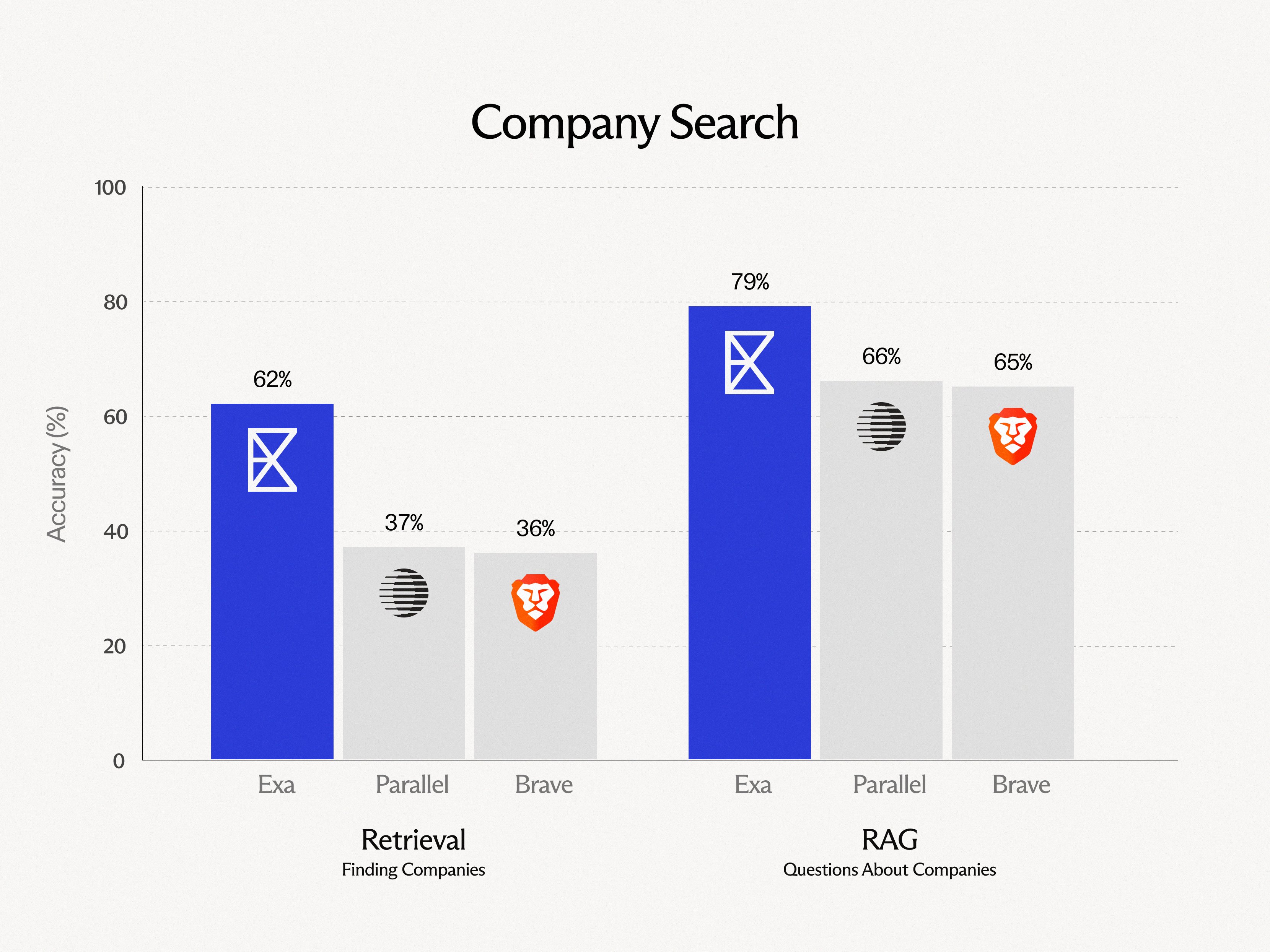
Introducing the most powerful company search:
You can now semantically search over 60M+ companies and get structured information on each (web traffic, headcount, financials, and more).
Try it: https://t.co/cQ6UlWHnKY https://t.co/TrTdeFUfr6
E
Try it with Claude skill: https://t.co/2oGcgiklB7
Company search eval: https://t.co/WvuImtsCtY
D
ELON MUSK: "In the future, the robots will make so many robots, that they will actually saturate all human needs, meaning you won't be able to even think of something to ask the robot for at a certain point, like there will be such an abundance of goods and services. There'll be more robots than people. I think everyone on earth is going to have one humanoid robot because you would want a robot to watch over your kids, take care of your pet, take care of elderly parents.
I'm very optimistic about the future. I think we're headed for a future of amazing abundance, which is very cool. Definitely we are in the most interesting time in history."
P
Introducing Figma Connect.
The best way to turn your Figma designs into code.
No MCP hell. No plugins.
Just copy and paste your designs into MagicPath and turn them into interactive prototypes without compromising your craft.
Every pixel. Every detail. Every asset. Preserved. https://t.co/m88d1CvRPO
P
You spent hours perfecting those pixels in Figma.
We care about that.
Your design becomes a living prototype you can:
• Edit with AI using your design system
• Share as interactive links
• Export as production ready code
Your precision, plus the magic of MagicPath. https://t.co/yHm8Z3NgEg
P
To start:
1) Open any project and click Import from Figma, or start from the landing page
2) Connect your Figma account.
3) Copy any design with ⌘L on Mac or Ctrl + L on Windows
4) Paste it into MagicPath with ⌘V
Images, typography, colors, and layout are all preserved. https://t.co/M7klueIQqI
P
Figma Connect is now live. Try it and turn your designs into real, interactive prototypes in seconds.
Design to code, it's now solved.
Learn more: https://t.co/WEoQBbiwai
V
self driving is solved. AGI is here. humanoid robots entering production, nuclear fusion finally working, the food pyramid being rebuilt from scratch, fatness curable, BCIs restoring movement and sight, CRISPR editing diseases out of the germline, cancer becoming manageable, private companies building moon landers, longevity approaching escape velocity
i think we're going to be fine
C
2/3: Claude’s ExitPlanMode output schema now includes `launchSwarm` and `teammateCount`, enabling Claude to request spawning a multi-agent swarm to implement an approved plan instead of only optionally pushing the plan to a remote session.
Diff: https://t.co/ClOJXNpRdg https://t.co/tSFBtllkz0
C
3/3: Claude can now configure spawned Task agents more precisely: `name` for agent naming, `team_name` to spawn within a chosen team context, and `mode` (e.g., `plan`, `delegate`, `bypassPermissions`) to control permission/approval behavior for the teammate.
Diff: https://t.co/HkcvTuLVJM
C
Agents can now ask clarifying questions in any conversation without pausing their work. https://t.co/ZNTldUHUPI
R
The context you build here is powerful for getting high quality output from your agents.
C
cursor_ai
@cursor_ai
Agents can now ask clarifying questions in any conversation without pausing their work. https://t.co/ZNTldUHUPI
M
The sprite model really feels like the future.
Basically full linux environments running an AI agent. Full persistent with checkpoints. No need for git. Spin up as many as you want. Just little AI compute gremlins in the cloud.
https://t.co/YQDHXgX81T
A
what https://t.co/Ra7FEJg3VT has been for some time (except we do snapshots + git, which is still needed let's be real)
interestingly we tried building it on https://t.co/9jrzeTz38k like sprite does but it ended up being quite limited:
too expensive for how much compute you get
must access via http instead of just having an ip like on a VPS
cannot run docker inside it without a massive headache
cannot run a desktop display + streaming without a headache
so instead we wrapped Hetzner VPSs
soon we want to wrap cloud mac minis and windows+GPUs
so many usecases beyond linux & beyond the terminal with desktop agents
wonder if you'd find it interesting
🍓
openai will drop gpt 5.3 next week and it's a very strong model. much more capable than claude opus, much cheaper, much quicker.
there'll also be a ton of upgrades to codex, stay tuned cats.